MambaOut: Do We Really Need Mamba for Vision?
2405.07992
0
0
⚙️
Abstract
Mamba, an architecture with RNN-like token mixer of state space model (SSM), was recently introduced to address the quadratic complexity of the attention mechanism and subsequently applied to vision tasks. Nevertheless, the performance of Mamba for vision is often underwhelming when compared with convolutional and attention-based models. In this paper, we delve into the essence of Mamba, and conceptually conclude that Mamba is ideally suited for tasks with long-sequence and autoregressive characteristics. For vision tasks, as image classification does not align with either characteristic, we hypothesize that Mamba is not necessary for this task; Detection and segmentation tasks are also not autoregressive, yet they adhere to the long-sequence characteristic, so we believe it is still worthwhile to explore Mamba's potential for these tasks. To empirically verify our hypotheses, we construct a series of models named MambaOut through stacking Mamba blocks while removing their core token mixer, SSM. Experimental results strongly support our hypotheses. Specifically, our MambaOut model surpasses all visual Mamba models on ImageNet image classification, indicating that Mamba is indeed unnecessary for this task. As for detection and segmentation, MambaOut cannot match the performance of state-of-the-art visual Mamba models, demonstrating the potential of Mamba for long-sequence visual tasks. The code is available at https://github.com/yuweihao/MambaOut
Create account to get full access
Overview
- Mamba is a novel architecture that uses a recurrent neural network (RNN)-like token mixer to address the quadratic complexity of the attention mechanism, which has been applied to vision tasks.
- However, Mamba's performance in vision tasks has often been underwhelming compared to convolutional and attention-based models.
- This paper investigates the essence of Mamba and hypothesizes that it is better suited for tasks with long-sequence and autoregressive characteristics, while it may not be necessary for image classification tasks.
- The researchers construct a series of models called "MambaOut" by removing the core token mixer (SSM) from Mamba blocks to empirically verify their hypotheses.
Plain English Explanation
The paper explores a new architecture called Mamba that was recently developed to address a shortcoming of the attention mechanism used in many machine learning models. The attention mechanism can be computationally intensive, especially for tasks that involve long sequences of data.
Mamba was designed to be more efficient by using a different type of token mixer, inspired by recurrent neural networks (RNNs). The researchers hypothesize that Mamba is well-suited for tasks that involve long sequences of data or autoregressive (i.e., self-referential) characteristics, such as language modeling.
However, when Mamba has been applied to common vision tasks like image classification, its performance has often been underwhelming compared to other models that use convolutional neural networks or attention mechanisms. The researchers believe this is because image classification does not align well with the characteristics that Mamba was designed for.
To test their hypothesis, the researchers create a series of models called "MambaOut" by removing the core token mixer from Mamba. They find that these simplified MambaOut models actually outperform the original Mamba models on image classification tasks, supporting the idea that Mamba is not necessary for this type of visual task.
For other vision tasks like object detection and image segmentation, which do involve longer sequences of data, the researchers believe Mamba may still be a useful approach. They plan to further explore Mamba's potential for these types of long-sequence visual tasks.
Technical Explanation
The paper introduces a novel architecture called Mamba, which uses an RNN-like token mixer in a state space model (SSM) to address the quadratic complexity of the attention mechanism. Mamba has been applied to various vision tasks, but its performance is often underwhelming compared to convolutional and attention-based models.
To understand the essence of Mamba, the researchers conceptually conclude that Mamba is ideally suited for tasks with long-sequence and autoregressive characteristics. For vision tasks like image classification, which do not align with these characteristics, the researchers hypothesize that Mamba is not necessary.
