ManiWAV: Learning Robot Manipulation from In-the-Wild Audio-Visual Data

0
Sign in to get full access
Overview
- This paper presents ManiWAV, a system that learns robot manipulation skills from in-the-wild audio-visual data.
- The key idea is to leverage large-scale datasets of people interacting with objects to train robots to mimic human manipulation behaviors.
- The authors demonstrate that this approach can enable robots to perform a wide range of manipulation tasks without the need for extensive manual programming or data collection.
Plain English Explanation
The researchers developed a system called ManiWAV that can teach robots how to manipulate objects by learning from videos of people doing it. Instead of programming robots to perform specific tasks, the system uses machine learning to analyze videos of humans interacting with objects in the real world. It then uses that knowledge to enable robots to perform similar manipulation skills.
This is a powerful approach because it allows robots to learn a much wider range of capabilities from existing data, rather than having to be programmed for each task individually. It could enable robots to become more flexible and adaptable, able to handle a variety of objects and situations without the need for extensive manual programming.
The key innovation is leveraging audio-visual data of human manipulation, rather than relying solely on robot-collected data or simulated environments. This allows the system to learn from a much richer and more diverse set of manipulation examples. The authors also use specialized audio-visual datasets to further enhance the system's capabilities.
Overall, ManiWAV represents an important step forward in enabling robots to learn complex manipulation skills from observing human behavior, rather than relying entirely on manual programming or specialized data collection. This could have significant implications for the development of more flexible and capable robot assistants.
Technical Explanation
The key technical innovation in ManiWAV is the use of large-scale audio-visual datasets of human manipulation to train robot manipulation skills. The authors leverage datasets like EPIC-KITCHENS that contain videos of people interacting with objects in the real world.
They use deep learning models to analyze the visual and audio cues in these videos, allowing the robot to learn the underlying manipulation skills. This includes understanding the object properties, hand motions, and sounds associated with different manipulation behaviors.
The ManiWAV system then uses this learned knowledge to enable the robot to perform similar manipulation tasks, even on novel objects. The authors demonstrate the capability of their approach on a range of challenging manipulation benchmarks, showing that it can outperform prior methods that rely more heavily on specialized robot-collected data or simulated environments.
A key aspect of the ManiWAV architecture is the use of multimodal learning, combining visual and audio information to gain a more comprehensive understanding of manipulation. The authors also leverage transfer learning techniques to efficiently adapt the models to new robotic hardware and scenarios.
Critical Analysis
One potential limitation of the ManiWAV approach is the reliance on in-the-wild audio-visual data, which can be noisy and lack precise annotations compared to more controlled datasets. The authors acknowledge this challenge and discuss strategies for dealing with the inherent uncertainty in the training data.
Additionally, while ManiWAV demonstrates strong performance on benchmark tasks, it remains to be seen how well the system would generalize to real-world robotic applications with all their complexities. Further research may be needed to address issues like safety, robustness, and seamless integration with physical robot systems.
Another aspect that could be explored further is the interpretability and explainability of the ManiWAV models. Understanding the specific manipulation cues and strategies learned from the audio-visual data could provide valuable insights for robot control and programming.
Overall, the ManiWAV approach represents an exciting advancement in leveraging large-scale human data to enable more flexible and capable robot manipulation. However, as with any new technology, there are still challenges and areas for further refinement and exploration.
Conclusion
The ManiWAV system presented in this paper demonstrates the potential of learning robot manipulation skills from in-the-wild audio-visual data. By leveraging large datasets of human-object interactions, the system can enable robots to perform a wide range of manipulation tasks without the need for extensive manual programming or specialized data collection.
This approach has significant implications for the development of more flexible and capable robot assistants that can adapt to a variety of real-world situations. By learning from human behavior, robots can become more intuitive and natural in their manipulation abilities, potentially opening up new applications in areas like personal assistance, manufacturing, and healthcare.
While there are still some challenges to address, the ManiWAV system represents an important step forward in the field of robot learning and manipulation. As the authors continue to refine and expand this technology, it could help pave the way for a new generation of robots that can seamlessly integrate with and assist humans in their daily lives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ManiWAV: Learning Robot Manipulation from In-the-Wild Audio-Visual Data
Zeyi Liu, Cheng Chi, Eric Cousineau, Naveen Kuppuswamy, Benjamin Burchfiel, Shuran Song
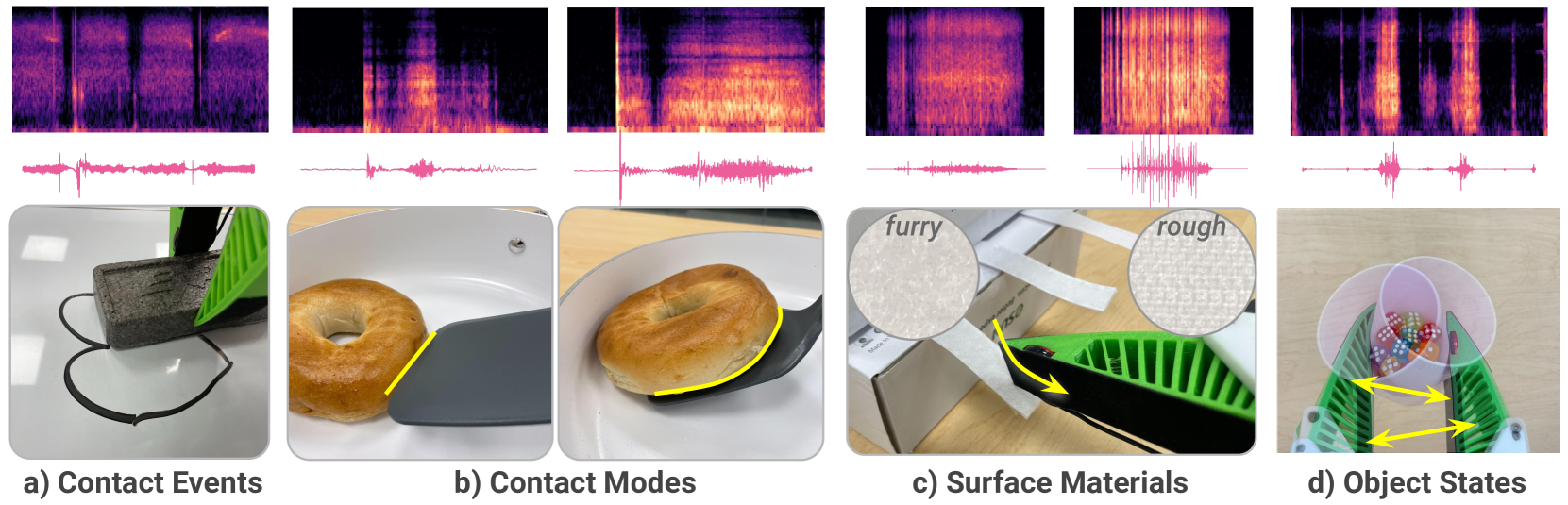
Audio signals provide rich information for the robot interaction and object properties through contact. These information can surprisingly ease the learning of contact-rich robot manipulation skills, especially when the visual information alone is ambiguous or incomplete. However, the usage of audio data in robot manipulation has been constrained to teleoperated demonstrations collected by either attaching a microphone to the robot or object, which significantly limits its usage in robot learning pipelines. In this work, we introduce ManiWAV: an 'ear-in-hand' data collection device to collect in-the-wild human demonstrations with synchronous audio and visual feedback, and a corresponding policy interface to learn robot manipulation policy directly from the demonstrations. We demonstrate the capabilities of our system through four contact-rich manipulation tasks that require either passively sensing the contact events and modes, or actively sensing the object surface materials and states. In addition, we show that our system can generalize to unseen in-the-wild environments, by learning from diverse in-the-wild human demonstrations. Project website: https://mani-wav.github.io/
Read more7/1/2024
🚀
0
Hearing Touch: Audio-Visual Pretraining for Contact-Rich Manipulation
Jared Mejia, Victoria Dean, Tess Hellebrekers, Abhinav Gupta
Although pre-training on a large amount of data is beneficial for robot learning, current paradigms only perform large-scale pretraining for visual representations, whereas representations for other modalities are trained from scratch. In contrast to the abundance of visual data, it is unclear what relevant internet-scale data may be used for pretraining other modalities such as tactile sensing. Such pretraining becomes increasingly crucial in the low-data regimes common in robotics applications. In this paper, we address this gap by using contact microphones as an alternative tactile sensor. Our key insight is that contact microphones capture inherently audio-based information, allowing us to leverage large-scale audio-visual pretraining to obtain representations that boost the performance of robotic manipulation. To the best of our knowledge, our method is the first approach leveraging large-scale multisensory pre-training for robotic manipulation. For supplementary information including videos of real robot experiments, please see https://sites.google.com/view/hearing-touch.
Read more5/15/2024

