MambaVC: Learned Visual Compression with Selective State Spaces

0

Sign in to get full access
Overview
- This paper introduces MambaVC, a novel learned visual compression approach that utilizes selective state spaces.
- MambaVC aims to improve compression performance by learning a hierarchical representation of the visual state space, capturing both global and local image features.
- The paper explores different strategies for modeling the visual state space, including multi-scale and diffusion-based approaches.
- The proposed methods demonstrate state-of-the-art performance on several image compression benchmarks.
Plain English Explanation
MambaVC: Learned Visual Compression with Selective State Spaces is a research paper that describes a new way to efficiently compress and store visual information, such as images and videos. The key idea is to build a hierarchical representation of the visual state space, which means breaking down the image into different levels of detail and capturing both the overall structure and the fine-grained features.
By modeling the visual state space in a more selective and efficient way, the researchers were able to achieve better compression performance compared to existing methods. They explored various strategies, including a multi-scale approach that captures features at different resolutions and a diffusion-based model that generates images in a step-by-step process.
The proposed MambaVC framework demonstrated state-of-the-art results on standard image compression benchmarks, indicating that this selective and hierarchical approach to modeling the visual state space can be a promising direction for improving the efficiency of image and video storage and transmission.
Technical Explanation
MambaVC: Learned Visual Compression with Selective State Spaces introduces a novel learned visual compression framework that aims to improve compression performance by learning a hierarchical representation of the visual state space. The key idea is to capture both global and local image features by modeling the visual state space in a more selective and efficient way.
The paper explores different strategies for modeling the visual state space, including a multi-scale approach that captures features at different resolutions and a diffusion-based model that generates images in a step-by-step process. The proposed MambaVC framework demonstrates state-of-the-art performance on several image compression benchmarks, outperforming existing learned compression methods.
The authors conduct extensive experiments to evaluate the effectiveness of their approach, exploring different architectural choices and training strategies. They also provide insights into the importance of modeling the visual state space in a selective and hierarchical manner for improving compression efficiency.
Critical Analysis
The paper presents a compelling approach to learned visual compression, but it is important to consider some potential limitations and areas for further research. While the reported results are impressive, the authors do not discuss the computational complexity of their methods or the trade-offs between compression performance and inference speed.
Additionally, the paper focuses primarily on image compression, and it would be valuable to explore the applicability of the MambaVC framework to other types of visual data, such as video or medical images. Extending the model to handle diverse visual modalities could further demonstrate the versatility and generalization capabilities of the proposed approach.
Furthermore, the paper does not provide a detailed analysis of the learned representations or the specific mechanisms by which the hierarchical and selective modeling of the visual state space contributes to the improved compression performance. A deeper investigation into the inner workings of the model could yield valuable insights and guide future advancements in this area.
Overall, the MambaVC framework represents an exciting development in the field of learned visual compression, and the ideas presented in this paper warrant further exploration and validation across a broader range of applications and domains.
Conclusion
MambaVC: Learned Visual Compression with Selective State Spaces introduces a novel learned visual compression approach that leverages a hierarchical and selective representation of the visual state space. By capturing both global and local image features, the proposed methods demonstrate state-of-the-art performance on standard image compression benchmarks.
The exploration of different modeling strategies, including multi-scale and diffusion-based approaches, highlights the importance of efficient and targeted representation of visual information for improving compression efficiency. The findings in this paper suggest that further research into hierarchical and selective state space modeling could lead to significant advancements in the field of learned visual compression, with potential applications in areas such as medical imaging and image fusion.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MambaVC: Learned Visual Compression with Selective State Spaces
Shiyu Qin, Jinpeng Wang, Yimin Zhou, Bin Chen, Tianci Luo, Baoyi An, Tao Dai, Shutao Xia, Yaowei Wang
Learned visual compression is an important and active task in multimedia. Existing approaches have explored various CNN- and Transformer-based designs to model content distribution and eliminate redundancy, where balancing efficacy (i.e., rate-distortion trade-off) and efficiency remains a challenge. Recently, state-space models (SSMs) have shown promise due to their long-range modeling capacity and efficiency. Inspired by this, we take the first step to explore SSMs for visual compression. We introduce MambaVC, a simple, strong and efficient compression network based on SSM. MambaVC develops a visual state space (VSS) block with a 2D selective scanning (2DSS) module as the nonlinear activation function after each downsampling, which helps to capture informative global contexts and enhances compression. On compression benchmark datasets, MambaVC achieves superior rate-distortion performance with lower computational and memory overheads. Specifically, it outperforms CNN and Transformer variants by 9.3% and 15.6% on Kodak, respectively, while reducing computation by 42% and 24%, and saving 12% and 71% of memory. MambaVC shows even greater improvements with high-resolution images, highlighting its potential and scalability in real-world applications. We also provide a comprehensive comparison of different network designs, underscoring MambaVC's advantages. Code is available at https://github.com/QinSY123/2024-MambaVC.
