Vision Mamba for Classification of Breast Ultrasound Images

0
Sign in to get full access
Overview
- The paper proposes a new deep learning model called "Vision Mamba" for classifying breast ultrasound images.
- The model uses a state-space representation to capture the complex dynamics of breast ultrasound data.
- Experiments on a benchmark dataset show the Vision Mamba model outperforms existing approaches in terms of classification accuracy.
Plain English Explanation
Vision Mamba is a new deep learning algorithm designed to analyze breast ultrasound images and identify whether they show signs of breast cancer. Breast ultrasound is a common medical imaging technique, but automatically interpreting these images can be challenging due to their complex and dynamic nature.
To address this, the Vision Mamba model uses a state-space representation to capture the underlying structure and temporal changes in the breast ultrasound data. This allows the model to better understand the patterns and features that are indicative of cancer versus normal tissue.
The researchers tested the Vision Mamba model on a standard dataset of breast ultrasound images and found that it outperformed other deep learning approaches in accurately classifying the images. This suggests the state-space modeling approach used by Vision Mamba is an effective way to tackle the complexities of breast ultrasound data and could lead to improved computer-aided diagnosis tools for breast cancer screening.
Technical Explanation
The Vision Mamba model is built on the idea of using a state-space representation to model the dynamics of breast ultrasound images. This approach allows the model to capture the underlying structure and temporal evolution of the breast tissue, which is crucial for accurately distinguishing between cancerous and normal patterns.
The key components of the Vision Mamba architecture include:
- Encoder: A convolutional neural network that extracts visual features from the input ultrasound image
- State Transition Model: A recurrent neural network that models the dynamics of the breast tissue over time
- Classifier: A fully-connected network that takes the state-space representation and outputs the final cancer classification
During training, the model learns to optimize both the visual feature extraction and the state transition modeling in an end-to-end fashion, allowing it to discover the most informative representations for breast cancer diagnosis.
The researchers evaluated the Vision Mamba model on a benchmark breast ultrasound dataset and showed that it outperformed other deep learning baselines, such as standard convolutional networks and recurrent models. This demonstrates the value of the state-space modeling approach for handling the complex, temporal nature of breast ultrasound data.
Critical Analysis
The paper provides a compelling technical approach for breast cancer classification from ultrasound images using the Vision Mamba model. However, there are a few potential limitations and areas for further research:
-
Dataset Size and Diversity: The experiments were conducted on a single, relatively small dataset of breast ultrasound images. It would be important to evaluate the generalizability of the Vision Mamba model on larger and more diverse datasets, including images from different healthcare providers and patient populations.
-
Interpretability: As with many deep learning models, the internal workings of Vision Mamba may be difficult to interpret, making it challenging to understand the specific visual features and dynamics that the model is using to make its cancer predictions. Incorporating more explainable AI techniques could help improve the model's transparency.
-
Clinical Validation: While the reported classification accuracy is promising, further clinical validation would be needed to assess the real-world performance and potential impacts of using Vision Mamba in breast cancer screening workflows. Factors such as workflow integration, physician acceptance, and patient outcomes should be considered.
-
Computational Efficiency: The paper does not provide details on the computational complexity and runtime of the Vision Mamba model, which could be important considerations for deployment in clinical settings with limited computational resources.
Overall, the Vision Mamba model represents an innovative approach to breast ultrasound image classification that leverages state-space representations to handle the dynamic nature of the data. Further research and validation could help unlock the full potential of this technique for improving breast cancer screening and diagnosis.
Conclusion
The Vision Mamba model proposed in this paper offers a promising deep learning approach for classifying breast ultrasound images and identifying signs of breast cancer. By using a state-space representation to capture the complex dynamics of the breast tissue, the model demonstrates superior performance compared to other deep learning methods on a benchmark dataset.
