MapCoder: Multi-Agent Code Generation for Competitive Problem Solving
2405.11403
0
0
Abstract
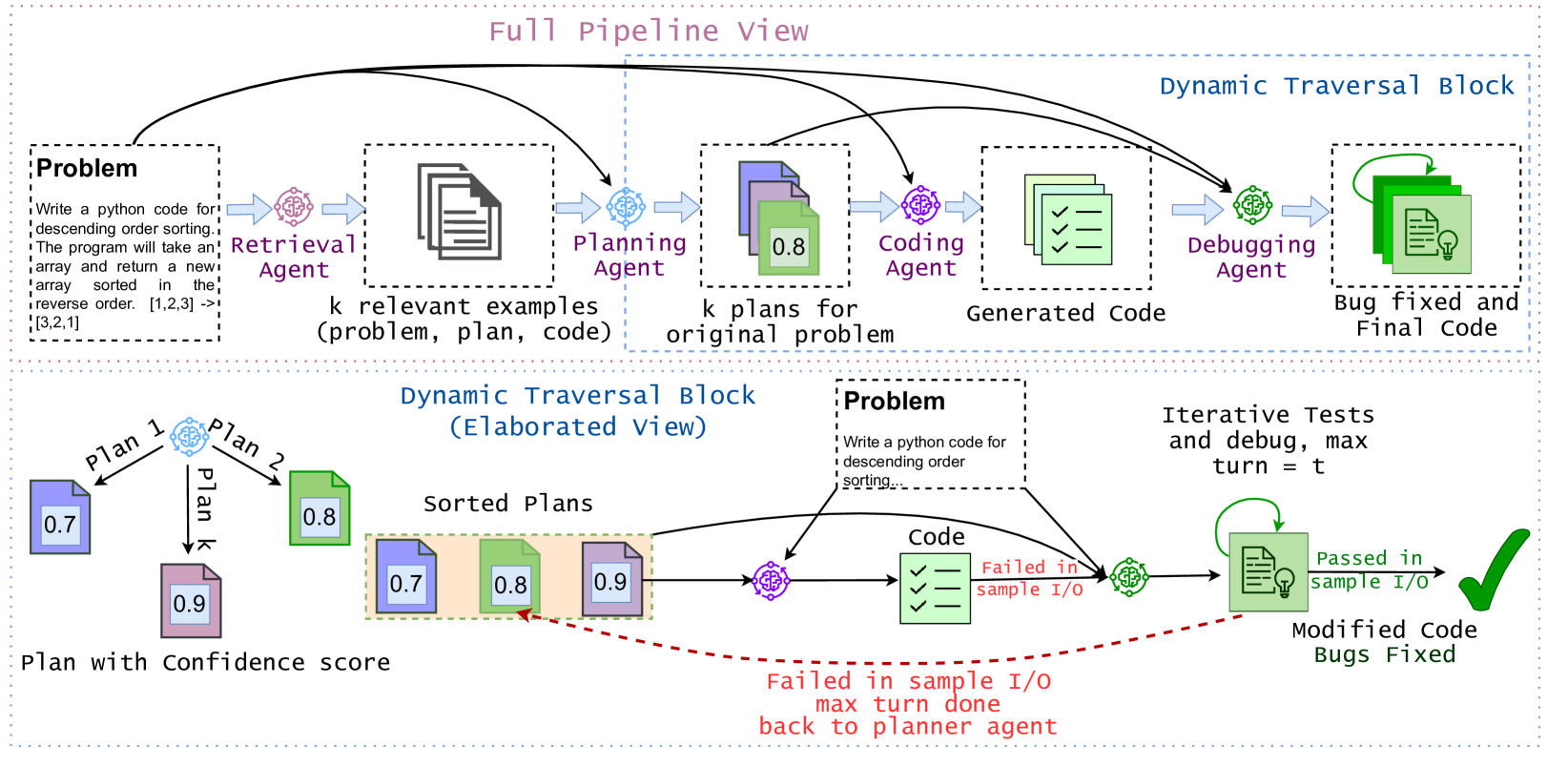
Code synthesis, which requires a deep understanding of complex natural language problem descriptions, generation of code instructions for complex algorithms and data structures, and the successful execution of comprehensive unit tests, presents a significant challenge. While large language models (LLMs) demonstrate impressive proficiency in natural language processing, their performance in code generation tasks remains limited. In this paper, we introduce a new approach to code generation tasks leveraging multi-agent prompting that uniquely replicates the full cycle of program synthesis as observed in human developers. Our framework, MapCoder, consists of four LLM agents specifically designed to emulate the stages of this cycle: recalling relevant examples, planning, code generation, and debugging. After conducting thorough experiments, with multiple LLM ablations and analyses across eight challenging competitive problem-solving and program synthesis benchmarks, MapCoder showcases remarkable code generation capabilities, achieving new state-of-the-art results (pass@1) on HumanEval (93.9%), MBPP (83.1%), APPS (22.0%), CodeContests (28.5%), and xCodeEval (45.3%). Moreover, our method consistently delivers superior performance across various programming languages and varying problem difficulties. We open-source our framework at https://github.com/Md-Ashraful-Pramanik/MapCoder.