Read more5/29/2024
0
GroupMamba: Parameter-Efficient and Accurate Group Visual State Space Model
Abdelrahman Shaker, Syed Talal Wasim, Salman Khan, Juergen Gall, Fahad Shahbaz Khan
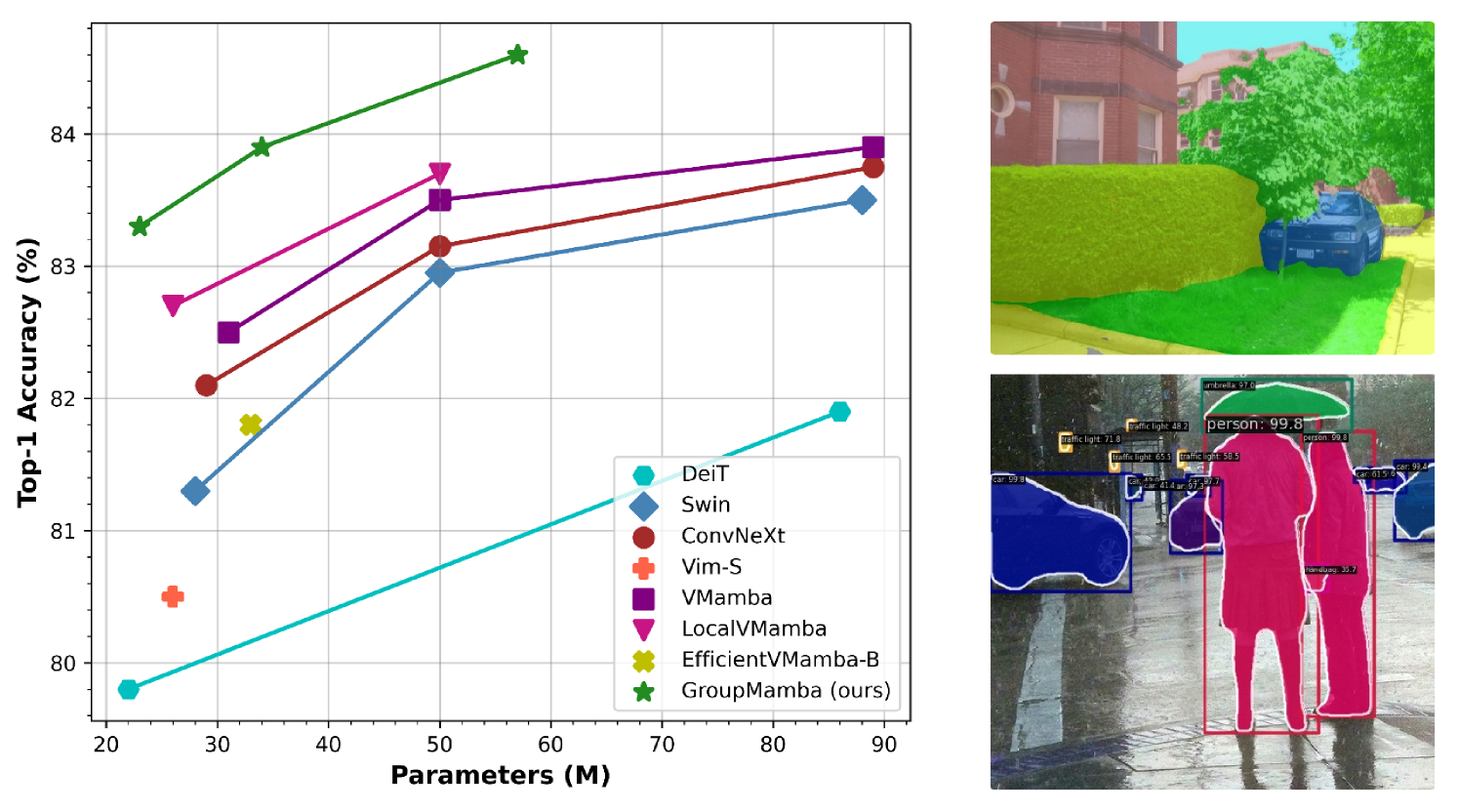
Recent advancements in state-space models (SSMs) have showcased effective performance in modeling long-range dependencies with subquadratic complexity. However, pure SSM-based models still face challenges related to stability and achieving optimal performance on computer vision tasks. Our paper addresses the challenges of scaling SSM-based models for computer vision, particularly the instability and inefficiency of large model sizes. To address this, we introduce a Modulated Group Mamba layer which divides the input channels into four groups and applies our proposed SSM-based efficient Visual Single Selective Scanning (VSSS) block independently to each group, with each VSSS block scanning in one of the four spatial directions. The Modulated Group Mamba layer also wraps the four VSSS blocks into a channel modulation operator to improve cross-channel communication. Furthermore, we introduce a distillation-based training objective to stabilize the training of large models, leading to consistent performance gains. Our comprehensive experiments demonstrate the merits of the proposed contributions, leading to superior performance over existing methods for image classification on ImageNet-1K, object detection, instance segmentation on MS-COCO, and semantic segmentation on ADE20K. Our tiny variant with 23M parameters achieves state-of-the-art performance with a classification top-1 accuracy of 83.3% on ImageNet-1K, while being 26% efficient in terms of parameters, compared to the best existing Mamba design of same model size. Our code and models are available at: https://github.com/Amshaker/GroupMamba.
Read more7/19/2024
0
A Survey on Visual Mamba
Hanwei Zhang, Ying Zhu, Dan Wang, Lijun Zhang, Tianxiang Chen, Zi Ye
State space models (SSMs) with selection mechanisms and hardware-aware architectures, namely Mamba, have recently demonstrated significant promise in long-sequence modeling. Since the self-attention mechanism in transformers has quadratic complexity with image size and increasing computational demands, the researchers are now exploring how to adapt Mamba for computer vision tasks. This paper is the first comprehensive survey aiming to provide an in-depth analysis of Mamba models in the field of computer vision. It begins by exploring the foundational concepts contributing to Mamba's success, including the state space model framework, selection mechanisms, and