MambaByte: Token-free Selective State Space Model
2401.13660
4
0

Abstract
Token-free language models learn directly from raw bytes and remove the inductive bias of subword tokenization. Operating on bytes, however, results in significantly longer sequences. In this setting, standard autoregressive Transformers scale poorly as the effective memory required grows with sequence length. The recent development of the Mamba state space model (SSM) offers an appealing alternative approach with a fixed-sized memory state and efficient decoding. We propose MambaByte, a token-free adaptation of the Mamba SSM trained autoregressively on byte sequences. In terms of modeling, we show MambaByte to be competitive with, and even to outperform, state-of-the-art subword Transformers on language modeling tasks while maintaining the benefits of token-free language models, such as robustness to noise. In terms of efficiency, we develop an adaptation of speculative decoding with tokenized drafting and byte-level verification. This results in a $2.6times$ inference speedup to the standard MambaByte implementation, showing similar decoding efficiency as the subword Mamba. These findings establish the viability of SSMs in enabling token-free language modeling.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a new model called "MambaByte" that uses a token-free selective state space approach for sequence modeling.
- The model aims to improve upon previous selective state space models by eliminating the need for tokens, which can be computationally expensive.
- Key innovations include a parallel scan technique for linear recurrences and a selective state space architecture that adaptively selects the most relevant states.
Plain English Explanation
The paper describes a new way of modeling sequences of data, such as text, using a technique called "selective state space modeling." This approach tries to capture the underlying patterns and structure in the data, without relying on individual tokens or symbols.
The main idea is to build a model that can efficiently represent the most important aspects of the sequence, rather than trying to memorize every single element. This is achieved by adaptively selecting the relevant "states" of the sequence, based on the data itself, rather than using a fixed set of tokens or symbols.
To make this work, the researchers developed a parallel scan technique that allows the model to quickly compute certain mathematical operations needed for the selective state space approach. This makes the overall system more computationally efficient compared to previous models that relied on tokens.
The key benefits of this token-free selective state space approach are that it can better capture the high-level structure of sequences, while also being more scalable and efficient to train and run. This could lead to improvements in applications like language modeling, speech recognition, and other sequence-based tasks.
Technical Explanation
The paper introduces a new model called "MambaByte" that uses a selective state space approach for sequence modeling. The core idea is to adaptively select the most relevant "states" of the sequence, rather than relying on a fixed set of tokens or symbols.
A key technical innovation is the use of parallel scans for computing linear recurrences, which are essential operations in the selective state space framework. The authors develop efficient parallel algorithms that allow these computations to be performed much faster than traditional sequential approaches.
The selective state space architecture works by maintaining a set of hidden states that represent important patterns in the input sequence. These states are selectively updated based on the current input, allowing the model to focus on the most relevant aspects of the data. This contrasts with token-based models that treat each element independently.
Experiments on language modeling and other sequence tasks demonstrate the advantages of the MambaByte approach. It achieves strong empirical performance while being more computationally efficient than previous selective state space models that require explicit tokens.
Critical Analysis
The paper presents a compelling new approach to sequence modeling that addresses some key limitations of token-based models. By eliminating the need for tokens, the MambaByte model can better capture high-level structure and patterns in the data.
However, the paper does not extensively explore the model's robustness to noisy or adversarial inputs, nor does it compare its performance to other advanced sequence models like transformers. Further research would be needed to fully assess the model's capabilities and understand its strengths and weaknesses compared to alternative approaches.
Additionally, the parallel scan techniques, while efficient, rely on specific mathematical properties that may not generalize to all types of sequences. It would be valuable to investigate the broader applicability of these techniques and explore ways to further improve the computational efficiency of the selective state space framework.
Overall, the MambaByte model represents an interesting and promising direction in sequence modeling research. The authors have demonstrated the potential benefits of a token-free, adaptive approach, and their work opens up new avenues for exploring more efficient and structured ways of representing sequential data.
Conclusion
The MambaByte model presented in this paper introduces a novel token-free selective state space approach to sequence modeling. By adaptively selecting the most relevant states of the input sequence, rather than relying on fixed tokens, the model can better capture the underlying structure and patterns in the data.
The key technical innovations, including the parallel scan techniques for linear recurrences, make the MambaByte model more computationally efficient than previous selective state space models. This could lead to improved performance and scalability in applications like language modeling, speech recognition, and other sequence-based tasks.
While the paper demonstrates promising results, further research is needed to fully assess the model's capabilities, robustness, and scalability. Exploring the broader applicability of the parallel scan techniques and comparing the MambaByte approach to other advanced sequence models would be valuable next steps.
