VISTA: Visualized Text Embedding For Universal Multi-Modal Retrieval
2406.04292
0
0
Abstract
Multi-modal retrieval becomes increasingly popular in practice. However, the existing retrievers are mostly text-oriented, which lack the capability to process visual information. Despite the presence of vision-language models like CLIP, the current methods are severely limited in representing the text-only and image-only data. In this work, we present a new embedding model VISTA for universal multi-modal retrieval. Our work brings forth threefold technical contributions. Firstly, we introduce a flexible architecture which extends a powerful text encoder with the image understanding capability by introducing visual token embeddings. Secondly, we develop two data generation strategies, which bring high-quality composed image-text to facilitate the training of the embedding model. Thirdly, we introduce a multi-stage training algorithm, which first aligns the visual token embedding with the text encoder using massive weakly labeled data, and then develops multi-modal representation capability using the generated composed image-text data. In our experiments, VISTA achieves superior performances across a variety of multi-modal retrieval tasks in both zero-shot and supervised settings. Our model, data, and source code are available at https://github.com/FlagOpen/FlagEmbedding.
Create account to get full access
Overview
- The paper introduces VISTA, a model that aims to improve multi-modal retrieval by learning a shared embedding space between text and images.
- VISTA leverages a novel visualization module to capture the semantic relationships between textual and visual inputs, leading to more effective cross-modal retrieval.
- The model is evaluated on several benchmark datasets, demonstrating competitive performance compared to state-of-the-art approaches.
Plain English Explanation
VISTA is a machine learning model that tries to make it easier to find relevant images and text that go together. It does this by learning a shared 'language' that can represent both text and images in a common way. This shared representation allows the model to better understand the connections between textual and visual information, and use that understanding to retrieve the most relevant content.
For example, if you search for "a dog chasing a ball," VISTA would be able to match that text query to images that depict a dog chasing a ball, even if the images don't contain the exact same words. The key innovation is a visualization module that helps the model learn these cross-modal relationships more effectively.
VISTA has shown promising results on standard benchmarks for multi-modal retrieval, outperforming other state-of-the-art approaches. This suggests the model could be useful for applications like image search, content recommendation, and visual question answering.
Technical Explanation
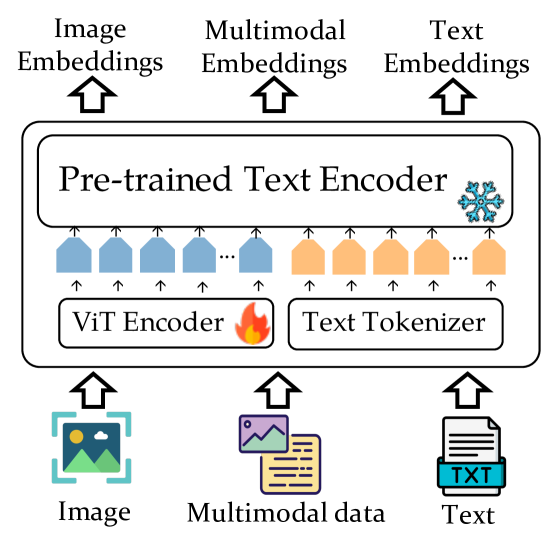
The core idea behind VISTA is to learn a shared embedding space that can effectively represent both textual and visual inputs. This is achieved through a novel architecture that includes a visualization module, which aims to capture the semantic relationships between the two modalities.
The model takes text and image inputs, encodes them using separate transformer-based encoders, and then passes the encoded representations through the visualization module. This module applies a series of convolutional and pooling operations to generate a shared, multi-modal embedding. The authors hypothesize that this visualization-enhanced embedding leads to better cross-modal understanding and retrieval performance.
VISTA is evaluated on several multi-modal retrieval benchmarks, including Flickr30K, COCO, and MS-COCO. The results show that VISTA outperforms or matches the performance of other state-of-the-art approaches, demonstrating the effectiveness of the proposed visualization technique.
Critical Analysis
The paper presents a compelling approach to improving multi-modal retrieval, but there are a few potential limitations and areas for further investigation:
-
The visualization module is relatively complex, and it's not entirely clear how the specific architectural choices impact the model's performance. Further ablation studies could help elucidate the role of different components.
-
The evaluation is limited to standard retrieval benchmarks, which may not fully capture the model's real-world performance. Testing VISTA in more diverse and challenging scenarios, such as interactive image retrieval or open-ended visual question answering, could provide additional insights.
-
The paper does not discuss potential biases or fairness considerations in the model's outputs, which is an important aspect to consider for real-world deployments.
Overall, VISTA represents an interesting and potentially impactful contribution to the field of multi-modal understanding. Further research and careful deployment considerations will be crucial to unlocking the full potential of this type of approach.
Conclusion
The VISTA model introduces a novel visualization-enhanced approach to learning a shared embedding space for text and images, leading to improved performance on multi-modal retrieval tasks. The key innovation is the incorporation of a specialized module that aims to capture the semantic relationships between the two modalities, which appears to be an effective strategy.