Create account to get full access
Overview
- Presents MapCoder, a multi-agent system for generating code to solve competitive programming problems
- Leverages a novel approach to coordinate multiple AI agents to collaboratively produce high-performing code
- Aims to advance the state-of-the-art in automated code generation for competitive problem solving
Plain English Explanation
The paper introduces MapCoder, a system that uses multiple AI agents working together to generate code that can solve competitive programming challenges. Competitive programming involves solving complex algorithmic problems under strict time constraints, and is often used in programming competitions and technical job interviews.
Traditionally, automated code generation has relied on a single AI model to produce the entire solution. MapCoder takes a different approach by coordinating multiple AI agents, each with a specialized task, to collaboratively generate high-performing code. This novel multi-agent architecture allows the system to tackle problems more effectively than a single model could on its own.
The key insight is that breaking down the code generation process into smaller, modular tasks and having different agents focus on each part can lead to better overall results. For example, one agent might be responsible for understanding the problem statement and formulating a high-level solution strategy, while another agent focuses on translating that strategy into efficient, syntactically-correct code.
By leveraging the complementary strengths of these specialized agents, MapCoder aims to generate code that can outperform solutions produced by state-of-the-art single-agent systems. This could have significant implications for advancing the field of automated problem solving and assisting humans in competitive programming challenges.
Technical Explanation
The MapCoder system is built on a multi-agent architecture, where each agent has a specific role in the code generation process. The agents communicate and collaborate to produce high-performing solutions to competitive programming problems.
The key components of the MapCoder system include:
- Problem Understanding Agent: Responsible for comprehending the problem statement and formulating a high-level solution strategy.
- Code Generation Agent: Translates the solution strategy into efficient, syntactically-correct code.
- Evaluation Agent: Assesses the performance of the generated code and provides feedback to the other agents.
- Coordination Agent: Oversees the communication and collaboration between the specialized agents.
The agents iteratively refine the code generation process, with the Evaluation Agent providing feedback to the other agents to help them improve their outputs. This collaborative approach allows MapCoder to generate code that outperforms solutions produced by single-agent systems, as demonstrated through experiments on a range of competitive programming problems.
The paper also explores techniques for training the individual agents, such as the use of pre-trained language models, reinforcement learning, and multi-task learning. These advanced machine learning methods enable the agents to acquire the necessary skills and knowledge to work effectively as a team.
Critical Analysis
The MapCoder paper presents a novel and promising approach to automated code generation for competitive programming. By leveraging a multi-agent architecture, the system can break down the complex task of code generation into more manageable subtasks, allowing each agent to specialize and contribute its unique expertise.
One potential limitation of the MapCoder approach is the complexity involved in training and coordinating the multiple agents. Ensuring effective communication and collaboration between the agents may pose challenges, especially as the system scales to handle more complex problems. The paper acknowledges this challenge and suggests further research into more sophisticated coordination mechanisms.
Additionally, the paper focuses on evaluating MapCoder on a set of competitive programming problems, which may not capture the full range of real-world coding challenges. Further research could explore the system's performance on a broader set of programming tasks, including those encountered in software development and engineering.