While further research is needed to address potential limitations around dataset size, model interpretability, clinical validation, and computational efficiency, the core ideas behind Vision Mamba suggest it could be a valuable tool for enhancing computer-aided breast cancer diagnosis from ultrasound imaging. As AI continues to advance in the medical imaging domain, techniques like Vision Mamba may play an important role in improving the accuracy, consistency, and accessibility of breast cancer screening.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
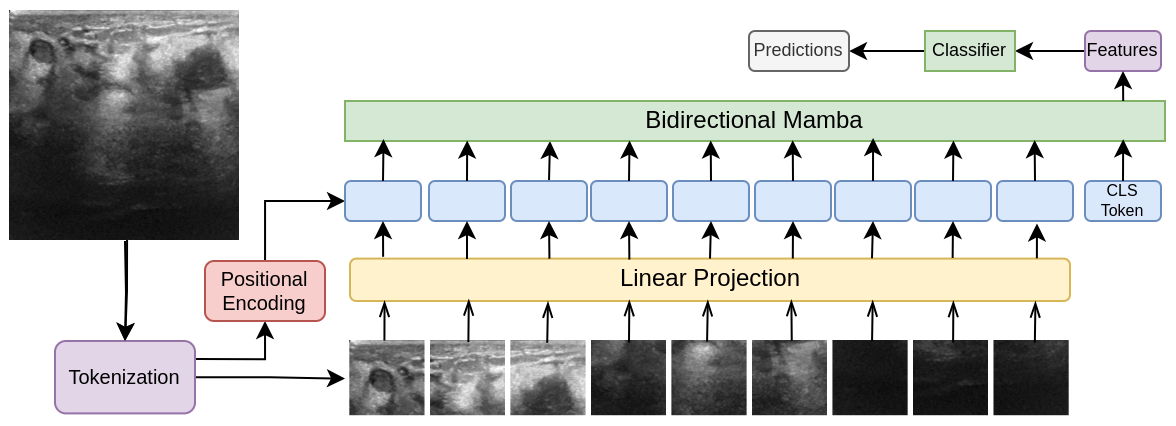
Vision Mamba for Classification of Breast Ultrasound Images
Ali Nasiri-Sarvi, Mahdi S. Hosseini, Hassan Rivaz
Mamba-based models, VMamba and Vim, are a recent family of vision encoders that offer promising performance improvements in many computer vision tasks. This paper compares Mamba-based models with traditional Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) using the breast ultrasound BUSI and B datasets. Our evaluation, which includes multiple runs of experiments and statistical significance analysis, demonstrates that Mamba-based architectures frequently outperform CNN and ViT models with statistically significant results. These Mamba-based models effectively capture long-range dependencies while maintaining inductive biases, making them suitable for applications with limited data.
Read more7/8/2024
0
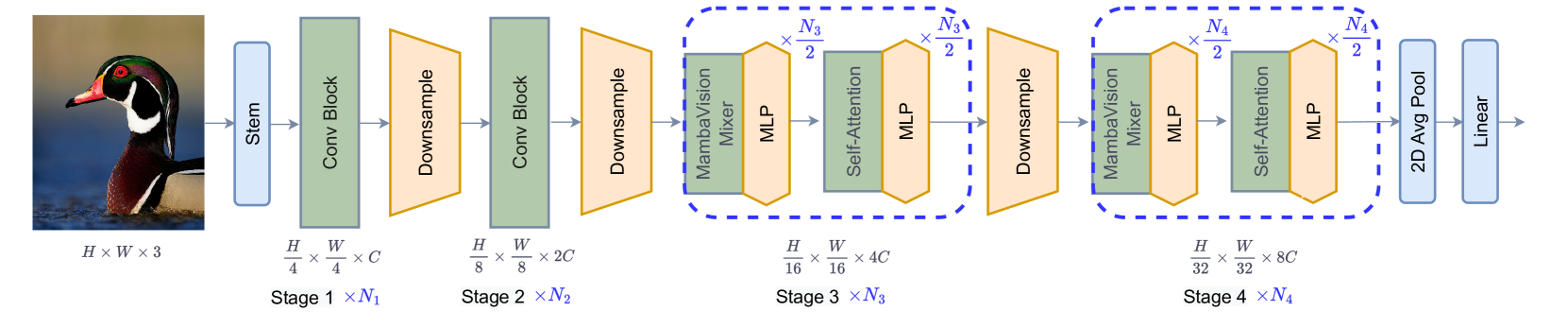
MambaVision: A Hybrid Mamba-Transformer Vision Backbone
Ali Hatamizadeh, Jan Kautz
