Category-Oriented Representation Learning for Image to Multi-Modal Retrieval

0
🖼️
Sign in to get full access
Overview
- The paper introduces the concept of Image-to-Multi-Modal Retrieval (IMMR), which aims to retrieve rich multi-modal (image and text) documents based on image queries.
- The researchers focus on representation learning for IMMR and identify three key challenges: skewed and noisy data, information inequality between image and text modalities, and efficient training at scale.
- To address these challenges, the paper proposes a novel framework called OCLEAR, which includes a category-oriented data governance scheme, a multi-modal learning architecture, and a hybrid parallel training approach.
Plain English Explanation
The paper tackles the problem of image-to-multi-modal retrieval, which is crucial for many real-world applications. This means retrieving relevant multi-modal (image and text) content based on an image query. For example, if you search for an image of a product, the system should return not just the image itself, but also relevant textual information like product descriptions, reviews, and specifications.
The researchers identify three key challenges in this area:
- Skewed and noisy data: Real-world industrial data is often skewed (e.g., some categories have many more examples than others) and contains noisy or inaccurate labels.
- Information inequality: When learning representations, the image and text modalities of the documents often have unequal amounts of information, which can make it difficult to fuse them effectively.
- Scalability: Efficient training is crucial for deploying these systems in large-scale industrial contexts.
To address these challenges, the researchers propose a framework called OCLEAR. The key ideas are:
- A category-oriented data governance scheme that helps handle the skewed and noisy data.
- A multi-modal learning architecture that is designed to consider the information inequality between image and text.
- A hybrid parallel training approach to enable efficient large-scale training.
The proposed OCLEAR framework has been shown to achieve state-of-the-art performance on public datasets and has been successfully deployed in a real-world industrial e-commerce system, leading to significant business growth.
Technical Explanation
The paper focuses on the task of Image-to-Multi-Modal Retrieval (IMMR), which aims to retrieve rich multi-modal (image and text) documents based on image queries. To address this task, the researchers identify three key challenges:
- Skewed data and noisy labels: Real-world industrial data is often skewed, with some categories having many more examples than others. Additionally, the labels can be noisy or inaccurate.
- Information inequality: When learning representations, the image and text modalities of the documents often have unequal amounts of information, which can make it difficult to fuse them effectively.
- Scalability: Efficient training is crucial for deploying these systems in large-scale industrial contexts.
To tackle these challenges, the researchers propose a novel framework called OCLEAR, which consists of three main components:
- Category-oriented data governance scheme and classification-based learning: The researchers introduce a novel data governance scheme that organizes the data into categories and leverages a large-scale classification-based learning paradigm to handle the skewed and noisy data.
- Multi-modal learning architecture: The researchers design a model architecture that specifically addresses the information inequality between the image and text modalities, using techniques like cross-modal attention and modality-specific encoders.
- Hybrid parallel training: The researchers propose a hybrid parallel training approach that combines data parallelism and model parallelism to enable efficient large-scale training in industrial scenarios.
The proposed OCLEAR framework is evaluated on public datasets and has been deployed in a real-world industrial e-commerce system, leading to significant business growth. The researchers plan to make the code publicly available to promote further research in this area.
Critical Analysis
The paper makes a significant contribution by introducing the novel task of Image-to-Multi-Modal Retrieval (IMMR) and proposing a comprehensive framework to address the key challenges. The researchers have identified important real-world issues, such as skewed and noisy data, information inequality between modalities, and the need for scalable training, that are often overlooked in academic research.
One potential limitation of the study is the lack of a detailed analysis of the individual components of the OCLEAR framework. While the overall system demonstrates strong performance, a deeper dive into the specific impacts of the data governance scheme, multi-modal learning architecture, and hybrid parallel training approach would provide more insights and guidance for future research.
Additionally, the paper does not discuss the potential biases or fairness implications of the IMMR system, which is an important consideration for real-world deployments. As these systems become more widely adopted, it will be crucial to assess and mitigate any unintended biases or inequities in the retrieved multi-modal content.
Overall, the paper presents a compelling and practical solution to an important problem in the field of multi-modal retrieval. The researchers have successfully bridged the gap between academic research and real-world industrial applications, and their work serves as a valuable foundation for further advancements in this area.
Conclusion
The paper introduces the concept of Image-to-Multi-Modal Retrieval (IMMR) and proposes a novel framework called OCLEAR to address the key challenges in this domain. The OCLEAR framework includes innovative techniques for data governance, multi-modal representation learning, and scalable training, which have been shown to achieve state-of-the-art performance on public datasets and have been successfully deployed in a real-world industrial e-commerce system.
