GroupMamba: Parameter-Efficient and Accurate Group Visual State Space Model

0
Sign in to get full access
Overview
- This paper introduces GroupMamba, a parameter-efficient and accurate group visual state space model for modeling visual dynamics.
- GroupMamba builds on previous work in the MultiScale-VMamba, VMamba, VoxelMamba, and MambaVC models.
- The key innovation is the use of a group-based latent representation to capture the underlying structure of visual dynamics in a more parameter-efficient manner.
Plain English Explanation
GroupMamba is a new model for understanding how visual information changes over time. It builds on previous work that tried to model the dynamics of visual data using "state space" representations. The key idea is to represent the visual world using a set of hidden "states" that evolve over time in a structured way.
The unique aspect of GroupMamba is that it uses a "group-based" latent representation. This means the hidden states are organized in a way that reflects the underlying symmetries and transformations present in the visual data. For example, if an object in an image moves to a different location, GroupMamba can represent this change compactly using the group structure, rather than requiring a large number of parameters.
By using this more efficient latent representation, GroupMamba is able to model visual dynamics accurately while using far fewer parameters than previous approaches. This makes it a more practical and scalable solution for real-world applications that need to work with large-scale visual data.
Technical Explanation
The core of the GroupMamba model is a latent state space representation that captures the underlying group structure of visual dynamics. Specifically, the authors leverage the fact that many visual transformations, like translations, rotations, and scaling, can be represented as group operations. By organizing the latent states accordingly, GroupMamba can model these transformations in a more parameter-efficient manner compared to previous VMamba and VoxelMamba models.
The GroupMamba architecture consists of an encoder that maps observations (e.g., image frames) to a group-structured latent state, and a dynamics model that updates this latent state over time. The authors demonstrate how to implement this using equivariant neural network layers that respect the group structure. Additionally, they incorporate a MambaVC-inspired selective state space, which allows the model to focus computational resources on the most relevant parts of the visual scene.
Experiments on several benchmark visual dynamics datasets show that GroupMamba achieves state-of-the-art performance in terms of both prediction accuracy and parameter efficiency, outperforming previous VMamba and VoxelMamba models as well as other baselines. This suggests the group-structured latent representation is a promising approach for modeling the dynamics of visual data.
Critical Analysis
The paper provides a solid technical foundation for the GroupMamba model and demonstrates its advantages over prior work. However, a few potential limitations and areas for future research are worth noting:
-
Scalability to higher-dimensional visual data: The experiments in the paper focus on relatively low-dimensional visual domains, such as bouncing balls and simple shapes. It remains to be seen how well the group-structured latent representation scales to more complex, high-dimensional visual data, such as natural images or videos.
-
Interpretability of the latent representations: While the group-structured latent states are designed to be more interpretable than the unstructured representations in previous models, the paper does not provide a deep analysis of the learned representations. Further work could explore the interpretability and physical meaning of the latent states.
-
Generalization to unseen transformations: The paper demonstrates that GroupMamba can accurately model the visual dynamics of transformations seen during training. However, it is unclear how well the model would generalize to novel, unseen transformations that were not encountered during training.
-
Integration with other visual reasoning tasks: The current work focuses on the task of visual dynamics modeling. Exploring how GroupMamba could be integrated with or benefit other visual reasoning tasks, such as object recognition or visual understanding, could broaden its applicability.
Despite these potential areas for improvement, the GroupMamba model represents a significant advance in the field of visual state space modeling, and the authors' use of group-structured latent representations is a promising direction for further research.
Conclusion
The GroupMamba paper introduces a novel parameter-efficient and accurate group visual state space model for modeling the dynamics of visual data. By leveraging the underlying group structure of visual transformations in the latent representation, the model is able to achieve state-of-the-art performance on several benchmark datasets while using far fewer parameters than previous approaches.
The group-structured latent representation is a promising direction for visual state space modeling, as it allows the model to compactly capture the essential transformations present in visual data. This could lead to more scalable and practical applications of visual dynamics modeling in areas like video prediction, robotic control, and interactive learning.
