MARVEL: Multidimensional Abstraction and Reasoning through Visual Evaluation and Learning
2404.13591
0
0

Abstract
While multi-modal large language models (MLLMs) have shown significant progress on many popular visual reasoning benchmarks, whether they possess abstract visual reasoning abilities remains an open question. Similar to the Sudoku puzzles, abstract visual reasoning (AVR) problems require finding high-level patterns (e.g., repetition constraints) that control the input shapes (e.g., digits) in a specific task configuration (e.g., matrix). However, existing AVR benchmarks only considered a limited set of patterns (addition, conjunction), input shapes (rectangle, square), and task configurations (3 by 3 matrices). To evaluate MLLMs' reasoning abilities comprehensively, we introduce MARVEL, a multidimensional AVR benchmark with 770 puzzles composed of six core knowledge patterns, geometric and abstract shapes, and five different task configurations. To inspect whether the model accuracy is grounded in perception and reasoning, MARVEL complements the general AVR question with perception questions in a hierarchical evaluation framework. We conduct comprehensive experiments on MARVEL with nine representative MLLMs in zero-shot and few-shot settings. Our experiments reveal that all models show near-random performance on the AVR question, with significant performance gaps (40%) compared to humans across all patterns and task configurations. Further analysis of perception questions reveals that MLLMs struggle to comprehend the visual features (near-random performance) and even count the panels in the puzzle ( <45%), hindering their ability for abstract reasoning. We release our entire code and dataset.
Create account to get full access
Overview
- This paper introduces MARVEL, a framework for Multidimensional Abstraction and Reasoning through Visual Evaluation and Learning.
- MARVEL aims to enable large language models to perform complex reasoning tasks involving visual information, going beyond simple image classification or captioning.
- The framework combines large language models with visual reasoning capabilities to tackle tasks like text-based reasoning about vector graphics, evaluating multi-modal code, and puzzle solving using reasoning.
Plain English Explanation
MARVEL is a new system that allows large language models like BLINK to work with visual information in a more sophisticated way. Rather than just identifying objects in images or generating captions, MARVEL can help these models reason about complex visual information and use it to solve problems.
For example, MARVEL could allow a language model to understand the rules and structure of a vector graphic, and then use that understanding to answer questions or complete tasks related to the graphic. Or it could let the model analyze code that includes both text and visual components, and evaluate whether the code is working correctly.
The key idea behind MARVEL is to combine the powerful natural language processing capabilities of large language models with new visual reasoning skills. This allows the models to tackle a wider range of tasks that require understanding both language and visual information, going beyond what current models are typically able to do.
Technical Explanation
MARVEL is a framework that integrates large language models with visual reasoning capabilities to enable complex reasoning about visual information. The approach involves several key components:
-
Visual Representation Learning: MARVEL uses pretraining techniques to learn rich visual representations that capture the structure, semantics, and relationships within visual inputs. This goes beyond simple object detection or classification.
-
Multimodal Reasoning: The framework combines the learned visual representations with the language understanding capabilities of large language models. This allows the models to reason about visual information in the context of language-based queries or tasks.
-
Task-Specific Adaptation: MARVEL can be fine-tuned on specific task datasets to adapt the multimodal reasoning capabilities to the requirements of different applications, such as text-based reasoning about vector graphics, evaluating multi-modal code, or puzzle solving using reasoning.
The experiments in the paper demonstrate MARVEL's ability to outperform state-of-the-art models on a range of multimodal reasoning benchmarks, showcasing its potential to advance the field of beyond-accuracy evaluations of reasoning behavior in large language models.
Critical Analysis
The MARVEL framework represents an important step forward in integrating visual reasoning capabilities with large language models. However, the paper also acknowledges some limitations and areas for further research:
-
The current implementation of MARVEL relies on specific pretraining and fine-tuning datasets, which may limit its generalization to broader real-world scenarios. Exploring more diverse and unconstrained visual reasoning tasks could help address this.
-
The paper does not provide a detailed analysis of the types of reasoning and cognitive processes that MARVEL is able to capture. A deeper understanding of the model's inner workings and limitations could inform future improvements.
-
While MARVEL demonstrates strong performance on benchmark tasks, its real-world impact will depend on how well the framework can be scaled and deployed in practical applications. Addressing engineering challenges around model size, inference speed, and robustness will be crucial.
Overall, MARVEL is a promising approach that showcases the potential for large language models to engage in more sophisticated reasoning about visual information. Further research and development in this area could lead to significant advancements in the field of multimodal AI.
Conclusion
The MARVEL framework represents an important step forward in bridging the gap between large language models and visual reasoning capabilities. By integrating these two key components, MARVEL enables models to tackle a wider range of complex tasks that require understanding and reasoning about both language and visual information.
The framework's strong performance on multimodal reasoning benchmarks, as well as its potential for adaptation to specific applications, suggests that MARVEL could have significant implications for the development of more advanced and capable AI systems. As the field of multimodal AI continues to evolve, research like this will be crucial in pushing the boundaries of what language models can accomplish.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