This work represents an important step forward in bridging the gap between academic research and practical applications in multi-modal retrieval. The researchers have identified and tackled crucial real-world issues, and their findings can serve as a valuable foundation for further advancements in this area. As the demand for rich, multi-modal content continues to grow, the OCLEAR framework can play a significant role in enabling more effective and efficient image-to-multi-modal retrieval solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Category-Oriented Representation Learning for Image to Multi-Modal Retrieval
Zida Cheng, Chen Ju, Shuai Xiao, Xu Chen, Zhonghua Zhai, Xiaoyi Zeng, Weilin Huang, Junchi Yan
The rise of multi-modal search requests from users has highlighted the importance of multi-modal retrieval (i.e. image-to-text or text-to-image retrieval), yet the more complex task of image-to-multi-modal retrieval, crucial for many industry applications, remains under-explored. To address this gap and promote further research, we introduce and define the concept of Image-to-Multi-Modal Retrieval (IMMR), a process designed to retrieve rich multi-modal (i.e. image and text) documents based on image queries. We focus on representation learning for IMMR and analyze three key challenges for it: 1) skewed data and noisy label in real-world industrial data, 2) the information-inequality between image and text modality of documents when learning representations, 3) effective and efficient training in large-scale industrial contexts. To tackle the above challenges, we propose a novel framework named organizing categories and learning by classification for retrieval (OCLEAR). It consists of three components: 1) a novel category-oriented data governance scheme coupled with a large-scale classification-based learning paradigm, which handles the skewed and noisy data from a data perspective. 2) model architecture specially designed for multi-modal learning, where information-inequality between image and text modality of documents is considered for modality fusion. 3) a hybrid parallel training approach for tackling large-scale training in industrial scenario. The proposed framework achieves SOTA performance on public datasets and has been deployed in a real-world industrial e-commence system, leading to significant business growth. Code will be made publicly available.
Read more6/11/2024

0
OVMR: Open-Vocabulary Recognition with Multi-Modal References
Zehong Ma, Shiliang Zhang, Longhui Wei, Qi Tian
The challenge of open-vocabulary recognition lies in the model has no clue of new categories it is applied to. Existing works have proposed different methods to embed category cues into the model, eg, through few-shot fine-tuning, providing category names or textual descriptions to Vision-Language Models. Fine-tuning is time-consuming and degrades the generalization capability. Textual descriptions could be ambiguous and fail to depict visual details. This paper tackles open-vocabulary recognition from a different perspective by referring to multi-modal clues composed of textual descriptions and exemplar images. Our method, named OVMR, adopts two innovative components to pursue a more robust category cues embedding. A multi-modal classifier is first generated