Mask as Supervision: Leveraging Unified Mask Information for Unsupervised 3D Pose Estimation

0

Sign in to get full access
Overview
• This paper introduces a novel method for unsupervised 3D pose estimation that leverages unified mask information. • The method, called "Mask as Supervision," learns to predict 3D poses without any 3D ground-truth labels by utilizing the inherent structure and semantics present in 2D masks. • The researchers demonstrate the effectiveness of their approach on several 3D pose estimation benchmarks, showing that it can achieve state-of-the-art performance compared to other unsupervised methods.
Plain English Explanation
• Estimating the 3D pose of a person in an image is an important task in computer vision, with applications in areas like animation, robotics, and virtual reality. • Traditionally, this task has required large datasets of 3D pose annotations, which can be expensive and time-consuming to collect. • This paper presents a new way to tackle 3D pose estimation without needing any 3D ground-truth data. • Instead, the method uses the 2D silhouette or "mask" of the person in the image as a source of supervision. • The key insight is that the 2D mask contains inherent information about the 3D structure of the person's body, which the model can learn to exploit. • By training the model to predict 3D poses that are consistent with the observed 2D masks, the researchers show that it can achieve state-of-the-art performance on 3D pose estimation benchmarks, without requiring any 3D annotations. • This is a significant advance, as it opens up the possibility of 3D pose estimation in scenarios where 3D data is scarce or difficult to obtain.
Technical Explanation
• The "Mask as Supervision" approach [https://aimodels.fyi/papers/arxiv/unsupervised-view-invariant-human-posture-representation] learns a 3D pose estimation model by leveraging the inherent structure and semantics present in 2D masks. • The model is trained to predict 3D joint locations that are consistent with the observed 2D masks, without any 3D ground-truth data. • This is achieved by learning a shared latent representation that encodes both the 2D mask and the corresponding 3D pose. • The model is trained using a combination of reconstruction and adversarial losses, which encourage the predicted 3D poses to align with the observed 2D masks. • The researchers also introduce a novel "mask consistency" loss, which further promotes the coherence between the 2D masks and 3D poses. • Experiments on several 3D pose estimation benchmarks [https://aimodels.fyi/papers/arxiv/semi-supervised-2d-human-pose-estimation-via, https://aimodels.fyi/papers/arxiv/selfpose3d-self-supervised-multi-person-multi-view] demonstrate the effectiveness of the "Mask as Supervision" approach, which outperforms other unsupervised 3D pose estimation methods.
Critical Analysis
• While the "Mask as Supervision" approach is a promising step towards unsupervised 3D pose estimation, the paper acknowledges some limitations. • The method may struggle with complex occlusions or interactions between multiple people, as the 2D mask information may not be sufficient to resolve all the 3D ambiguities. • Additionally, the paper does not address the potential bias or generalization issues that may arise from the reliance on 2D mask data, which may not capture the full complexity of real-world 3D pose variation. • Further research is needed to explore the robustness of the approach to more diverse datasets and scenarios, as well as to investigate potential ways to incorporate additional sources of information [https://aimodels.fyi/papers/arxiv/unified-masked-autoencoder-patchified-skeletons-motion-synthesis, https://aimodels.fyi/papers/arxiv/multi-person-3d-pose-estimation-from-unlabelled] to overcome the limitations of 2D mask-based supervision.
Conclusion
• The "Mask as Supervision" approach presented in this paper is a significant contribution to the field of unsupervised 3D pose estimation. • By leveraging the inherent structure and semantics present in 2D masks, the method can learn to predict 3D poses without the need for expensive 3D ground-truth annotations. • The promising results on benchmark datasets suggest that this approach could be a valuable tool for applications where 3D pose information is required but 3D data is scarce. • Further research to address the identified limitations and explore the broader applicability of the method could lead to even more exciting advancements in this important area of computer vision.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mask as Supervision: Leveraging Unified Mask Information for Unsupervised 3D Pose Estimation
Yuchen Yang, Yu Qiao, Xiao Sun
Automatic estimation of 3D human pose from monocular RGB images is a challenging and unsolved problem in computer vision. In a supervised manner, approaches heavily rely on laborious annotations and present hampered generalization ability due to the limited diversity of 3D pose datasets. To address these challenges, we propose a unified framework that leverages mask as supervision for unsupervised 3D pose estimation. With general unsupervised segmentation algorithms, the proposed model employs skeleton and physique representations that exploit accurate pose information from coarse to fine. Compared with previous unsupervised approaches, we organize the human skeleton in a fully unsupervised way which enables the processing of annotation-free data and provides ready-to-use estimation results. Comprehensive experiments demonstrate our state-of-the-art pose estimation performance on Human3.6M and MPI-INF-3DHP datasets. Further experiments on in-the-wild datasets also illustrate the capability to access more data to boost our model. Code will be available at https://github.com/Charrrrrlie/Mask-as-Supervision.