While the paper presents promising results, there are still open questions and areas for further investigation, such as the impact of the architectural choices, the model's performance in more diverse scenarios, and potential biases in its outputs. Nonetheless, VISTA represents an important step forward in the quest to build more powerful and versatile multi-modal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👀
Enhancing Vision Models for Text-Heavy Content Understanding and Interaction
Adithya TG, Adithya SK, Abhinav R Bharadwaj, Abhiram HA, Dr. Surabhi Narayan
0
0
Interacting and understanding with text heavy visual content with multiple images is a major challenge for traditional vision models. This paper is on enhancing vision models' capability to comprehend or understand and learn from images containing a huge amount of textual information from the likes of textbooks and research papers which contain multiple images like graphs, etc and tables in them with different types of axes and scales. The approach involves dataset preprocessing, fine tuning which is by using instructional oriented data and evaluation. We also built a visual chat application integrating CLIP for image encoding and a model from the Massive Text Embedding Benchmark which is developed to consider both textual and visual inputs. An accuracy of 96.71% was obtained. The aim of the project is to increase and also enhance the advance vision models' capabilities in understanding complex visual textual data interconnected data, contributing to multimodal AI.
6/3/2024
🧪
MARVEL: Unlocking the Multi-Modal Capability of Dense Retrieval via Visual Module Plugin
Tianshuo Zhou, Sen Mei, Xinze Li, Zhenghao Liu, Chenyan Xiong, Zhiyuan Liu, Yu Gu, Ge Yu
0
0
This paper proposes Multi-modAl Retrieval model via Visual modulE pLugin (MARVEL), which learns an embedding space for queries and multi-modal documents to conduct retrieval. MARVEL encodes queries and multi-modal documents with a unified encoder model, which helps to alleviate the modality gap between images and texts. Specifically, we enable the image understanding ability of the well-trained dense retriever, T5-ANCE, by incorporating the visual module's encoded image features as its inputs. To facilitate the multi-modal retrieval tasks, we build the ClueWeb22-MM dataset based on the ClueWeb22 dataset, which regards anchor texts as queries, and extracts the related text and image documents from anchor-linked web pages. Our experiments show that MARVEL significantly outperforms the state-of-the-art methods on the multi-modal retrieval dataset WebQA and ClueWeb22-MM. MARVEL provides an opportunity to broaden the advantages of text retrieval to the multi-modal scenario. Besides, we also illustrate that the language model has the ability to extract image semantics and partly map the image features to the input word embedding space. All codes are available at https://github.com/OpenMatch/MARVEL.
6/18/2024

ViP-LLaVA: Making Large Multimodal Models Understand Arbitrary Visual Prompts
Mu Cai, Haotian Liu, Dennis Park, Siva Karthik Mustikovela, Gregory P. Meyer, Yuning Chai, Yong Jae Lee
0
0
While existing large vision-language multimodal models focus on whole image understanding, there is a prominent gap in achieving region-specific comprehension. Current approaches that use textual coordinates or spatial encodings often fail to provide a user-friendly interface for visual prompting. To address this challenge, we introduce a novel multimodal model capable of decoding arbitrary visual prompts. This allows users to intuitively mark images and interact with the model using natural cues like a red bounding box or pointed arrow. Our simple design directly overlays visual markers onto the RGB image, eliminating the need for complex region encodings, yet achieves state-of-the-art performance on region-understanding tasks like Visual7W, PointQA, and Visual Commonsense Reasoning benchmark. Furthermore, we present ViP-Bench, a comprehensive benchmark to assess the capability of models in understanding visual prompts across multiple dimensions, enabling future research in this domain. Code, data, and model are publicly available.
4/30/2024

Unified Text-to-Image Generation and Retrieval
Leigang Qu, Haochuan Li, Tan Wang, Wenjie Wang, Yongqi Li, Liqiang Nie, Tat-Seng Chua
0
0
How humans can efficiently and effectively acquire images has always been a perennial question. A typical solution is text-to-image retrieval from an existing database given the text query; however, the limited database typically lacks creativity. By contrast, recent breakthroughs in text-to-image generation have made it possible to produce fancy and diverse visual content, but it faces challenges in synthesizing knowledge-intensive images. In this work, we rethink the relationship between text-to-image generation and retrieval and propose a unified framework in the context of Multimodal Large Language Models (MLLMs). Specifically, we first explore the intrinsic discriminative abilities of MLLMs and introduce a generative retrieval method to perform retrieval in a training-free manner. Subsequently, we unify generation and retrieval in an autoregressive generation way and propose an autonomous decision module to choose the best-matched one between generated and retrieved images as the response to the text query. Additionally, we construct a benchmark called TIGeR-Bench, including creative and knowledge-intensive domains, to standardize the evaluation of unified text-to-image generation and retrieval. Extensive experimental results on TIGeR-Bench and two retrieval benchmarks, i.e., Flickr30K and MS-COCO, demonstrate the superiority and effectiveness of our proposed method.
6/11/2024