MambaVision: A Hybrid Mamba-Transformer Vision Backbone

0
Sign in to get full access
Overview
- MambaVision is a novel hybrid vision backbone that combines the strengths of Mamba models and Transformers.
- It aims to improve the performance and efficiency of computer vision tasks compared to existing approaches.
- The paper presents the architecture and key components of MambaVision, as well as experimental results on various benchmark datasets.
Plain English Explanation
MambaVision is a new type of artificial intelligence (AI) model that is designed to work well for computer vision tasks, such as object recognition or image classification. It combines two different approaches to AI - Mamba models and Transformers - in order to get the best of both worlds.
Mamba models are a type of AI that are inspired by the way the brain processes information. They are good at learning complex patterns and relationships in data, which makes them well-suited for vision tasks. Transformers, on the other hand, are a type of AI that are great at processing and understanding language.
By combining Mamba and Transformer approaches, MambaVision is able to take advantage of the strengths of both. It can learn the visual patterns and structures in images, while also understanding the broader context and relationships between different visual elements. This allows it to perform computer vision tasks more accurately and efficiently compared to existing AI models.
The paper describes the inner workings of MambaVision in technical detail, but the key idea is that it blends two powerful AI techniques in a novel way to create a more capable and versatile vision system. This could lead to improvements in a wide range of computer vision applications, from self-driving cars to medical image analysis.
Technical Explanation
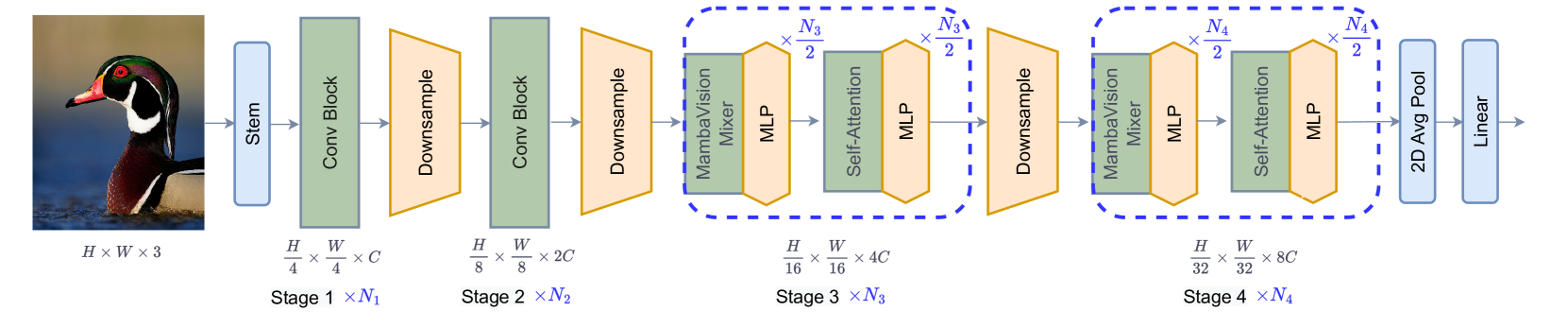
The core of MambaVision is a hybrid architecture that integrates Mamba models and Transformer modules. The Mamba component is responsible for extracting low-level visual features, while the Transformer component focuses on modeling high-level semantic relationships.
Specifically, the Mamba module consists of several convolutional layers that capture local visual patterns, followed by a Mamba cell that learns global feature representations. The Transformer module then takes the Mamba features as input and applies a series of self-attention and feed-forward layers to model long-range dependencies.
To further enhance the performance, MambaVision employs several novel techniques:
-
Adaptive Spatial Pyramid Pooling: This adaptive pooling mechanism allows the model to capture features at multiple scales, improving its ability to handle objects of varying sizes.
-
Dynamic Spatial Attention: The Transformer module dynamically attends to relevant spatial regions, enabling the model to focus on the most informative parts of the input.
-
Efficient Mamba-Transformer Interactions: The information flow between the Mamba and Transformer components is carefully designed to maximize the synergies between the two sub-modules.
The authors evaluate MambaVision on a range of computer vision benchmarks, including image classification, object detection, and semantic segmentation. The results demonstrate that MambaVision outperforms state-of-the-art vision transformers and Mamba-based models, while also being more parameter-efficient.
Critical Analysis
The paper presents a compelling approach to building a more powerful and efficient vision backbone by combining Mamba and Transformer techniques. However, there are a few potential limitations and areas for further research:
-
The authors only test MambaVision on standard computer vision benchmarks, which may not fully capture its performance on more complex or real-world vision tasks. Further evaluation on challenging, domain-specific datasets would help validate the model's broad applicability.