Despite these potential limitations, the MapCoder paper represents a significant step forward in the field of automated code generation. By taking a multi-agent approach, the system demonstrates the potential for AI-powered systems to collaborate and generate high-quality code solutions, which could have far-reaching implications for the future of programming and problem-solving.
Conclusion
The MapCoder paper introduces a novel multi-agent system for generating code to solve competitive programming problems. By coordinating the efforts of specialized agents, the system can outperform single-agent approaches and advance the state-of-the-art in automated code generation.
The paper's key contributions include the multi-agent architecture, the techniques for training the individual agents, and the experimental results demonstrating the system's superior performance on a range of competitive programming challenges.
While the MapCoder approach shows promise, further research is needed to address the challenges of agent coordination and to explore the system's applicability to a broader set of programming tasks. Nonetheless, this work represents an exciting step forward in the quest to develop AI-powered systems that can assist and augment human programmers in solving complex problems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
AgentCoder: Multi-Agent-based Code Generation with Iterative Testing and Optimisation
Dong Huang, Jie M. Zhang, Michael Luck, Qingwen Bu, Yuhao Qing, Heming Cui
0
0
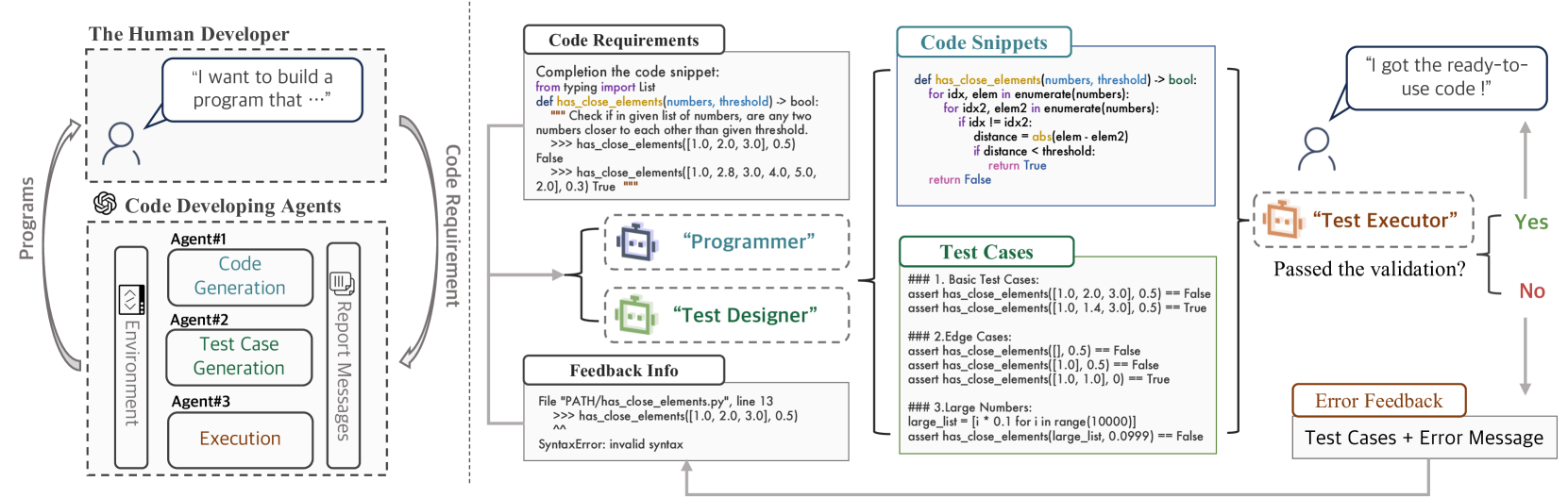
The advancement of natural language processing (NLP) has been significantly boosted by the development of transformer-based large language models (LLMs). These models have revolutionized NLP tasks, particularly in code generation, aiding developers in creating software with enhanced efficiency. Despite their advancements, challenges in balancing code snippet generation with effective test case generation and execution persist. To address these issues, this paper introduces Multi-Agent Assistant Code Generation (AgentCoder), a novel solution comprising a multi-agent framework with specialized agents: the programmer agent, the test designer agent, and the test executor agent. During the coding procedure, the programmer agent will focus on the code generation and refinement based on the test executor agent's feedback. The test designer agent will generate test cases for the generated code, and the test executor agent will run the code with the test cases and write the feedback to the programmer. This collaborative system ensures robust code generation, surpassing the limitations of single-agent models and traditional methodologies. Our extensive experiments on 9 code generation models and 12 enhancement approaches showcase AgentCoder's superior performance over existing code generation models and prompt engineering techniques across various benchmarks. For example, AgentCoder (GPT-4) achieves 96.3% and 91.8% pass@1 in HumanEval and MBPP datasets with an overall token overhead of 56.9K and 66.3K, while state-of-the-art obtains only 90.2% and 78.9% pass@1 with an overall token overhead of 138.2K and 206.5K.