We propose a novel hybrid Mamba-Transformer backbone, denoted as MambaVision, which is specifically tailored for vision applications. Our core contribution includes redesigning the Mamba formulation to enhance its capability for efficient modeling of visual features. In addition, we conduct a comprehensive ablation study on the feasibility of integrating Vision Transformers (ViT) with Mamba. Our results demonstrate that equipping the Mamba architecture with several self-attention blocks at the final layers greatly improves the modeling capacity to capture long-range spatial dependencies. Based on our findings, we introduce a family of MambaVision models with a hierarchical architecture to meet various design criteria. For Image classification on ImageNet-1K dataset, MambaVision model variants achieve a new State-of-the-Art (SOTA) performance in terms of Top-1 accuracy and image throughput. In downstream tasks such as object detection, instance segmentation and semantic segmentation on MS COCO and ADE20K datasets, MambaVision outperforms comparably-sized backbones and demonstrates more favorable performance. Code: https://github.com/NVlabs/MambaVision.
Read more7/12/2024
0
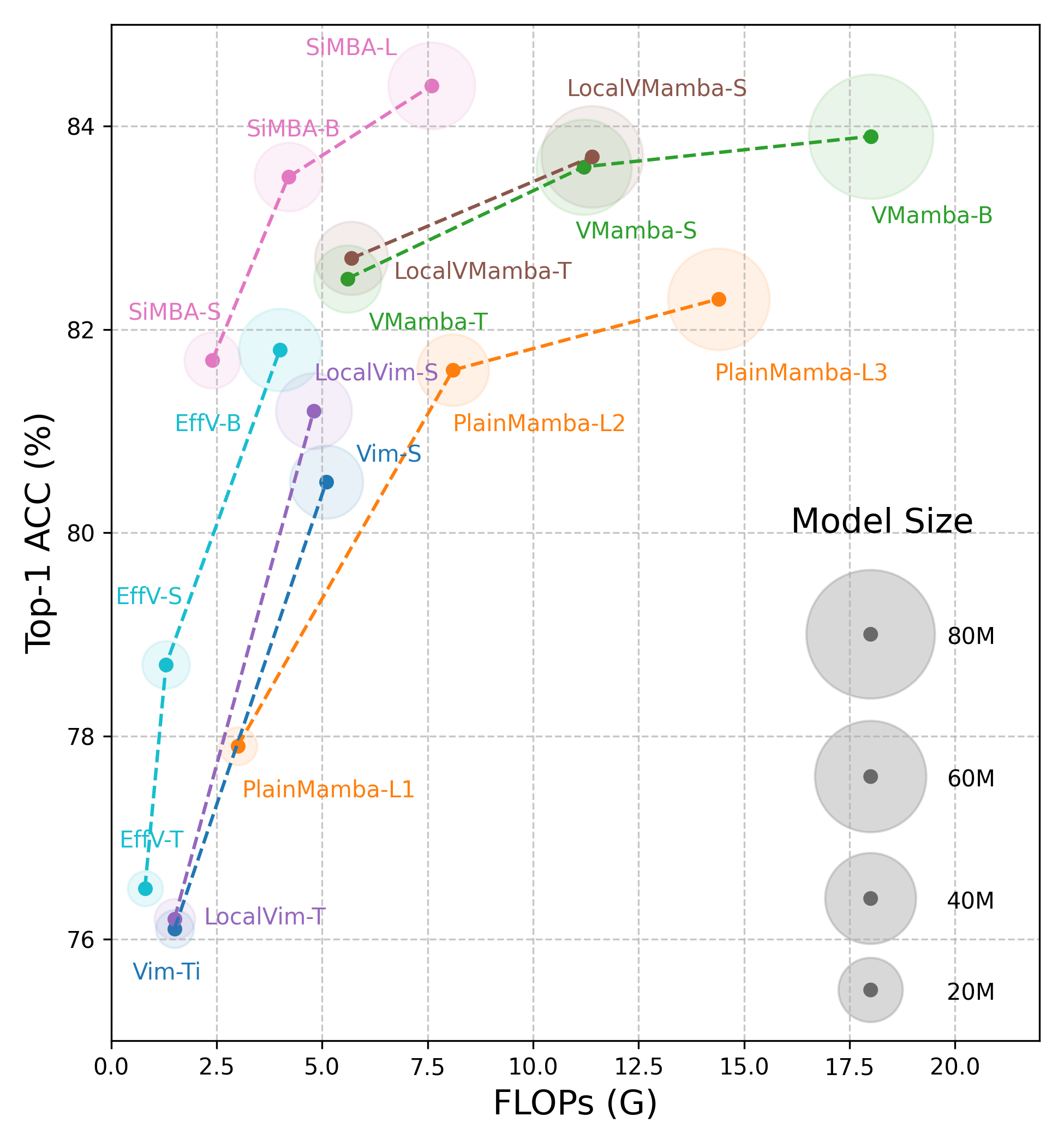
A Survey on Vision Mamba: Models, Applications and Challenges
Rui Xu, Shu Yang, Yihui Wang, Yu Cai, Bo Du, Hao Chen
Mamba, a recent selective structured state space model, excels in long sequence modeling, which is vital in the large model era. Long sequence modeling poses significant challenges, including capturing long-range dependencies within the data and handling the computational demands caused by their extensive length. Mamba addresses these challenges by overcoming the local perception