Masked Image Modeling as a Framework for Self-Supervised Learning across Eye Movements
2404.08526
0
0
Abstract
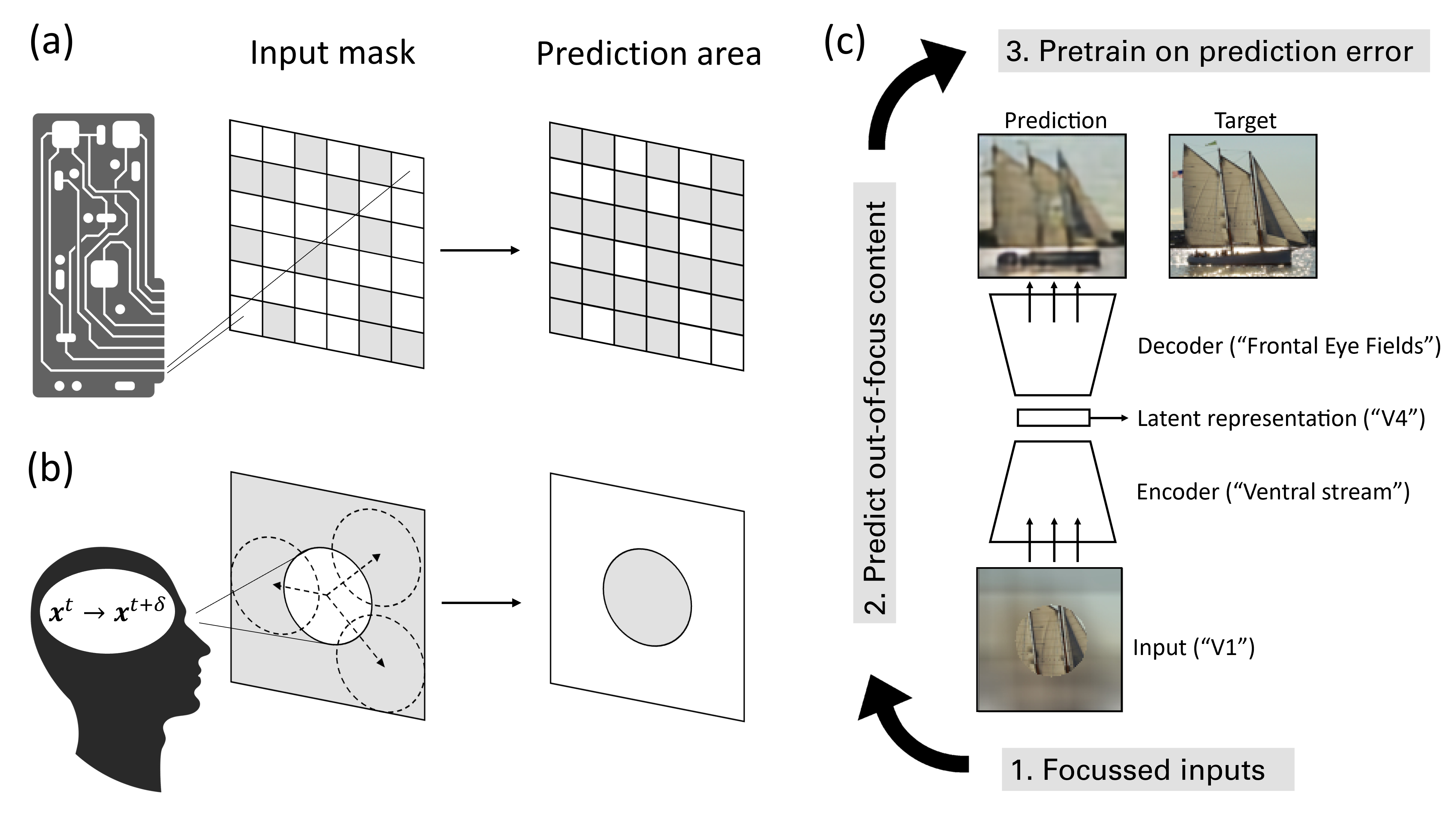
To make sense of their surroundings, intelligent systems must transform complex sensory inputs to structured codes that are reduced to task-relevant information such as object category. Biological agents achieve this in a largely autonomous manner, presumably via self-allowbreak super-allowbreak vised learning. Whereas previous attempts to model the underlying mechanisms were largely discriminative in nature, there is ample evidence that the brain employs a generative model of the world. Here, we propose that eye movements, in combination with the focused nature of primate vision, constitute a generative, self-supervised task of predicting and revealing visual information. We construct a proof-of-principle model starting from the framework of masked image modeling (MIM), a common approach in deep representation learning. To do so, we analyze how core components of MIM such as masking technique and data augmentation influence the formation of category-specific representations. This allows us not only to better understand the principles behind MIM, but to then reassemble a MIM more in line with the focused nature of biological perception. From a theoretical angle, we find that MIM disentangles neurons in latent space, a property that has been suggested to structure visual representations in primates, without explicit regulation. Together with previous findings of invariance learning, this highlights an interesting connection of MIM to latent regularization approaches for self-supervised learning. The source code is available under https://github.com/RobinWeiler/FocusMIM
Create account to get full access
Overview
- The paper proposes a novel framework for self-supervised learning across eye movements using masked image modeling.
- It explores how masked image modeling can be applied to eye movement data to learn useful representations for downstream tasks.
- The framework is evaluated on various eye movement-related tasks, demonstrating its effectiveness in leveraging eye movement data for learning.
Plain English Explanation
The study introduces a new way to train AI systems by having them learn from partial information about images. This is called "masked image modeling," where the AI system is shown an image with some parts hidden, and it has to try to guess what's missing.