A Unified View of Abstract Visual Reasoning Problems
Miko{l}aj Ma{l}ki'nski, Jacek Ma'ndziuk
0
0
The field of Abstract Visual Reasoning (AVR) encompasses a wide range of problems, many of which are inspired by human IQ tests. The variety of AVR tasks has resulted in state-of-the-art AVR methods being task-specific approaches. Furthermore, contemporary methods consider each AVR problem instance not as a whole, but in the form of a set of individual panels with particular locations and roles (context vs. answer panels) pre-assigned according to the task-specific arrangements. While these highly specialized approaches have recently led to significant progress in solving particular AVR tasks, considering each task in isolation hinders the development of universal learning systems in this domain. In this paper, we introduce a unified view of AVR tasks, where each problem instance is rendered as a single image, with no a priori assumptions about the number of panels, their location, or role. The main advantage of the proposed unified view is the ability to develop universal learning models applicable to various AVR tasks. What is more, the proposed approach inherently facilitates transfer learning in the AVR domain, as various types of problems share a common representation. The experiments conducted on four AVR datasets with Raven's Progressive Matrices and Visual Analogy Problems, and one real-world visual analogy dataset show that the proposed unified representation of AVR tasks poses a challenge to state-of-the-art Deep Learning (DL) AVR models and, more broadly, contemporary DL image recognition methods. In order to address this challenge, we introduce the Unified Model for Abstract Visual Reasoning (UMAVR) capable of dealing with various types of AVR problems in a unified manner. UMAVR outperforms existing AVR methods in selected single-task learning experiments, and demonstrates effective knowledge reuse in transfer learning and curriculum learning setups.
6/18/2024
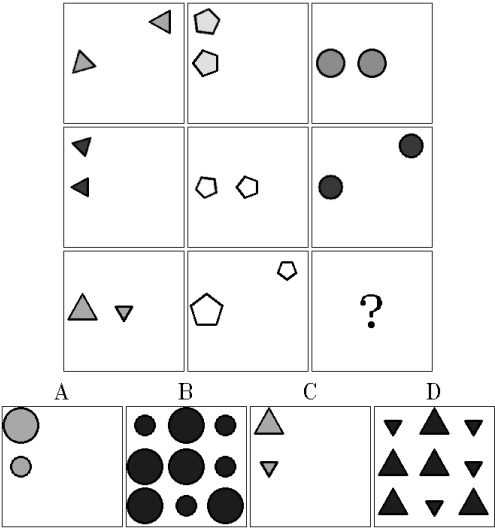
What is the Visual Cognition Gap between Humans and Multimodal LLMs?
Xu Cao, Bolin Lai, Wenqian Ye, Yunsheng Ma, Joerg Heintz, Jintai Chen, Jianguo Cao, James M. Rehg
0
0
Recently, Multimodal Large Language Models (MLLMs) have shown great promise in language-guided perceptual tasks such as recognition, segmentation, and object detection. However, their effectiveness in addressing visual cognition problems that require high-level reasoning is not well-established. One such challenge is abstract visual reasoning (AVR) -- the cognitive ability to discern relationships among patterns in a set of images and extrapolate to predict subsequent patterns. This skill is crucial during the early neurodevelopmental stages of children. Inspired by the AVR tasks in Raven's Progressive Matrices (RPM) and Wechsler Intelligence Scale for Children (WISC), we propose a new dataset MaRs-VQA and a new benchmark VCog-Bench containing three datasets to evaluate the zero-shot AVR capability of MLLMs and compare their performance with existing human intelligent investigation. Our comparative experiments with different open-source and closed-source MLLMs on the VCog-Bench revealed a gap between MLLMs and human intelligence, highlighting the visual cognitive limitations of current MLLMs. We believe that the public release of VCog-Bench, consisting of MaRs-VQA, and the inference pipeline will drive progress toward the next generation of MLLMs with human-like visual cognition abilities.
6/18/2024

PuzzleVQA: Diagnosing Multimodal Reasoning Challenges of Language Models with Abstract Visual Patterns
Yew Ken Chia, Vernon Toh Yan Han, Deepanway Ghosal, Lidong Bing, Soujanya Poria
0
0
Large multimodal models extend the impressive capabilities of large language models by integrating multimodal understanding abilities. However, it is not clear how they can emulate the general intelligence and reasoning ability of humans. As recognizing patterns and abstracting concepts are key to general intelligence, we introduce PuzzleVQA, a collection of puzzles based on abstract patterns. With this dataset, we evaluate large multimodal models with abstract patterns based on fundamental concepts, including colors, numbers, sizes, and shapes. Through our experiments on state-of-the-art large multimodal models, we find that they are not able to generalize well to simple abstract patterns. Notably, even GPT-4V cannot solve more than half of the puzzles. To diagnose the reasoning challenges in large multimodal models, we progressively guide the models with our ground truth reasoning explanations for visual perception, inductive reasoning, and deductive reasoning. Our systematic analysis finds that the main bottlenecks of GPT-4V are weaker visual perception and inductive reasoning abilities. Through this work, we hope to shed light on the limitations of large multimodal models and how they can better emulate human cognitive processes in the future (Our data and code will be released publicly at https://github.com/declare-lab/LLM-PuzzleTest).
5/2/2024
Generalization and Knowledge Transfer in Abstract Visual Reasoning Models
Miko{l}aj Ma{l}ki'nski, Jacek Ma'ndziuk
0
0
We study generalization and knowledge reuse capabilities of deep neural networks in the domain of abstract visual reasoning (AVR), employing Raven's Progressive Matrices (RPMs), a recognized benchmark task for assessing AVR abilities. Two knowledge transfer scenarios referring to the I-RAVEN dataset are investigated. Firstly, inspired by generalization assessment capabilities of the PGM dataset and popularity of I-RAVEN, we introduce Attributeless-I-RAVEN, a benchmark with four generalization regimes that allow to test generalization of abstract rules applied to held-out attributes. Secondly, we construct I-RAVEN-Mesh, a dataset that enriches RPMs with a novel component structure comprising line-based patterns, facilitating assessment of progressive knowledge acquisition in transfer learning setting. The developed benchmarks reveal shortcomings of the contemporary deep learning models, which we partly address with Pathways of Normalized Group Convolution (PoNG) model, a novel neural architecture for solving AVR tasks. PoNG excels in both presented challenges, as well as the standard I-RAVEN and PGM setups.
6/18/2024