SpaceByte: Towards Deleting Tokenization from Large Language Modeling
2404.14408
7
0
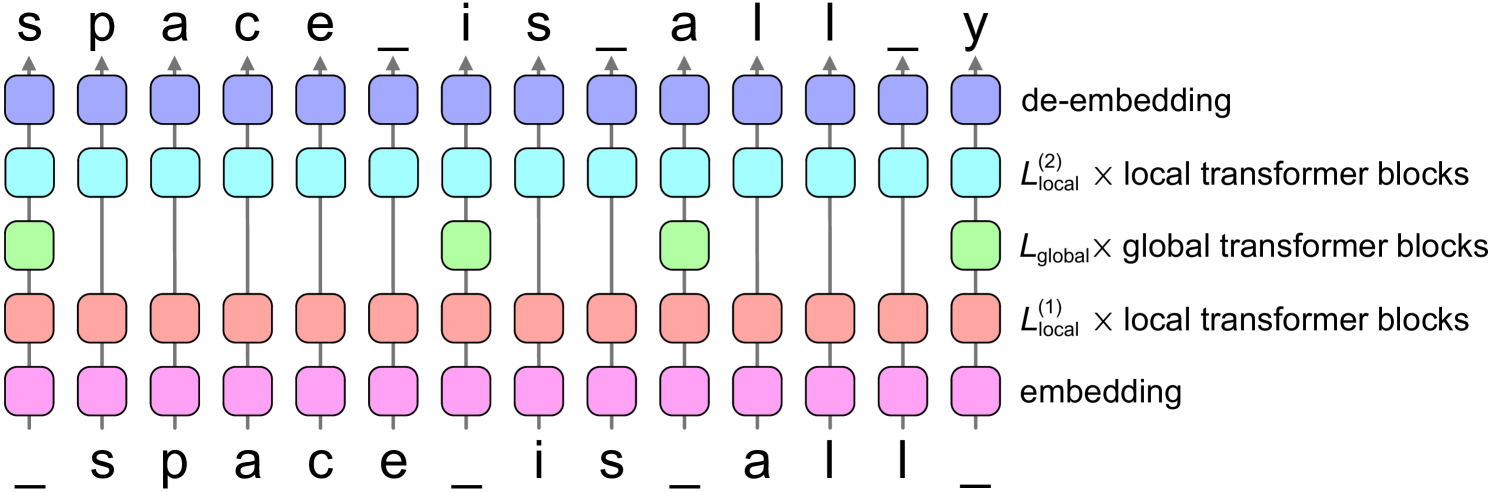
Abstract
Tokenization is widely used in large language models because it significantly improves performance. However, tokenization imposes several disadvantages, such as performance biases, increased adversarial vulnerability, decreased character-level modeling performance, and increased modeling complexity. To address these disadvantages without sacrificing performance, we propose SpaceByte, a novel byte-level decoder architecture that closes the performance gap between byte-level and subword autoregressive language modeling. SpaceByte consists of a byte-level Transformer model, but with extra larger transformer blocks inserted in the middle of the layers. We find that performance is significantly improved by applying these larger blocks only after certain bytes, such as space characters, which typically denote word boundaries. Our experiments show that for a fixed training and inference compute budget, SpaceByte outperforms other byte-level architectures and roughly matches the performance of tokenized Transformer architectures.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces SpaceByte, a novel approach to large language modeling that aims to eliminate the need for tokenization.
- Tokenization is a common preprocessing step in natural language processing where text is broken down into smaller units called tokens, which are then fed into language models.
- The authors argue that tokenization can be a bottleneck in large language models and propose SpaceByte as an alternative that operates directly on the raw text.
Plain English Explanation
SpaceByte: Towards Deleting Tokenization from Large Language Modeling is a research paper that presents a new way to build large language models without the need for tokenization. Tokenization is a common step in natural language processing where text is broken down into smaller pieces called tokens, which are then used to train language models.
The authors suggest that tokenization can be a limitation for large language models, as it adds overhead and complexity to the modeling process. To address this, they've developed a system called SpaceByte that can operate directly on the raw text, without requiring tokenization.
By eliminating the tokenization step, the researchers believe SpaceByte can simplify the language modeling process and potentially improve its performance. The approach is inspired by work on token-free selective state-space models and research exploring the theory of tokenization in large language models.