Overall, the MambaByte model represents an interesting and potentially impactful contribution to the field of sequence modeling, with the potential to inspire new directions in efficient, structure-aware approaches to working with sequential data.
Related Papers
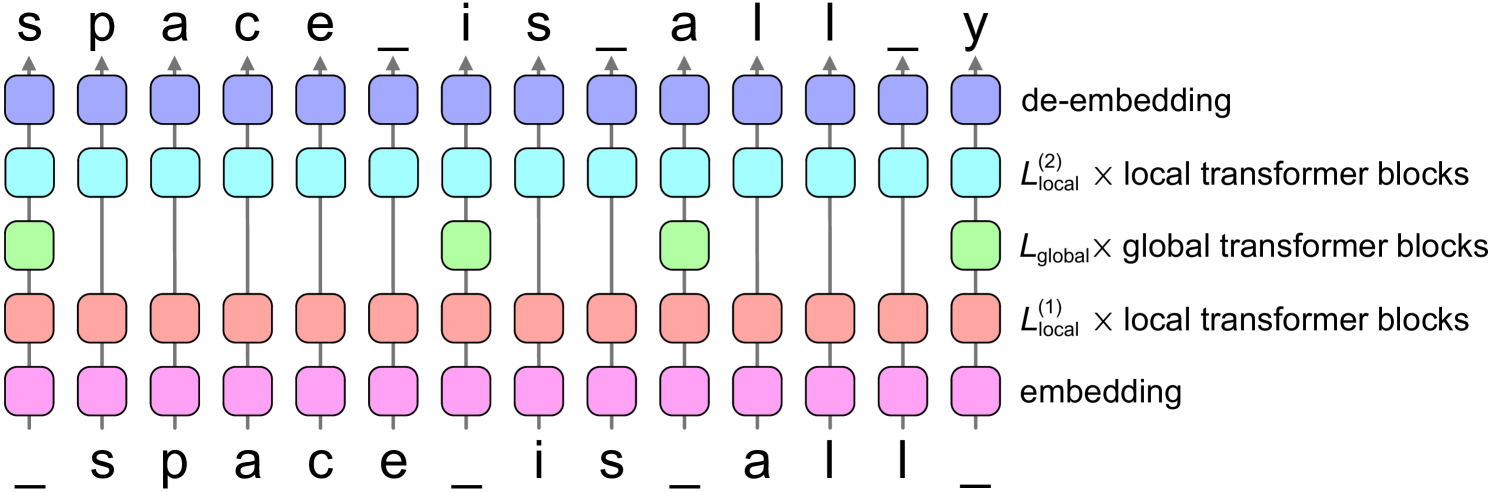
SpaceByte: Towards Deleting Tokenization from Large Language Modeling
Kevin Slagle
0
0
Tokenization is widely used in large language models because it significantly improves performance. However, tokenization imposes several disadvantages, such as performance biases, increased adversarial vulnerability, decreased character-level modeling performance, and increased modeling complexity. To address these disadvantages without sacrificing performance, we propose SpaceByte, a novel byte-level decoder architecture that closes the performance gap between byte-level and subword autoregressive language modeling. SpaceByte consists of a byte-level Transformer model, but with extra larger transformer blocks inserted in the middle of the layers. We find that performance is significantly improved by applying these larger blocks only after certain bytes, such as space characters, which typically denote word boundaries. Our experiments show that for a fixed training and inference compute budget, SpaceByte outperforms other byte-level architectures and roughly matches the performance of tokenized Transformer architectures.
4/23/2024
🤿
Mamba-360: Survey of State Space Models as Transformer Alternative for Long Sequence Modelling: Methods, Applications, and Challenges
Badri Narayana Patro, Vijay Srinivas Agneeswaran
0
0
Sequence modeling is a crucial area across various domains, including Natural Language Processing (NLP), speech recognition, time series forecasting, music generation, and bioinformatics. Recurrent Neural Networks (RNNs) and Long Short Term Memory Networks (LSTMs) have historically dominated sequence modeling tasks like Machine Translation, Named Entity Recognition (NER), etc. However, the advancement of transformers has led to a shift in this paradigm, given their superior performance. Yet, transformers suffer from $O(N^2)$ attention complexity and challenges in handling inductive bias. Several variations have been proposed to address these issues which use spectral networks or convolutions and have performed well on a range of tasks. However, they still have difficulty in dealing with long sequences. State Space Models(SSMs) have emerged as promising alternatives for sequence modeling paradigms in this context, especially with the advent of S4 and its variants, such as S4nd, Hippo, Hyena, Diagnol State Spaces (DSS), Gated State Spaces (GSS), Linear Recurrent Unit (LRU), Liquid-S4, Mamba, etc. In this survey, we categorize the foundational SSMs based on three paradigms namely, Gating architectures, Structural architectures, and Recurrent architectures. This survey also highlights diverse applications of SSMs across domains such as vision, video, audio, speech, language (especially long sequence modeling), medical (including genomics), chemical (like drug design), recommendation systems, and time series analysis, including tabular data. Moreover, we consolidate the performance of SSMs on benchmark datasets like Long Range Arena (LRA), WikiText, Glue, Pile, ImageNet, Kinetics-400, sstv2, as well as video datasets such as Breakfast, COIN, LVU, and various time series datasets. The project page for Mamba-360 work is available on this webpage.url{https://github.com/badripatro/mamba360}.