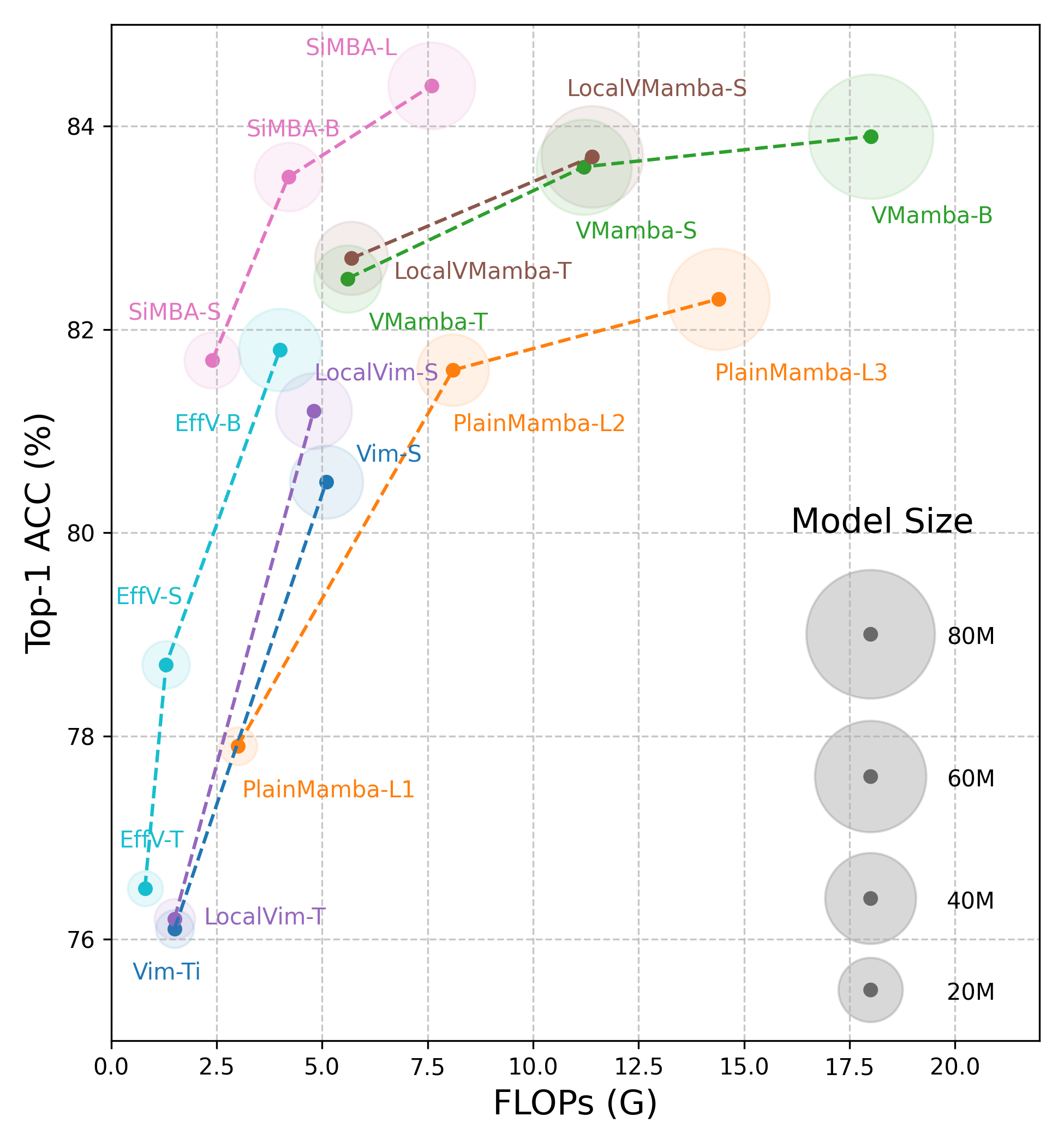
To empirically verify their hypotheses, the researchers construct a series of models called MambaOut by stacking Mamba blocks while removing their core token mixer, SSM. The experimental results strongly support their hypotheses. Specifically, the MambaOut model surpasses all visual Mamba models on the ImageNet image classification task, indicating that Mamba is indeed unnecessary for this task.