Overall, the GroupMamba paper makes a significant contribution to the field of visual state space modeling and opens up new avenues for further research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GroupMamba: Parameter-Efficient and Accurate Group Visual State Space Model
Abdelrahman Shaker, Syed Talal Wasim, Salman Khan, Juergen Gall, Fahad Shahbaz Khan
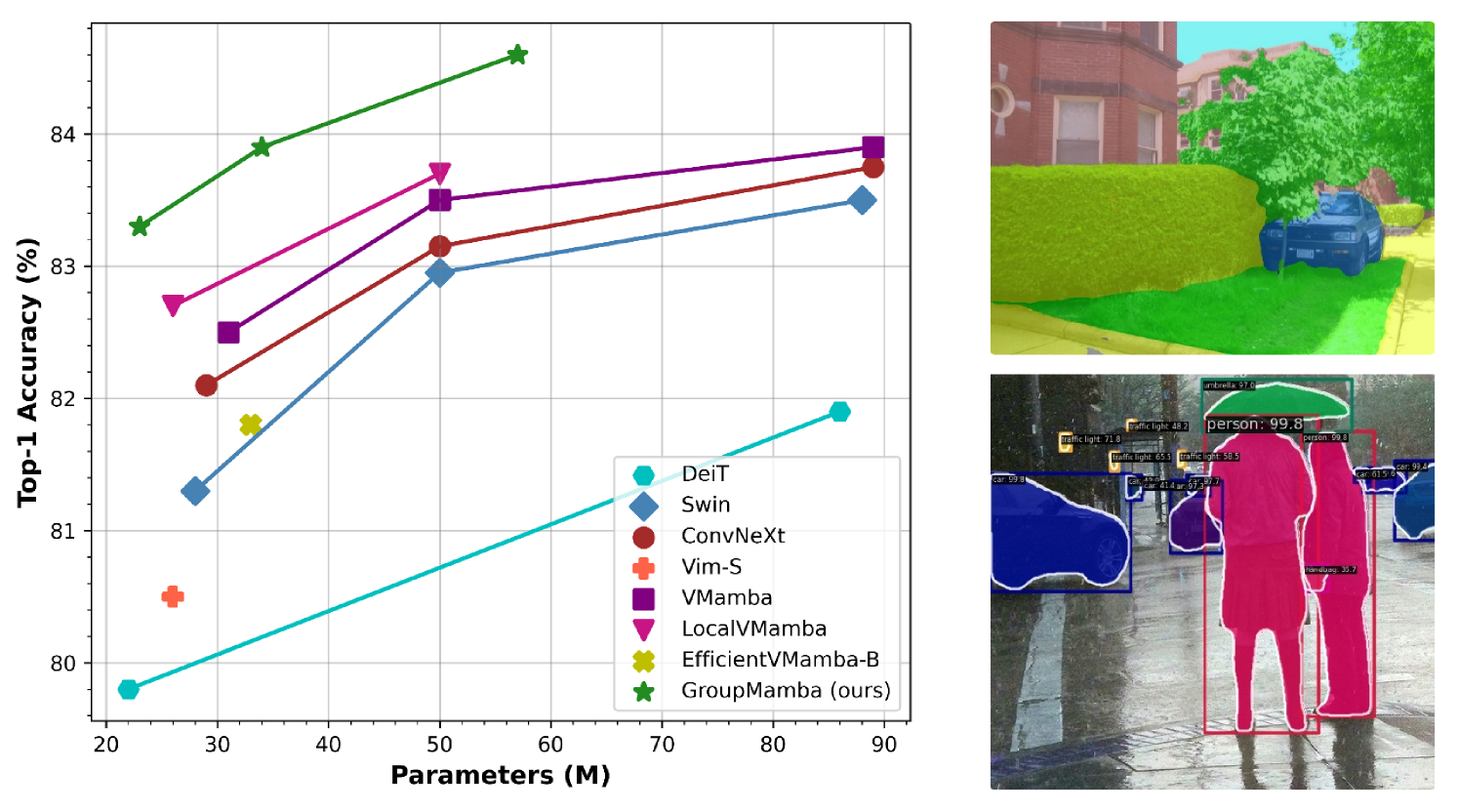
Recent advancements in state-space models (SSMs) have showcased effective performance in modeling long-range dependencies with subquadratic complexity. However, pure SSM-based models still face challenges related to stability and achieving optimal performance on computer vision tasks. Our paper addresses the challenges of scaling SSM-based models for computer vision, particularly the instability and inefficiency of large model sizes. To address this, we introduce a Modulated Group Mamba layer which divides the input channels into four groups and applies our proposed SSM-based efficient Visual Single Selective Scanning (VSSS) block independently to each group, with each VSSS block scanning in one of the four spatial directions. The Modulated Group Mamba layer also wraps the four VSSS blocks into a channel modulation operator to improve cross-channel communication. Furthermore, we introduce a distillation-based training objective to stabilize the training of large models, leading to consistent performance gains. Our comprehensive experiments demonstrate the merits of the proposed contributions, leading to superior performance over existing methods for image classification on ImageNet-1K, object detection, instance segmentation on MS-COCO, and semantic segmentation on ADE20K. Our tiny variant with 23M parameters achieves state-of-the-art performance with a classification top-1 accuracy of 83.3% on ImageNet-1K, while being 26% efficient in terms of parameters, compared to the best existing Mamba design of same model size. Our code and models are available at: https://github.com/Amshaker/GroupMamba.