The core idea behind SpaceByte is to directly model the relationships between characters in the text, rather than relying on an intermediate tokenization step. This could lead to more efficient and effective language modeling, as the model can better capture the nuances and contextual information in the original text.
Technical Explanation
SpaceByte: Towards Deleting Tokenization from Large Language Modeling presents a novel approach to large language modeling that aims to eliminate the need for tokenization. Tokenization is a common preprocessing step in natural language processing where text is broken down into smaller units called tokens, which are then fed into language models.
The authors argue that tokenization can be a bottleneck in large language models, as it adds overhead and complexity to the modeling process. To address this, they've developed a system called SpaceByte that can operate directly on the raw text, without requiring tokenization.
The key technical components of SpaceByte include:
-
Character-level Modeling: Instead of tokenizing the text, SpaceByte models the relationships between individual characters in the input. This is inspired by work on token-free selective state-space models and research exploring the theory of tokenization in large language models.
-
Selective State-space Representation: SpaceByte uses a selective state-space representation to efficiently capture the dynamics of the character-level relationships, as described in Enhancing Inference Efficiency of Large Language Models by Investigating Tokenization.
-
Efficient Inference: The authors propose optimizations to improve the inference efficiency of SpaceByte, which is crucial for its practical deployment in large-scale language modeling applications.
Through extensive experiments, the researchers demonstrate that SpaceByte can achieve competitive performance on various language modeling benchmarks while eliminating the need for tokenization. This could lead to simplified and more efficient language modeling pipelines, with potential benefits for applications in data-scarce tokenization scenarios.
Critical Analysis
The SpaceByte approach presented in this paper is a promising step towards more efficient and flexible large language modeling. By eliminating the tokenization step, the authors aim to simplify the modeling process and potentially improve performance. However, the paper also acknowledges several limitations and areas for further research:
-
Computational Complexity: While the authors propose optimizations to improve the inference efficiency of SpaceByte, the character-level modeling approach may still be computationally more expensive than traditional tokenization-based models. Further research is needed to ensure SpaceByte can be deployed efficiently in large-scale applications.
-
Language Generalization: The paper focuses on evaluating SpaceByte on standard language modeling benchmarks, but it's unclear how well the approach would generalize to more diverse or specialized language domains. Additional testing in different contexts would help assess the broader applicability of the method.
-
Interpretability and Explainability: By operating directly on characters, SpaceByte may introduce challenges in interpreting and explaining the model's internal representations and decision-making processes. Exploring ways to improve the interpretability of the character-level modeling approach could be a valuable area of future research.
-
Alignment with Human Language Processing: The human brain's natural language processing capabilities are highly complex and not yet fully understood. While SpaceByte's character-level approach is inspired by insights from cognitive science, more research is needed to understand how it aligns with (or departs from) the mechanisms of human language processing.
Despite these caveats, the SpaceByte approach represents an interesting and innovative step in the quest to enhance the efficiency and flexibility of large language modeling. As the field continues to evolve, further research and development in this direction could lead to significant advancements in natural language processing and its real-world applications.
Conclusion
SpaceByte: Towards Deleting Tokenization from Large Language Modeling presents a novel approach to large language modeling that aims to eliminate the need for tokenization, a common preprocessing step in natural language processing. By operating directly on the raw text and modeling the relationships between characters, the authors believe SpaceByte can simplify the language modeling process and potentially improve its performance.
The key technical innovations of SpaceByte include character-level modeling, selective state-space representation, and efficient inference optimizations. Through experiments, the researchers demonstrate that SpaceByte can achieve competitive performance on various language modeling benchmarks while removing the tokenization step.
While the SpaceByte approach shows promise, the paper also acknowledges several limitations and areas for further research, such as computational complexity, language generalization, interpretability, and alignment with human language processing. Addressing these challenges could lead to significant advancements in the field of large language modeling and its real-world applications.
Overall, the SpaceByte paper represents an exciting and innovative contribution to the ongoing efforts to enhance the efficiency and flexibility of natural language processing systems, with the potential to pave the way for more streamlined and effective language modeling in the future.