For detection and segmentation tasks, which adhere to the long-sequence characteristic but are not autoregressive, the MambaOut model cannot match the performance of state-of-the-art visual Mamba models. This demonstrates the potential of Mamba for long-sequence visual tasks, as the researchers had hypothesized.
Critical Analysis
The paper provides a thorough analysis of the Mamba architecture and its suitability for different types of vision tasks. The researchers' hypotheses and experimental approach are well-reasoned and effectively test their ideas.
One potential limitation of the research is that it focuses primarily on image classification, object detection, and segmentation tasks. It would be interesting to see how Mamba and MambaOut perform on other vision tasks, such as video understanding or 3D reconstruction, which may have different characteristics that align more or less with Mamba's design.
Additionally, the paper does not delve deeply into the underlying mechanisms and design choices of Mamba. Further research could explore the specific advantages and disadvantages of the RNN-like token mixer and state space model compared to other approaches, such as the attention mechanism or convolutional neural networks.
Overall, the paper offers valuable insights into the strengths and limitations of the Mamba architecture, and the researchers' approach of systematically testing their hypotheses is a commendable example of rigorous scientific inquiry. Their findings have the potential to guide future developments in vision Mamba models and applications, as well as inspire similar critical analyses of other emerging AI architectures.
Conclusion
This paper delves into the essence of the Mamba architecture, a novel approach that uses an RNN-like token mixer to address the computational complexities of the attention mechanism. The researchers hypothesize that Mamba is well-suited for tasks with long-sequence and autoregressive characteristics, but may not be necessary for image classification tasks.
To test their hypotheses, the researchers construct a series of simplified Mamba models called MambaOut, which remove the core token mixer from Mamba blocks. The experimental results strongly support their ideas, showing that MambaOut outperforms the original Mamba models on image classification, but cannot match Mamba's performance on other long-sequence visual tasks like object detection and segmentation.
These findings provide valuable insights into the strengths and limitations of the Mamba architecture, and offer guidance for future developments and applications of this novel approach. The critical analysis also highlights areas for further research, such as exploring Mamba's performance on a wider range of vision tasks and delving deeper into the design choices behind the architecture.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Survey on Visual Mamba
Hanwei Zhang, Ying Zhu, Dan Wang, Lijun Zhang, Tianxiang Chen, Zi Ye
0
0
State space models (SSMs) with selection mechanisms and hardware-aware architectures, namely Mamba, have recently demonstrated significant promise in long-sequence modeling. Since the self-attention mechanism in transformers has quadratic complexity with image size and increasing computational demands, the researchers are now exploring how to adapt Mamba for computer vision tasks. This paper is the first comprehensive survey aiming to provide an in-depth analysis of Mamba models in the field of computer vision. It begins by exploring the foundational concepts contributing to Mamba's success, including the state space model framework, selection mechanisms, and hardware-aware design. Next, we review these vision mamba models by categorizing them into foundational ones and enhancing them with techniques such as convolution, recurrence, and attention to improve their sophistication. We further delve into the widespread applications of Mamba in vision tasks, which include their use as a backbone in various levels of vision processing. This encompasses general visual tasks, Medical visual tasks (e.g., 2D / 3D segmentation, classification, and image registration, etc.), and Remote Sensing visual tasks. We specially introduce general visual tasks from two levels: High/Mid-level vision (e.g., Object detection, Segmentation, Video classification, etc.) and Low-level vision (e.g., Image super-resolution, Image restoration, Visual generation, etc.). We hope this endeavor will spark additional interest within the community to address current challenges and further apply Mamba models in computer vision.