Read more7/19/2024
📈
0
Multi-Scale VMamba: Hierarchy in Hierarchy Visual State Space Model
Yuheng Shi, Minjing Dong, Chang Xu
Despite the significant achievements of Vision Transformers (ViTs) in various vision tasks, they are constrained by the quadratic complexity. Recently, State Space Models (SSMs) have garnered widespread attention due to their global receptive field and linear complexity with respect to the input length, demonstrating substantial potential across fields including natural language processing and computer vision. To improve the performance of SSMs in vision tasks, a multi-scan strategy is widely adopted, which leads to significant redundancy of SSMs. For a better trade-off between efficiency and performance, we analyze the underlying reasons behind the success of the multi-scan strategy, where long-range dependency plays an important role. Based on the analysis, we introduce Multi-Scale Vision Mamba (MSVMamba) to preserve the superiority of SSMs in vision tasks with limited parameters. It employs a multi-scale 2D scanning technique on both original and downsampled feature maps, which not only benefits long-range dependency learning but also reduces computational costs. Additionally, we integrate a Convolutional Feed-Forward Network (ConvFFN) to address the lack of channel mixing. Our experiments demonstrate that MSVMamba is highly competitive, with the MSVMamba-Tiny model achieving 82.8% top-1 accuracy on ImageNet, 46.9% box mAP, and 42.2% instance mAP with the Mask R-CNN framework, 1x training schedule on COCO, and 47.6% mIoU with single-scale testing on ADE20K.Code is available at url{https://github.com/YuHengsss/MSVMamba}.
Read more5/24/2024

0
Voxel Mamba: Group-Free State Space Models for Point Cloud based 3D Object Detection
Guowen Zhang, Lue Fan, Chenhang He, Zhen Lei, Zhaoxiang Zhang, Lei Zhang
Serialization-based methods, which serialize the 3D voxels and group them into multiple sequences before inputting to Transformers, have demonstrated their effectiveness in 3D object detection. However, serializing 3D voxels into 1D sequences will inevitably sacrifice the voxel spatial proximity. Such an issue is hard to be addressed by enlarging the group size with existing serialization-based methods due to the quadratic complexity of Transformers with feature sizes. Inspired by the recent advances of state space models (SSMs), we present a Voxel SSM, termed as Voxel Mamba, which employs a group-free strategy to serialize the whole space of voxels into a single sequence. The linear complexity of SSMs encourages our group-free design, alleviating the loss of spatial proximity of voxels. To further enhance the spatial proximity, we propose a Dual-scale SSM Block to establish a hierarchical structure, enabling a larger receptive field in the 1D serialization curve, as well as more complete local regions in 3D space. Moreover, we implicitly apply window partition under the group-free framework by positional encoding, which further enhances spatial proximity by encoding voxel positional information. Our experiments on Waymo Open Dataset and nuScenes dataset show that Voxel Mamba not only achieves higher accuracy than state-of-the-art methods, but also demonstrates significant advantages in computational efficiency.
Read more6/19/2024

0
MambaVC: Learned Visual Compression with Selective State Spaces
Shiyu Qin, Jinpeng Wang, Yimin Zhou, Bin Chen, Tianci Luo, Baoyi An, Tao Dai, Shutao Xia, Yaowei Wang
Learned visual compression is an important and active task in multimedia. Existing approaches have explored various CNN- and Transformer-based designs to model content distribution and eliminate redundancy, where balancing efficacy (i.e., rate-distortion trade-off) and efficiency remains a challenge. Recently, state-space models (SSMs) have shown promise due to their long-range modeling capacity and efficiency. Inspired by this, we take the first step to explore SSMs for visual compression. We introduce MambaVC, a simple, strong and efficient compression network based on SSM. MambaVC develops a visual state space (VSS) block with a 2D selective scanning (2DSS) module as the nonlinear activation function after each downsampling, which helps to capture informative global contexts and enhances compression. On compression benchmark datasets, MambaVC achieves superior rate-distortion performance with lower computational and memory overheads. Specifically, it outperforms CNN and Transformer variants by 9.3% and 15.6% on Kodak, respectively, while reducing computation by 42% and 24%, and saving 12% and 71% of memory. MambaVC shows even greater improvements with high-resolution images, highlighting its potential and scalability in real-world applications. We also provide a comprehensive comparison of different network designs, underscoring MambaVC's advantages. Code is available at https://github.com/QinSY123/2024-MambaVC.
Read more5/29/2024