5/27/2024

Code Agents are State of the Art Software Testers
Niels Mundler, Mark Niklas Muller, Jingxuan He, Martin Vechev
0
0
Rigorous software testing is crucial for developing and maintaining high-quality code, making automated test generation a promising avenue for both improving software quality and boosting the effectiveness of code generation methods. However, while code generation with Large Language Models (LLMs) is an extraordinarily active research area, test generation remains relatively unexplored. We address this gap and investigate the capability of LLM-based Code Agents for formalizing user issues into test cases. To this end, we propose a novel benchmark based on popular GitHub repositories, containing real-world issues, ground-truth patches, and golden tests. We find that LLMs generally perform surprisingly well at generating relevant test cases with Code Agents designed for code repair exceeding the performance of systems designed specifically for test generation. Further, as test generation is a similar but more structured task than code generation, it allows for a more fine-grained analysis using fail-to-pass rate and coverage metrics, providing a dual metric for analyzing systems designed for code repair. Finally, we find that generated tests are an effective filter for proposed code fixes, doubling the precision of SWE-Agent.
6/21/2024
🌀
Exploring LLM Multi-Agents for ICD Coding
Rumeng Li, Xun Wang, Hong Yu
0
0
Large Language Models (LLMs) have demonstrated impressive and diverse abilities that can benefit various domains, such as zero and few-shot information extraction from clinical text without domain-specific training. However, for the ICD coding task, they often hallucinate key details and produce high recall but low precision results due to the high-dimensional and skewed distribution of the ICD codes. Existing LLM-based methods fail to account for the complex and dynamic interactions among the human agents involved in coding, such as patients, physicians, and coders, and they lack interpretability and reliability. In this paper, we present a novel multi-agent method for ICD coding, which mimics the real-world coding process with five agents: a patient agent, a physician agent, a coder agent, a reviewer agent, and an adjuster agent. Each agent has a specific function and uses a LLM-based model to perform it. We evaluate our method on the MIMIC-III dataset and show that our proposed multi-agent coding framework substantially improves performance on both common and rare codes compared to Zero-shot Chain of Thought (CoT) prompting and self-consistency with CoT. The ablation study confirms the proposed agent roles' efficacy. Our method also matches the state-of-the-art ICD coding methods that require pre-training or fine-tuning, in terms of coding accuracy, rare code accuracy, and explainability.
6/26/2024

Enhancing Repository-Level Code Generation with Integrated Contextual Information
Zhiyuan Pan, Xing Hu, Xin Xia, Xiaohu Yang
0
0
Large language models (LLMs) have demonstrated remarkable capabilities in code generation tasks. However, repository-level code generation presents unique challenges, particularly due to the need to utilize information spread across multiple files within a repository. Existing retrieval-based approaches sometimes fall short as they are limited in obtaining a broader and deeper repository context. In this paper, we present CatCoder, a novel code generation framework designed for statically typed programming languages. CatCoder enhances repository-level code generation by integrating relevant code and type context. Specifically, it leverages static analyzers to extract type dependencies and merges this information with retrieved code to create comprehensive prompts for LLMs. To evaluate the effectiveness of CatCoder, we adapt and construct benchmarks that include 199 Java tasks and 90 Rust tasks. The results show that CatCoder outperforms the RepoCoder baseline by up to 17.35%, in terms of pass@k score. Furthermore, the generalizability of CatCoder is assessed using various LLMs, including both code-specialized models and general-purpose models. Our findings indicate consistent performance improvements across all models, which underlines the practicality of CatCoder.
6/6/2024