MARVEL: Unlocking the Multi-Modal Capability of Dense Retrieval via Visual Module Plugin
2310.14037
0
0
🧪
Abstract
This paper proposes Multi-modAl Retrieval model via Visual modulE pLugin (MARVEL), which learns an embedding space for queries and multi-modal documents to conduct retrieval. MARVEL encodes queries and multi-modal documents with a unified encoder model, which helps to alleviate the modality gap between images and texts. Specifically, we enable the image understanding ability of the well-trained dense retriever, T5-ANCE, by incorporating the visual module's encoded image features as its inputs. To facilitate the multi-modal retrieval tasks, we build the ClueWeb22-MM dataset based on the ClueWeb22 dataset, which regards anchor texts as queries, and extracts the related text and image documents from anchor-linked web pages. Our experiments show that MARVEL significantly outperforms the state-of-the-art methods on the multi-modal retrieval dataset WebQA and ClueWeb22-MM. MARVEL provides an opportunity to broaden the advantages of text retrieval to the multi-modal scenario. Besides, we also illustrate that the language model has the ability to extract image semantics and partly map the image features to the input word embedding space. All codes are available at https://github.com/OpenMatch/MARVEL.
Create account to get full access
Overview
- The paper proposes a model called MARVEL (Multi-modAl Retrieval model via Visual modulE pLugin) for conducting multi-modal retrieval by learning an embedding space for queries and multi-modal documents.
- MARVEL incorporates the visual understanding abilities of a pre-trained text retrieval model, T5-ANCE, to enable multi-modal retrieval.
- The researchers also introduce a new multi-modal dataset called ClueWeb22-MM based on the ClueWeb22 dataset, which includes anchor texts as queries and related text and image documents.
- Experiments show that MARVEL outperforms existing state-of-the-art methods on multi-modal retrieval tasks.
Plain English Explanation
The researchers have developed a model called MARVEL that can search for and retrieve information from a collection of multi-modal (text and image) documents. This is an important task, as many real-world documents and web pages contain both text and images, and users often want to find information that combines both modalities.
MARVEL works by learning a common "embedding space" that can represent both text queries and the multi-modal documents. This means that the model can understand the semantic relationships between text and images, and use this understanding to find the most relevant documents for a given text-based query.
To achieve this, the researchers built on an existing text retrieval model called T5-ANCE, and added a "visual module" that can extract and understand the meaning of images. This allows MARVEL to consider both the text and visual content of documents when performing retrieval.
The researchers also created a new dataset called ClueWeb22-MM, which contains web pages with both text and images, along with text-based queries derived from the anchor text on those pages. This dataset provides a benchmark for evaluating multi-modal retrieval models like MARVEL.
Through experiments, the researchers showed that MARVEL outperforms other state-of-the-art methods on multi-modal retrieval tasks. This suggests that incorporating visual understanding into text-based retrieval can be a powerful approach for accessing information in the real world, where text and images are often combined.
Technical Explanation
The core idea behind MARVEL is to learn a unified embedding space that can represent both text-based queries and multi-modal (text and image) documents. To do this, the researchers built on the T5-ANCE text retrieval model, which has been pre-trained on large text corpora.
MARVEL extends T5-ANCE by incorporating a "visual module" that can extract and encode the semantic features of images. This allows the model to understand the relationship between the text and visual content of multi-modal documents, and use this understanding to retrieve the most relevant information for a given text-based query.
The researchers also created a new multi-modal dataset called ClueWeb22-MM, which is based on the ClueWeb22 web crawl dataset. ClueWeb22-MM includes anchor texts as queries, and the related text and image documents from the anchor-linked web pages. This dataset provides a benchmark for evaluating multi-modal retrieval approaches like MARVEL.
Experiments on the WebQA and ClueWeb22-MM datasets show that MARVEL significantly outperforms existing state-of-the-art methods for multi-modal retrieval. The researchers attribute this to MARVEL's ability to effectively bridge the "modality gap" between text and images, drawing on the strengths of both the text-based T5-ANCE model and the visual understanding provided by the additional module.
Critical Analysis
The researchers acknowledge several limitations and avenues for future work in the paper. For example, they note that the visual module in MARVEL is still relatively simple, and more advanced computer vision techniques could potentially further improve the model's multi-modal understanding.
Additionally, the ClueWeb22-MM dataset, while a valuable benchmark, is still limited in scope and may not fully capture the diversity of real-world multi-modal information needs. Expanding the dataset or exploring other multi-modal retrieval benchmarks could help further validate the effectiveness of MARVEL.
It's also worth considering how MARVEL's performance might scale to larger, more complex multi-modal corpora, and whether the model's advantages would hold up in such settings. The researchers do not explore these larger-scale scenarios in depth.
Overall, the MARVEL model represents an important step forward in bridging the gap between text-based and multi-modal retrieval. By incorporating visual understanding into a powerful text retrieval architecture, the researchers have demonstrated the potential for multi-modal large language models to enhance our ability to access and understand information in the real world.
Conclusion
The MARVEL model proposed in this paper offers a promising approach to multi-modal retrieval, combining the strengths of text-based retrieval with the ability to understand and leverage visual information. By building on the T5-ANCE model and incorporating a visual module, MARVEL demonstrates significant performance improvements over existing methods on multi-modal retrieval tasks.