Read more7/9/2024
🛠️
0
Semi-supervised 2D Human Pose Estimation via Adaptive Keypoint Masking
Kexin Meng, Ruirui Li, Daguang Jiang
Human pose estimation is a fundamental and challenging task in computer vision. Larger-scale and more accurate keypoint annotations, while helpful for improving the accuracy of supervised pose estimation, are often expensive and difficult to obtain. Semi-supervised pose estimation tries to leverage a large amount of unlabeled data to improve model performance, which can alleviate the problem of insufficient labeled samples. The latest semi-supervised learning usually adopts a strong and weak data augmented teacher-student learning framework to deal with the challenge of Human postural diversity and its long-tailed distribution. Appropriate data augmentation method is one of the key factors affecting the accuracy and generalization of semi-supervised models. Aiming at the problem that the difference of sample learning is not considered in the fixed keypoint masking augmentation method, this paper proposes an adaptive keypoint masking method, which can fully mine the information in the samples and obtain better estimation performance. In order to further improve the generalization and robustness of the model, this paper proposes a dual-branch data augmentation scheme, which can perform Mixup on samples and features on the basis of adaptive keypoint masking. The effectiveness of the proposed method is verified on COCO and MPII, outperforming the state-of-the-art semi-supervised pose estimation by 5.2% and 0.3%, respectively.
Read more4/24/2024
🤷
0
Unsupervised View-Invariant Human Posture Representation
Faegheh Sardari, Bjorn Ommer, Majid Mirmehdi
Most recent view-invariant action recognition and performance assessment approaches rely on a large amount of annotated 3D skeleton data to extract view-invariant features. However, acquiring 3D skeleton data can be cumbersome, if not impractical, in in-the-wild scenarios. To overcome this problem, we present a novel unsupervised approach that learns to extract view-invariant 3D human pose representation from a 2D image without using 3D joint data. Our model is trained by exploiting the intrinsic view-invariant properties of human pose between simultaneous frames from different viewpoints and their equivariant properties between augmented frames from the same viewpoint. We evaluate the learned view-invariant pose representations for two downstream tasks. We perform comparative experiments that show improvements on the state-of-the-art unsupervised cross-view action classification accuracy on NTU RGB+D by a significant margin, on both RGB and depth images. We also show the efficiency of transferring the learned representations from NTU RGB+D to obtain the first ever unsupervised cross-view and cross-subject rank correlation results on the multi-view human movement quality dataset, QMAR, and marginally improve on the-state-of-the-art supervised results for this dataset. We also carry out ablation studies to examine the contributions of the different components of our proposed network.