Related Papers

MambaByte: Token-free Selective State Space Model
Junxiong Wang, Tushaar Gangavarapu, Jing Nathan Yan, Alexander M. Rush
0
0
Token-free language models learn directly from raw bytes and remove the inductive bias of subword tokenization. Operating on bytes, however, results in significantly longer sequences. In this setting, standard autoregressive Transformers scale poorly as the effective memory required grows with sequence length. The recent development of the Mamba state space model (SSM) offers an appealing alternative approach with a fixed-sized memory state and efficient decoding. We propose MambaByte, a token-free adaptation of the Mamba SSM trained autoregressively on byte sequences. In terms of modeling, we show MambaByte to be competitive with, and even to outperform, state-of-the-art subword Transformers on language modeling tasks while maintaining the benefits of token-free language models, such as robustness to noise. In terms of efficiency, we develop an adaptation of speculative decoding with tokenized drafting and byte-level verification. This results in a $2.6times$ inference speedup to the standard MambaByte implementation, showing similar decoding efficiency as the subword Mamba. These findings establish the viability of SSMs in enabling token-free language modeling.
4/4/2024
🛸
Generation Meets Verification: Accelerating Large Language Model Inference with Smart Parallel Auto-Correct Decoding
Hanling Yi, Feng Lin, Hongbin Li, Peiyang Ning, Xiaotian Yu, Rong Xiao
0
0
This research aims to accelerate the inference speed of large language models (LLMs) with billions of parameters. We propose textbf{S}mart textbf{P}arallel textbf{A}uto-textbf{C}orrect dtextbf{E}coding (SPACE), an innovative approach designed for achieving lossless acceleration of LLMs. By integrating semi-autoregressive inference and speculative decoding capabilities, SPACE uniquely enables autoregressive LLMs to parallelize token generation and verification. This is realized through a specialized semi-autoregressive supervised fine-tuning process that equips existing LLMs with the ability to simultaneously predict multiple tokens. Additionally, an auto-correct decoding algorithm facilitates the simultaneous generation and verification of token sequences within a single model invocation. Through extensive experiments on a range of LLMs, SPACE has demonstrated inference speedup ranging from 2.7x-4.0x on HumanEval-X while maintaining output quality.
4/17/2024
⚙️
Toward a Theory of Tokenization in LLMs
Nived Rajaraman, Jiantao Jiao, Kannan Ramchandran
0
0
While there has been a large body of research attempting to circumvent tokenization for language modeling (Clark et al., 2022; Xue et al., 2022), the current consensus is that it is a necessary initial step for designing state-of-the-art performant language models. In this paper, we investigate tokenization from a theoretical point of view by studying the behavior of transformers on simple data generating processes. When trained on data drawn from certain simple $k^{text{th}}$-order Markov processes for $k > 1$, transformers exhibit a surprising phenomenon - in the absence of tokenization, they empirically fail to learn the right distribution and predict characters according to a unigram model (Makkuva et al., 2024). With the addition of tokenization, however, we empirically observe that transformers break through this barrier and are able to model the probabilities of sequences drawn from the source near-optimally, achieving small cross-entropy loss. With this observation as starting point, we study the end-to-end cross-entropy loss achieved by transformers with and without tokenization. With the appropriate tokenization, we show that even the simplest unigram models (over tokens) learnt by transformers are able to model the probability of sequences drawn from $k^{text{th}}$-order Markov sources near optimally. Our analysis provides a justification for the use of tokenization in practice through studying the behavior of transformers on Markovian data.
4/15/2024
📶
Can Perplexity Predict Fine-Tuning Performance? An Investigation of Tokenization Effects on Sequential Language Models for Nepali
Nishant Luitel, Nirajan Bekoju, Anand Kumar Sah, Subarna Shakya
0
0
Recent language models use subwording mechanisms to handle Out-of-Vocabulary(OOV) words seen during test time and, their generation capacity is generally measured using perplexity, an intrinsic metric. It is known that increasing the subword granularity results in a decrease of perplexity value. However, the study of how subwording affects the understanding capacity of language models has been very few and only limited to a handful of languages. To reduce this gap we used 6 different tokenization schemes to pretrain relatively small language models in Nepali and used the representations learned to finetune on several downstream tasks. Although byte-level BPE algorithm has been used in recent models like GPT, RoBERTa we show that on average they are sub-optimal in comparison to algorithms such as SentencePiece in finetuning performances for Nepali. Additionally, similar recent studies have focused on the Bert-based language model. We, however, pretrain and finetune sequential transformer-based language models.
4/30/2024