This research highlights the potential for modular approaches to integrate visual and textual understanding in large language models, opening up new avenues for multi-modal information retrieval and accessing the wealth of multi-modal data available online and in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
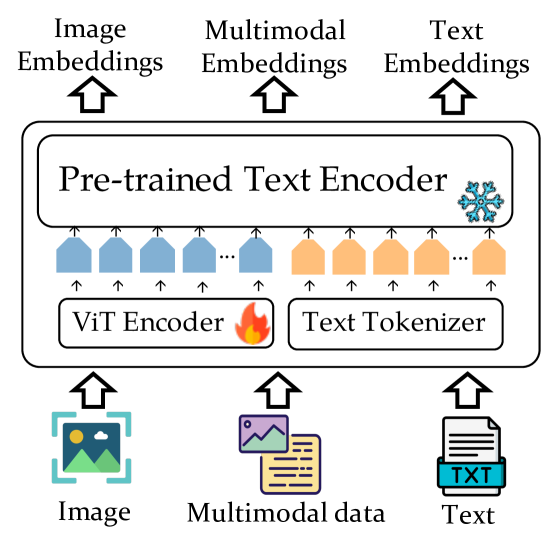
VISTA: Visualized Text Embedding For Universal Multi-Modal Retrieval
Junjie Zhou, Zheng Liu, Shitao Xiao, Bo Zhao, Yongping Xiong
0
0
Multi-modal retrieval becomes increasingly popular in practice. However, the existing retrievers are mostly text-oriented, which lack the capability to process visual information. Despite the presence of vision-language models like CLIP, the current methods are severely limited in representing the text-only and image-only data. In this work, we present a new embedding model VISTA for universal multi-modal retrieval. Our work brings forth threefold technical contributions. Firstly, we introduce a flexible architecture which extends a powerful text encoder with the image understanding capability by introducing visual token embeddings. Secondly, we develop two data generation strategies, which bring high-quality composed image-text to facilitate the training of the embedding model. Thirdly, we introduce a multi-stage training algorithm, which first aligns the visual token embedding with the text encoder using massive weakly labeled data, and then develops multi-modal representation capability using the generated composed image-text data. In our experiments, VISTA achieves superior performances across a variety of multi-modal retrieval tasks in both zero-shot and supervised settings. Our model, data, and source code are available at https://github.com/FlagOpen/FlagEmbedding.
6/7/2024
💬
mPLUG-Owl: Modularization Empowers Large Language Models with Multimodality
Qinghao Ye, Haiyang Xu, Guohai Xu, Jiabo Ye, Ming Yan, Yiyang Zhou, Junyang Wang, Anwen Hu, Pengcheng Shi, Yaya Shi, Chenliang Li, Yuanhong Xu, Hehong Chen, Junfeng Tian, Qi Qian, Ji Zhang, Fei Huang, Jingren Zhou
0
0
Large language models (LLMs) have demonstrated impressive zero-shot abilities on a variety of open-ended tasks, while recent research has also explored the use of LLMs for multi-modal generation. In this study, we introduce mPLUG-Owl, a novel training paradigm that equips LLMs with multi-modal abilities through modularized learning of foundation LLM, a visual knowledge module, and a visual abstractor module. This approach can support multiple modalities and facilitate diverse unimodal and multimodal abilities through modality collaboration. The training paradigm of mPLUG-Owl involves a two-stage method for aligning image and text, which learns visual knowledge with the assistance of LLM while maintaining and even improving the generation abilities of LLM. In the first stage, the visual knowledge module and abstractor module are trained with a frozen LLM module to align the image and text. In the second stage, language-only and multi-modal supervised datasets are used to jointly fine-tune a low-rank adaption (LoRA) module on LLM and the abstractor module by freezing the visual knowledge module. We carefully build a visually-related instruction evaluation set OwlEval. Experimental results show that our model outperforms existing multi-modal models, demonstrating mPLUG-Owl's impressive instruction and visual understanding ability, multi-turn conversation ability, and knowledge reasoning ability. Besides, we observe some unexpected and exciting abilities such as multi-image correlation and scene text understanding, which makes it possible to leverage it for harder real scenarios, such as vision-only document comprehension. Our code, pre-trained model, instruction-tuned models, and evaluation set are available at https://github.com/X-PLUG/mPLUG-Owl. The online demo is available at https://www.modelscope.cn/studios/damo/mPLUG-Owl.
4/1/2024

The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
0
0
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
6/7/2024
🖼️
Category-Oriented Representation Learning for Image to Multi-Modal Retrieval
Zida Cheng, Chen Ju, Shuai Xiao, Xu Chen, Zhonghua Zhai, Xiaoyi Zeng, Weilin Huang, Junchi Yan
0
0
The rise of multi-modal search requests from users has highlighted the importance of multi-modal retrieval (i.e. image-to-text or text-to-image retrieval), yet the more complex task of image-to-multi-modal retrieval, crucial for many industry applications, remains under-explored. To address this gap and promote further research, we introduce and define the concept of Image-to-Multi-Modal Retrieval (IMMR), a process designed to retrieve rich multi-modal (i.e. image and text) documents based on image queries. We focus on representation learning for IMMR and analyze three key challenges for it: 1) skewed data and noisy label in real-world industrial data, 2) the information-inequality between image and text modality of documents when learning representations, 3) effective and efficient training in large-scale industrial contexts. To tackle the above challenges, we propose a novel framework named organizing categories and learning by classification for retrieval (OCLEAR). It consists of three components: 1) a novel category-oriented data governance scheme coupled with a large-scale classification-based learning paradigm, which handles the skewed and noisy data from a data perspective. 2) model architecture specially designed for multi-modal learning, where information-inequality between image and text modality of documents is considered for modality fusion. 3) a hybrid parallel training approach for tackling large-scale training in industrial scenario. The proposed framework achieves SOTA performance on public datasets and has been deployed in a real-world industrial e-commence system, leading to significant business growth. Code will be made publicly available.
6/11/2024