4/29/2024
A Survey on Vision Mamba: Models, Applications and Challenges
Rui Xu, Shu Yang, Yihui Wang, Bo Du, Hao Chen
0
0
Mamba, a recent selective structured state space model, performs excellently on long sequence modeling tasks. Mamba mitigates the modeling constraints of convolutional neural networks and offers advanced modeling capabilities similar to those of Transformers, through global receptive fields and dynamic weighting. Crucially, it achieves this without incurring the quadratic computational complexity typically associated with Transformers. Due to its advantages over the former two mainstream foundation models, Mamba exhibits great potential to be a visual foundation model. Researchers are actively applying Mamba to various computer vision tasks, leading to numerous emerging works. To help keep pace with the rapid advancements in computer vision, this paper aims to provide a comprehensive review of visual Mamba approaches. This paper begins by delineating the formulation of the original Mamba model. Subsequently, our review of visual Mamba delves into several representative backbone networks to elucidate the core insights of the visual Mamba. We then categorize related works using different modalities, including image, video, point cloud, multi-modal, and others. Specifically, for image applications, we further organize them into distinct tasks to facilitate a more structured discussion. Finally, we discuss the challenges and future research directions for visual Mamba, providing insights for future research in this quickly evolving area. A comprehensive list of visual Mamba models reviewed in this work is available at https://github.com/Ruixxxx/Awesome-Vision-Mamba-Models.
4/30/2024

Demystify Mamba in Vision: A Linear Attention Perspective
Dongchen Han, Ziyi Wang, Zhuofan Xia, Yizeng Han, Yifan Pu, Chunjiang Ge, Jun Song, Shiji Song, Bo Zheng, Gao Huang
0
0
Mamba is an effective state space model with linear computation complexity. It has recently shown impressive efficiency in dealing with high-resolution inputs across various vision tasks. In this paper, we reveal that the powerful Mamba model shares surprising similarities with linear attention Transformer, which typically underperform conventional Transformer in practice. By exploring the similarities and disparities between the effective Mamba and subpar linear attention Transformer, we provide comprehensive analyses to demystify the key factors behind Mamba's success. Specifically, we reformulate the selective state space model and linear attention within a unified formulation, rephrasing Mamba as a variant of linear attention Transformer with six major distinctions: input gate, forget gate, shortcut, no attention normalization, single-head, and modified block design. For each design, we meticulously analyze its pros and cons, and empirically evaluate its impact on model performance in vision tasks. Interestingly, the results highlight the forget gate and block design as the core contributors to Mamba's success, while the other four designs are less crucial. Based on these findings, we propose a Mamba-Like Linear Attention (MLLA) model by incorporating the merits of these two key designs into linear attention. The resulting model outperforms various vision Mamba models in both image classification and high-resolution dense prediction tasks, while enjoying parallelizable computation and fast inference speed. Code is available at https://github.com/LeapLabTHU/MLLA.
5/28/2024

Autoregressive Pretraining with Mamba in Vision
Sucheng Ren, Xianhang Li, Haoqin Tu, Feng Wang, Fangxun Shu, Lei Zhang, Jieru Mei, Linjie Yang, Peng Wang, Heng Wang, Alan Yuille, Cihang Xie
0
0
The vision community has started to build with the recently developed state space model, Mamba, as the new backbone for a range of tasks. This paper shows that Mamba's visual capability can be significantly enhanced through autoregressive pretraining, a direction not previously explored. Efficiency-wise, the autoregressive nature can well capitalize on the Mamba's unidirectional recurrent structure, enabling faster overall training speed compared to other training strategies like mask modeling. Performance-wise, autoregressive pretraining equips the Mamba architecture with markedly higher accuracy over its supervised-trained counterparts and, more importantly, successfully unlocks its scaling potential to large and even huge model sizes. For example, with autoregressive pretraining, a base-size Mamba attains 83.2% ImageNet accuracy, outperforming its supervised counterpart by 2.0%; our huge-size Mamba, the largest Vision Mamba to date, attains 85.0% ImageNet accuracy (85.5% when finetuned with $384times384$ inputs), notably surpassing all other Mamba variants in vision. The code is available at url{https://github.com/OliverRensu/ARM}.
6/12/2024