4/26/2024
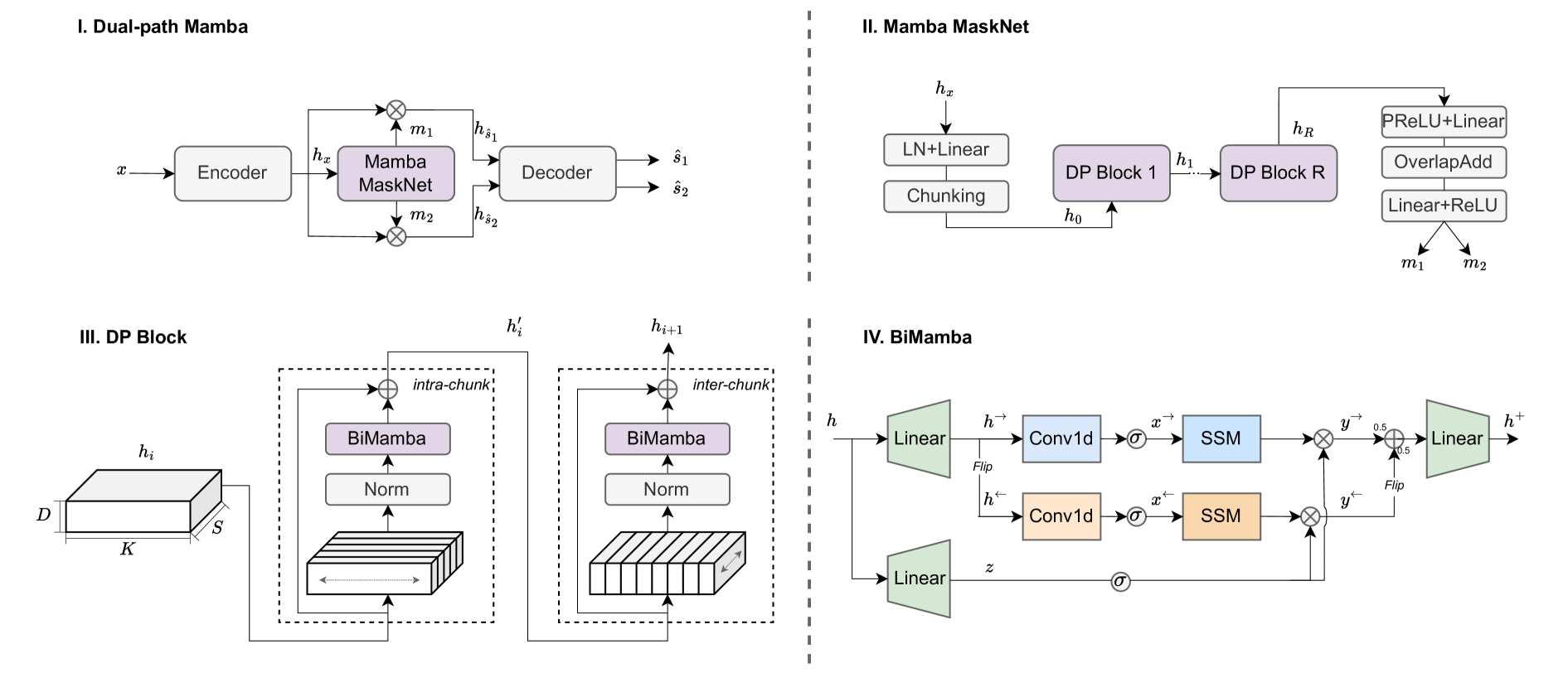
Dual-path Mamba: Short and Long-term Bidirectional Selective Structured State Space Models for Speech Separation
Xilin Jiang, Cong Han, Nima Mesgarani
0
0
Transformers have been the most successful architecture for various speech modeling tasks, including speech separation. However, the self-attention mechanism in transformers with quadratic complexity is inefficient in computation and memory. Recent models incorporate new layers and modules along with transformers for better performance but also introduce extra model complexity. In this work, we replace transformers with Mamba, a selective state space model, for speech separation. We propose dual-path Mamba, which models short-term and long-term forward and backward dependency of speech signals using selective state spaces. Our experimental results on the WSJ0-2mix data show that our dual-path Mamba models of comparably smaller sizes outperform state-of-the-art RNN model DPRNN, CNN model WaveSplit, and transformer model Sepformer. Code: https://github.com/xi-j/Mamba-TasNet
5/2/2024
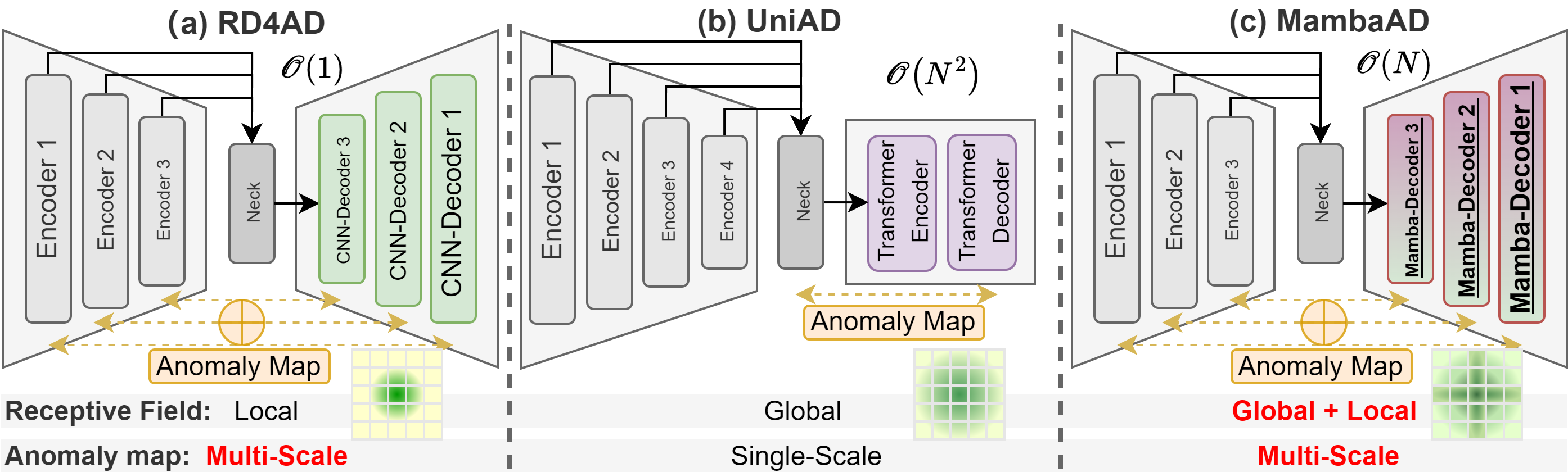
MambaAD: Exploring State Space Models for Multi-class Unsupervised Anomaly Detection
Haoyang He, Yuhu Bai, Jiangning Zhang, Qingdong He, Hongxu Chen, Zhenye Gan, Chengjie Wang, Xiangtai Li, Guanzhong Tian, Lei Xie
0
0
Recent advancements in anomaly detection have seen the efficacy of CNN- and transformer-based approaches. However, CNNs struggle with long-range dependencies, while transformers are burdened by quadratic computational complexity. Mamba-based models, with their superior long-range modeling and linear efficiency, have garnered substantial attention. This study pioneers the application of Mamba to multi-class unsupervised anomaly detection, presenting MambaAD, which consists of a pre-trained encoder and a Mamba decoder featuring (Locality-Enhanced State Space) LSS modules at multi-scales. The proposed LSS module, integrating parallel cascaded (Hybrid State Space) HSS blocks and multi-kernel convolutions operations, effectively captures both long-range and local information. The HSS block, utilizing (Hybrid Scanning) HS encoders, encodes feature maps into five scanning methods and eight directions, thereby strengthening global connections through the (State Space Model) SSM. The use of Hilbert scanning and eight directions significantly improves feature sequence modeling. Comprehensive experiments on six diverse anomaly detection datasets and seven metrics demonstrate state-of-the-art performance, substantiating the method's effectiveness.
4/16/2024