-
The paper does not provide a detailed analysis of the computational cost and inference speed of MambaVision compared to other models. This information would be valuable for understanding the practical benefits and tradeoffs of the proposed approach.
-
While the authors mention the potential for MambaVision to be applied to various vision-related applications, they do not explore these use cases in depth. Demonstrating the model's effectiveness in specific domains, such as medical image classification or robotic vision, would further strengthen the case for its real-world impact.
Overall, the MambaVision paper presents an innovative approach to building more capable and efficient vision systems. Further research and validation of the model's performance and practical applications would be valuable for advancing the field of computer vision.
Conclusion
In summary, MambaVision is a novel hybrid vision backbone that combines the strengths of Mamba models and Transformers to improve the performance and efficiency of computer vision tasks. By leveraging the complementary abilities of these two AI techniques, MambaVision demonstrates superior results compared to state-of-the-art models on various benchmarks.
While the paper provides a solid technical foundation for MambaVision, there are opportunities for further research and validation to fully understand its potential impact on real-world vision applications, such as medical imaging or autonomous systems. Overall, the MambaVision approach represents an exciting step forward in the development of more capable and efficient computer vision systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MambaVision: A Hybrid Mamba-Transformer Vision Backbone
Ali Hatamizadeh, Jan Kautz
We propose a novel hybrid Mamba-Transformer backbone, denoted as MambaVision, which is specifically tailored for vision applications. Our core contribution includes redesigning the Mamba formulation to enhance its capability for efficient modeling of visual features. In addition, we conduct a comprehensive ablation study on the feasibility of integrating Vision Transformers (ViT) with Mamba. Our results demonstrate that equipping the Mamba architecture with several self-attention blocks at the final layers greatly improves the modeling capacity to capture long-range spatial dependencies. Based on our findings, we introduce a family of MambaVision models with a hierarchical architecture to meet various design criteria. For Image classification on ImageNet-1K dataset, MambaVision model variants achieve a new State-of-the-Art (SOTA) performance in terms of Top-1 accuracy and image throughput. In downstream tasks such as object detection, instance segmentation and semantic segmentation on MS COCO and ADE20K datasets, MambaVision outperforms comparably-sized backbones and demonstrates more favorable performance. Code: https://github.com/NVlabs/MambaVision.
Read more7/12/2024
0
A Survey on Vision Mamba: Models, Applications and Challenges
Rui Xu, Shu Yang, Yihui Wang, Yu Cai, Bo Du, Hao Chen
Mamba, a recent selective structured state space model, excels in long sequence modeling, which is vital in the large model era. Long sequence modeling poses significant challenges, including capturing long-range dependencies within the data and handling the computational demands caused by their extensive length. Mamba addresses these challenges by overcoming the local perception limitations of convolutional neural networks and the quadratic computational complexity of Transformers. Given its advantages over these mainstream foundation architectures, Mamba exhibits great potential to be a visual foundation architecture. Since January 2024, Mamba has been actively applied to diverse computer vision tasks, yielding numerous contributions. To help keep pace with the rapid advancements, this paper reviews visual Mamba approaches, analyzing over 200 papers. This paper begins by delineating the formulation of the original Mamba model. Subsequently, it delves into representative backbone networks, and applications categorized using different modalities, including image, video, point cloud, and multi-modal. Particularly, we identify scanning techniques as critical for adapting Mamba to vision tasks, and decouple these scanning techniques to clarify their functionality and enhance their flexibility across various applications. Finally, we discuss the challenges and future directions, providing insights into new outlooks in this fast evolving area. A comprehensive list of visual Mamba models reviewed in this work is available at https://github.com/Ruixxxx/Awesome-Vision-Mamba-Models.