0
Hand-Object Interaction Pretraining from Videos
Himanshu Gaurav Singh, Antonio Loquercio, Carmelo Sferrazza, Jane Wu, Haozhi Qi, Pieter Abbeel, Jitendra Malik
We present an approach to learn general robot manipulation priors from 3D hand-object interaction trajectories. We build a framework to use in-the-wild videos to generate sensorimotor robot trajectories. We do so by lifting both the human hand and the manipulated object in a shared 3D space and retargeting human motions to robot actions. Generative modeling on this data gives us a task-agnostic base policy. This policy captures a general yet flexible manipulation prior. We empirically demonstrate that finetuning this policy, with both reinforcement learning (RL) and behavior cloning (BC), enables sample-efficient adaptation to downstream tasks and simultaneously improves robustness and generalizability compared to prior approaches. Qualitative experiments are available at: url{https://hgaurav2k.github.io/hop/}.
Read more9/14/2024

0
Exploring the Potential of Robot-Collected Data for Training Gesture Classification Systems
Alejandro Garcia-Sosa, Jose J. Quintana-Hernandez, Miguel A. Ferrer Ballester, Cristina Carmona-Duarte
Sensors and Artificial Intelligence (AI) have revolutionized the analysis of human movement, but the scarcity of specific samples presents a significant challenge in training intelligent systems, particularly in the context of diagnosing neurodegenerative diseases. This study investigates the feasibility of utilizing robot-collected data to train classification systems traditionally trained with human-collected data. As a proof of concept, we recorded a database of numeric characters using an ABB robotic arm and an Apple Watch. We compare the classification performance of the trained systems using both human-recorded and robot-recorded data. Our primary objective is to determine the potential for accurate identification of human numeric characters wearing a smartwatch using robotic movement as training data. The findings of this study offer valuable insights into the feasibility of using robot-collected data for training classification systems. This research holds broad implications across various domains that require reliable identification, particularly in scenarios where access to human-specific data is limited.
Read more5/8/2024