limitations of convolutional neural networks and the quadratic computational complexity of Transformers. Given its advantages over these mainstream foundation architectures, Mamba exhibits great potential to be a visual foundation architecture. Since January 2024, Mamba has been actively applied to diverse computer vision tasks, yielding numerous contributions. To help keep pace with the rapid advancements, this paper reviews visual Mamba approaches, analyzing over 200 papers. This paper begins by delineating the formulation of the original Mamba model. Subsequently, it delves into representative backbone networks, and applications categorized using different modalities, including image, video, point cloud, and multi-modal. Particularly, we identify scanning techniques as critical for adapting Mamba to vision tasks, and decouple these scanning techniques to clarify their functionality and enhance their flexibility across various applications. Finally, we discuss the challenges and future directions, providing insights into new outlooks in this fast evolving area. A comprehensive list of visual Mamba models reviewed in this work is available at https://github.com/Ruixxxx/Awesome-Vision-Mamba-Models.
Read more7/9/2024
0
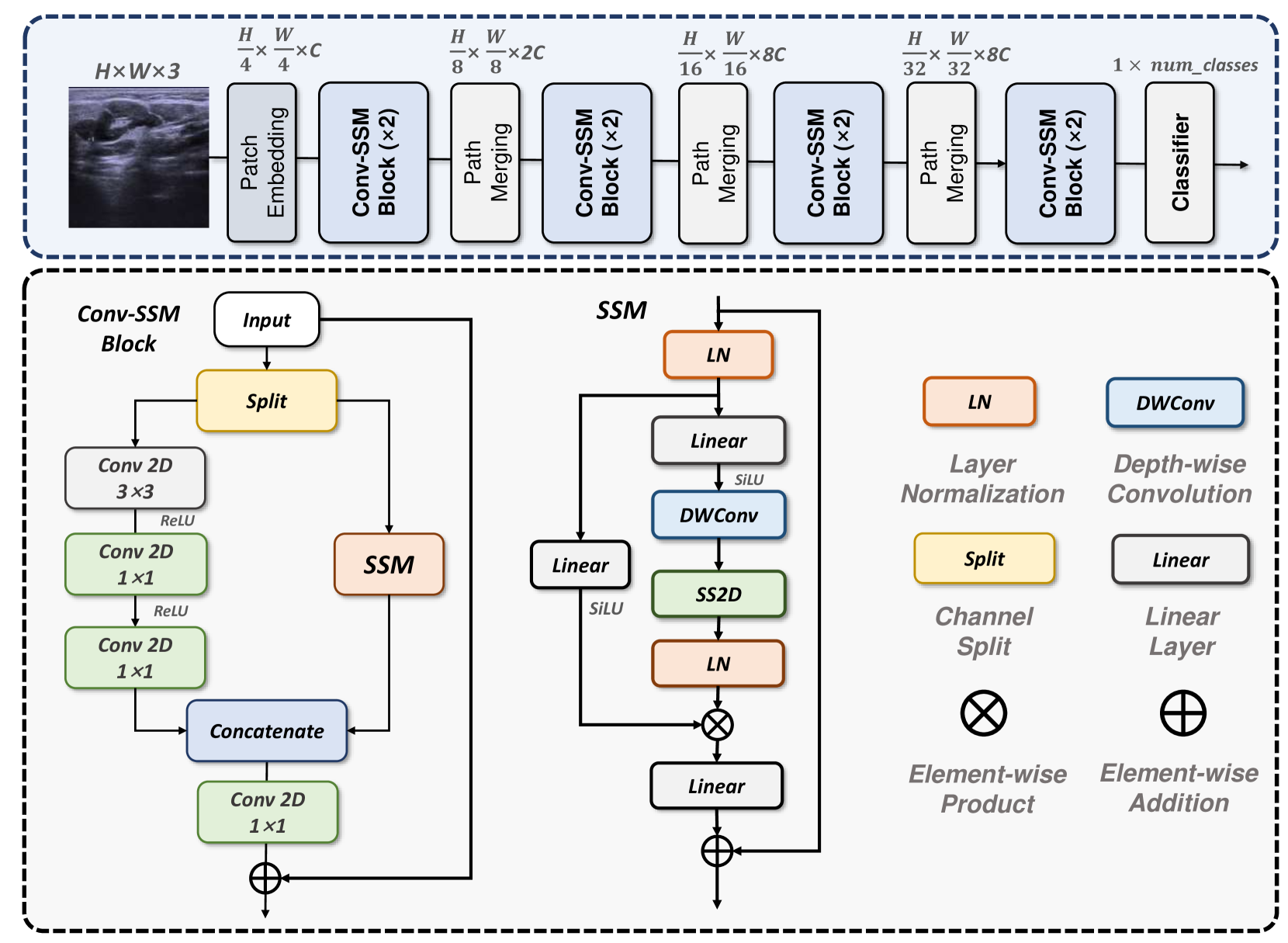
MedMamba: Vision Mamba for Medical Image Classification
Yubiao Yue, Zhenzhang Li
Since the era of deep learning, convolutional neural networks (CNNs) and vision transformers (ViTs) have been extensively studied and widely used in medical image classification tasks. Unfortunately, CNN's limitations in modeling long-range dependencies result in poor classification performances. In contrast, ViTs are hampered by the quadratic computational complexity of their self-attention mechanism, making them difficult to deploy in real-world settings with limited computational resources. Recent studies have shown that state space models (SSMs) represented by Mamba can effectively model long-range dependencies while maintaining linear computational complexity. Inspired by it, we proposed MedMamba, the first vision Mamba for generalized medical image classification. Concretely, we introduced a novel hybrid basic block named SS-Conv-SSM, which integrates the convolutional layers for extracting local features with the abilities of SSM to capture long-range dependencies, aiming to model medical images from different image modalities efficiently. By employing the grouped convolution strategy and channel-shuffle operation, MedMamba successfully provides fewer model parameters and a lower computational burden for efficient applications. To demonstrate the potential of MedMamba, we conducted extensive experiments using 16 datasets containing ten imaging modalities and 411,007 images. Experimental results show that the proposed MedMamba demonstrates competitive performance in classifying various medical images compared with the state-of-the-art methods. Our work is aims to establish a new baseline for medical image classification and provide valuable insights for developing more powerful SSM-based artificial intelligence algorithms and application systems in the medical field. The source codes and all pre-trained weights of MedMamba are available at https://github.com/YubiaoYue/MedMamba.
Read more6/11/2024