Read more7/9/2024
0
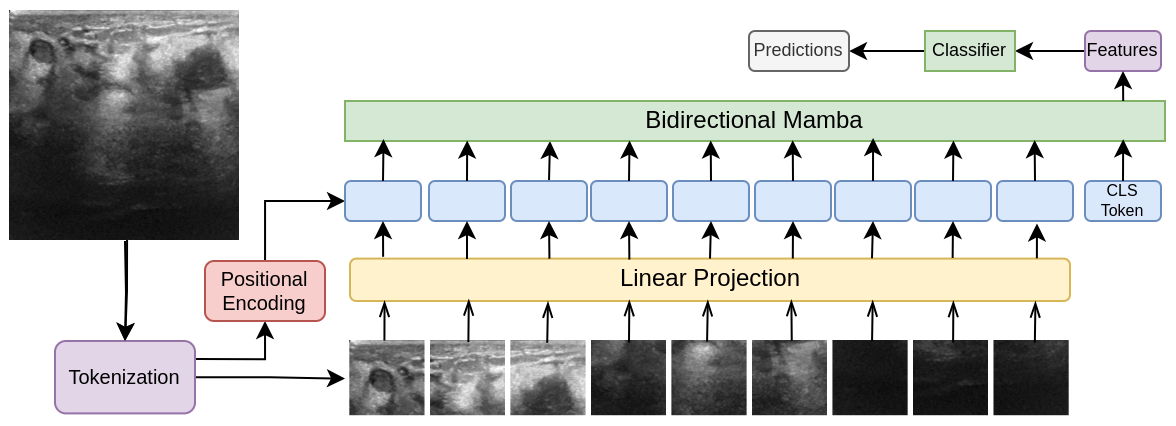
Vision Mamba for Classification of Breast Ultrasound Images
Ali Nasiri-Sarvi, Mahdi S. Hosseini, Hassan Rivaz
Mamba-based models, VMamba and Vim, are a recent family of vision encoders that offer promising performance improvements in many computer vision tasks. This paper compares Mamba-based models with traditional Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) using the breast ultrasound BUSI and B datasets. Our evaluation, which includes multiple runs of experiments and statistical significance analysis, demonstrates that Mamba-based architectures frequently outperform CNN and ViT models with statistically significant results. These Mamba-based models effectively capture long-range dependencies while maintaining inductive biases, making them suitable for applications with limited data.
Read more7/8/2024
0
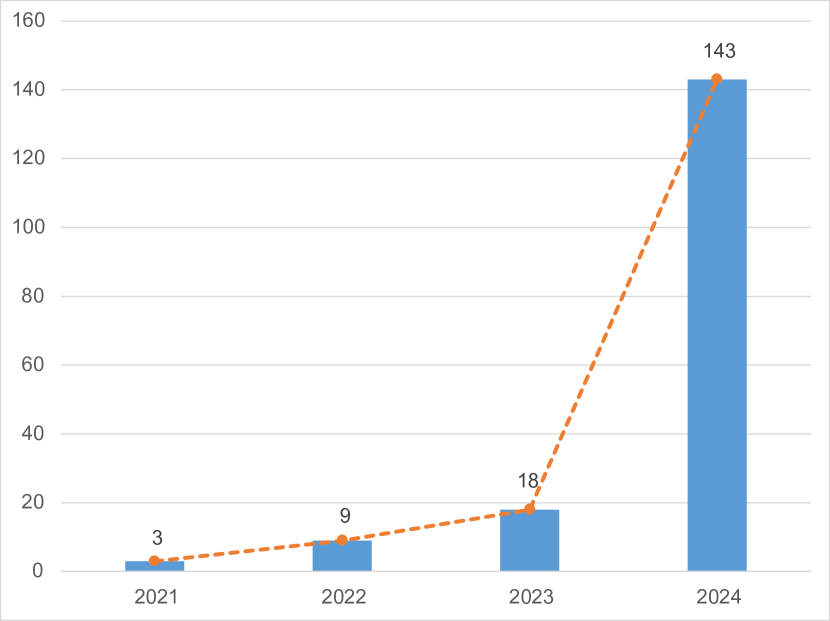
A Survey on Visual Mamba
Hanwei Zhang, Ying Zhu, Dan Wang, Lijun Zhang, Tianxiang Chen, Zi Ye
State space models (SSMs) with selection mechanisms and hardware-aware architectures, namely Mamba, have recently demonstrated significant promise in long-sequence modeling. Since the self-attention mechanism in transformers has quadratic complexity with image size and increasing computational demands, the researchers are now exploring how to adapt Mamba for computer vision tasks. This paper is the first comprehensive survey aiming to provide an in-depth analysis of Mamba models in the field of computer vision. It begins by exploring the foundational concepts contributing to Mamba's success, including the state space model framework, selection mechanisms, and hardware-aware design. Next, we review these vision mamba models by categorizing them into foundational ones and enhancing them with techniques such as convolution, recurrence, and attention to improve their sophistication. We further delve into the widespread applications of Mamba in vision tasks, which include their use as a backbone in various levels of vision processing. This encompasses general visual tasks, Medical visual tasks (e.g., 2D / 3D segmentation, classification, and image registration, etc.), and Remote Sensing visual tasks. We specially introduce general visual tasks from two levels: High/Mid-level vision (e.g., Object detection, Segmentation, Video classification, etc.) and Low-level vision (e.g., Image super-resolution, Image restoration, Visual generation, etc.). We hope this endeavor will spark additional interest within the community to address current challenges and further apply Mamba models in computer vision.
Read more4/29/2024