by dynamically complementing textual descriptions with image exemplars. A preference-based refinement module is hence applied to fuse uni-modal and multi-modal classifiers, with the aim to alleviate issues of low-quality exemplar images or textual descriptions. The proposed OVMR is a plug-and-play module, and works well with exemplar images randomly crawled from the Internet. Extensive experiments have demonstrated the promising performance of OVMR, eg, it outperforms existing methods across various scenarios and setups. Codes are publicly available at href{https://github.com/Zehong-Ma/OVMR}{https://github.com/Zehong-Ma/OVMR}.
Read more6/10/2024
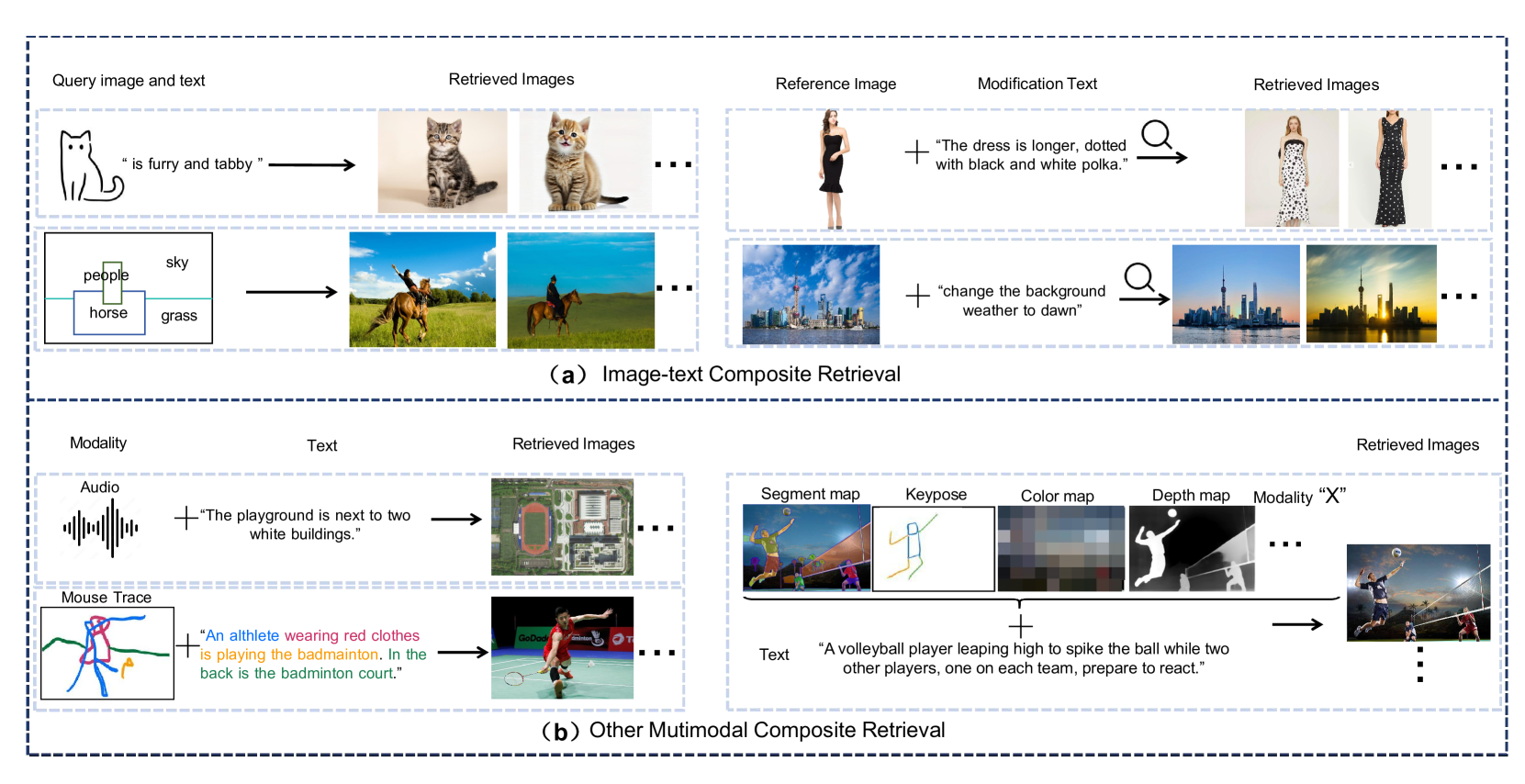
0
A Survey of Multimodal Composite Editing and Retrieval
Suyan Li, Fuxiang Huang, Lei Zhang
In the real world, where information is abundant and diverse across different modalities, understanding and utilizing various data types to improve retrieval systems is a key focus of research. Multimodal composite retrieval integrates diverse modalities such as text, image and audio, etc. to provide more accurate, personalized, and contextually relevant results. To facilitate a deeper understanding of this promising direction, this survey explores multimodal composite editing and retrieval in depth, covering image-text composite editing, image-text composite retrieval, and other multimodal composite retrieval. In this survey, we systematically organize the application scenarios, methods, benchmarks, experiments, and future directions. Multimodal learning is a hot topic in large model era, and have also witnessed some surveys in multimodal learning and vision-language models with transformers published in the PAMI journal. To the best of our knowledge, this survey is the first comprehensive review of the literature on multimodal composite retrieval, which is a timely complement of multimodal fusion to existing reviews. To help readers' quickly track this field, we build the project page for this survey, which can be found at https://github.com/fuxianghuang1/Multimodal-Composite-Editing-and-Retrieval.
Read more9/12/2024

0
Rethinking Sparse Lexical Representations for Image Retrieval in the Age of Rising Multi-Modal Large Language Models
Kengo Nakata, Daisuke Miyashita, Youyang Ng, Yasuto Hoshi, Jun Deguchi
In this paper, we rethink sparse lexical representations for image retrieval. By utilizing multi-modal large language models (M-LLMs) that support visual prompting, we can extract image features and convert them into textual data, enabling us to utilize efficient sparse retrieval algorithms employed in natural language processing for image retrieval tasks. To assist the LLM in extracting image features, we apply data augmentation techniques for key expansion and analyze the impact with a metric for relevance between images and textual data. We empirically show the superior precision and recall performance of our image retrieval method compared to conventional vision-language model-based methods on the MS-COCO, PASCAL VOC, and NUS-WIDE datasets in a keyword-based image retrieval scenario, where keywords serve as search queries. We also demonstrate that the retrieval performance can be improved by iteratively incorporating keywords into search queries.
Read more8/30/2024