hardware-aware design. Next, we review these vision mamba models by categorizing them into foundational ones and enhancing them with techniques such as convolution, recurrence, and attention to improve their sophistication. We further delve into the widespread applications of Mamba in vision tasks, which include their use as a backbone in various levels of vision processing. This encompasses general visual tasks, Medical visual tasks (e.g., 2D / 3D segmentation, classification, and image registration, etc.), and Remote Sensing visual tasks. We specially introduce general visual tasks from two levels: High/Mid-level vision (e.g., Object detection, Segmentation, Video classification, etc.) and Low-level vision (e.g., Image super-resolution, Image restoration, Visual generation, etc.). We hope this endeavor will spark additional interest within the community to address current challenges and further apply Mamba models in computer vision.
Read more4/29/2024
📈
0
Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model
Yuheng Shi, Minjing Dong, Chang Xu
Despite the significant achievements of Vision Transformers (ViTs) in various vision tasks, they are constrained by the quadratic complexity. Recently, State Space Models (SSMs) have garnered widespread attention due to their global receptive field and linear complexity with respect to the input length, demonstrating substantial potential across fields including natural language processing and computer vision. To improve the performance of SSMs in vision tasks, a multi-scan strategy is widely adopted, which leads to significant redundancy of SSMs. For a better trade-off between efficiency and performance, we analyze the underlying reasons behind the success of the multi-scan strategy, where long-range dependency plays an important role. Based on the analysis, we introduce Multi-Scale Vision Mamba (MSVMamba) to preserve the superiority of SSMs in vision tasks with limited parameters. It employs a multi-scale 2D scanning technique on both original and downsampled feature maps, which not only benefits long-range dependency learning but also reduces computational costs. Additionally, we integrate a Convolutional Feed-Forward Network (ConvFFN) to address the lack of channel mixing. Our experiments demonstrate that MSVMamba is highly competitive, with the MSVMamba-Tiny model achieving 82.8% top-1 accuracy on ImageNet, 46.9% box mAP, and 42.2% instance mAP with the Mask R-CNN framework, 1x training schedule on COCO, and 47.6% mIoU with single-scale testing on ADE20K.Code is available at url{https://github.com/YuHengsss/MSVMamba}.
Read more5/24/2024