Read more7/9/2024
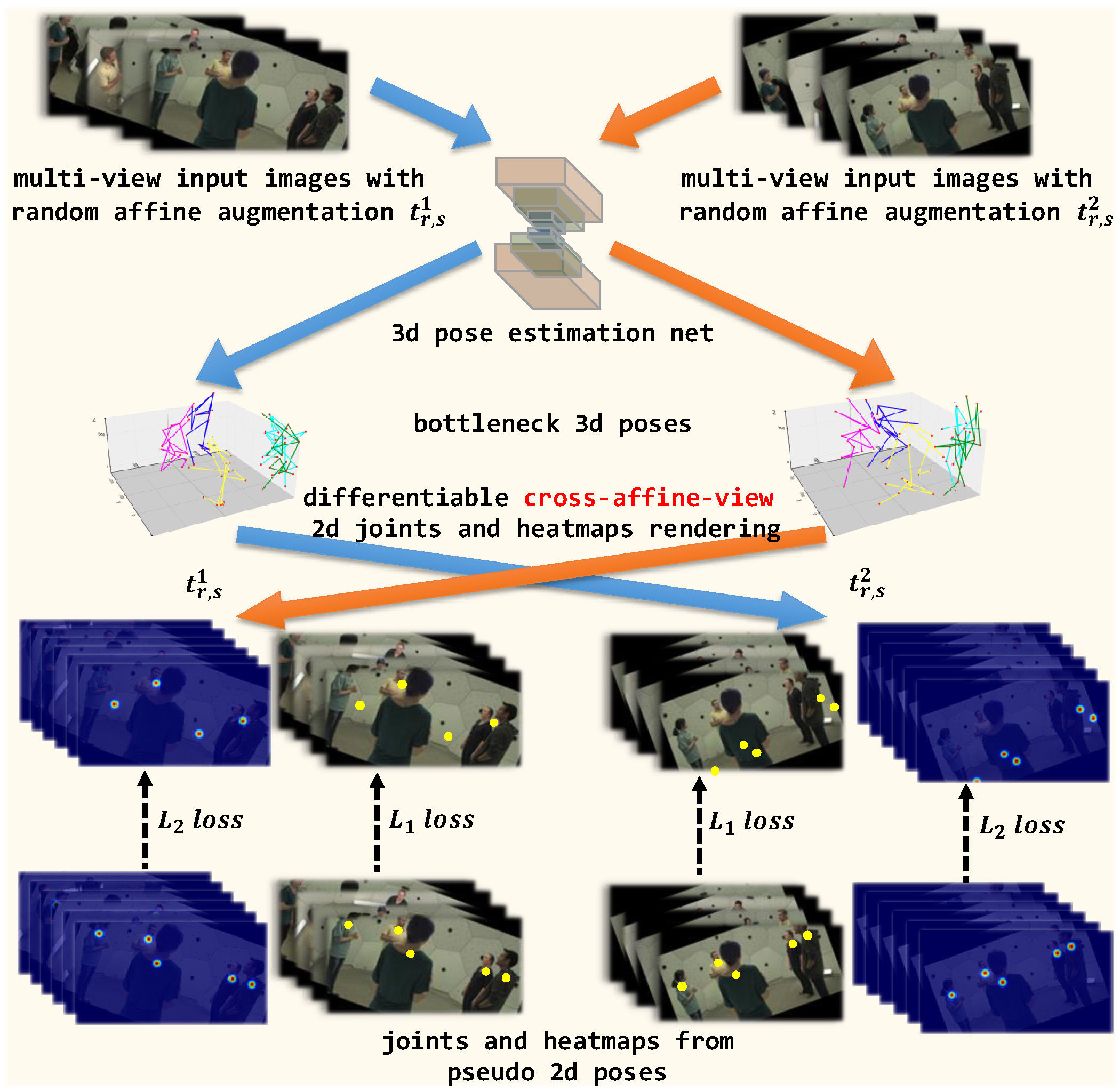
0
SelfPose3d: Self-Supervised Multi-Person Multi-View 3d Pose Estimation
Vinkle Srivastav, Keqi Chen, Nicolas Padoy
We present a new self-supervised approach, SelfPose3d, for estimating 3d poses of multiple persons from multiple camera views. Unlike current state-of-the-art fully-supervised methods, our approach does not require any 2d or 3d ground-truth poses and uses only the multi-view input images from a calibrated camera setup and 2d pseudo poses generated from an off-the-shelf 2d human pose estimator. We propose two self-supervised learning objectives: self-supervised person localization in 3d space and self-supervised 3d pose estimation. We achieve self-supervised 3d person localization by training the model on synthetically generated 3d points, serving as 3d person root positions, and on the projected root-heatmaps in all the views. We then model the 3d poses of all the localized persons with a bottleneck representation, map them onto all views obtaining 2d joints, and render them using 2d Gaussian heatmaps in an end-to-end differentiable manner. Afterwards, we use the corresponding 2d joints and heatmaps from the pseudo 2d poses for learning. To alleviate the intrinsic inaccuracy of the pseudo labels, we propose an adaptive supervision attention mechanism to guide the self-supervision. Our experiments and analysis on three public benchmark datasets, including Panoptic, Shelf, and Campus, show the effectiveness of our approach, which is comparable to fully-supervised methods. Code: https://github.com/CAMMA-public/SelfPose3D. Video demo: https://youtu.be/GAqhmUIr2E8.
Read more6/11/2024