The researchers applied this technique to data about how people's eyes move when they look at images. By training the AI system to predict the missing parts of the images based on the eye movement patterns, it can learn useful representations of the visual information that can be applied to other tasks.
This is a form of "self-supervised learning," where the AI system learns useful features from the data itself, without needing extensive human labeling or annotation. The eye movement data provides a rich source of information that the system can leverage to build effective visual representations.
The paper demonstrates how this masked image modeling framework can be applied to various eye movement-related tasks, such as [link to https://aimodels.fyi/papers/arxiv/emerging-property-masked-token-effective-pre-training]predicting human gaze behavior[/link] and [link to https://aimodels.fyi/papers/arxiv/unified-masked-autoencoder-patchified-skeletons-motion-synthesis]synthesizing facial expressions[/link]. By harnessing the power of eye movement data, the researchers show that the AI system can learn powerful visual representations that can be useful for a wide range of applications.
Technical Explanation
The core idea of the paper is to use a masked image modeling approach as a framework for self-supervised learning across eye movement data. The researchers hypothesized that by training an AI system to predict the missing parts of images based on the associated eye movement patterns, the system would learn useful visual representations that could be transferred to other tasks.
The proposed framework involves several key components:
-
[link to https://aimodels.fyi/papers/arxiv/3d-facial-expressions-through-analysis-by-neural]Eye movement data collection and preprocessing[/link]: The researchers used eye tracking devices to record the eye movements of participants as they viewed various images. This data was then preprocessed and organized for use in the masked image modeling task.
-
[link to https://aimodels.fyi/papers/arxiv/i-mae-are-latent-representations-masked-autoencoders]Masked image modeling architecture[/link]: The researchers designed a neural network architecture that takes the eye movement data and the partially obscured image as input, and learns to predict the missing parts of the image. This architecture leverages techniques like [link to https://aimodels.fyi/papers/arxiv/transformer-based-model-prediction-human-gaze-behavior]transformer-based models[/link] to effectively capture the relationship between eye movements and visual information.
-
Training and evaluation: The masked image modeling framework was trained on the eye movement and image data, and then evaluated on a range of eye movement-related tasks, such as gaze behavior prediction and facial expression synthesis. The results demonstrated the effectiveness of this approach in learning useful visual representations from the eye movement data.
Critical Analysis
The researchers acknowledge several limitations and areas for future research in their work:
-
The study was conducted on a relatively small and constrained dataset of eye movement data and images. Evaluating the framework on larger and more diverse datasets could provide a better understanding of its generalization capabilities.
-
The paper focuses on two-dimensional images, but eye movements are closely tied to three-dimensional visual processing. Extending the framework to handle 3D visual data could be an interesting direction for future research.
-
The paper does not explicitly address potential biases or ethical concerns that may arise from using eye movement data for self-supervised learning. Further investigation into these aspects would be valuable.
Despite these limitations, the proposed masked image modeling framework represents a promising approach to leveraging eye movement data for self-supervised learning. By demonstrating the effectiveness of this technique on various eye movement-related tasks, the researchers have opened up new avenues for exploration in the field of computer vision and cognitive science.
Conclusion
The key contribution of this paper is the introduction of a masked image modeling framework for self-supervised learning across eye movement data. By training an AI system to predict missing parts of images based on the associated eye movement patterns, the researchers have shown that it is possible to learn useful visual representations that can be applied to a range of eye movement-related tasks.
This work highlights the potential of harnessing eye movement data as a rich source of information for building more capable and adaptable AI systems. The findings from this study could have significant implications for the development of advanced computer vision and human-computer interaction technologies, as well as for our understanding of the cognitive processes underlying visual perception and attention.
As the field of self-supervised learning continues to evolve, the masked image modeling approach described in this paper could serve as a valuable framework for researchers and practitioners seeking to leverage diverse sources of data, such as eye movements, for building more robust and versatile AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
BIMM: Brain Inspired Masked Modeling for Video Representation Learning
Zhifan Wan, Jie Zhang, Changzhen Li, Shiguang Shan
0
0
The visual pathway of human brain includes two sub-pathways, ie, the ventral pathway and the dorsal pathway, which focus on object identification and dynamic information modeling, respectively. Both pathways comprise multi-layer structures, with each layer responsible for processing different aspects of visual information. Inspired by visual information processing mechanism of the human brain, we propose the Brain Inspired Masked Modeling (BIMM) framework, aiming to learn comprehensive representations from videos. Specifically, our approach consists of ventral and dorsal branches, which learn image and video representations, respectively. Both branches employ the Vision Transformer (ViT) as their backbone and are trained using masked modeling method. To achieve the goals of different visual cortices in the brain, we segment the encoder of each branch into three intermediate blocks and reconstruct progressive prediction targets with light weight decoders. Furthermore, drawing inspiration from the information-sharing mechanism in the visual pathways, we propose a partial parameter sharing strategy between the branches during training. Extensive experiments demonstrate that BIMM achieves superior performance compared to the state-of-the-art methods.
5/22/2024
🖼️
Pre-training with Random Orthogonal Projection Image Modeling
Maryam Haghighat, Peyman Moghadam, Shaheer Mohamed, Piotr Koniusz
0
0
Masked Image Modeling (MIM) is a powerful self-supervised strategy for visual pre-training without the use of labels. MIM applies random crops to input images, processes them with an encoder, and then recovers the masked inputs with a decoder, which encourages the network to capture and learn structural information about objects and scenes. The intermediate feature representations obtained from MIM are suitable for fine-tuning on downstream tasks. In this paper, we propose an Image Modeling framework based on random orthogonal projection instead of binary masking as in MIM. Our proposed Random Orthogonal Projection Image Modeling (ROPIM) reduces spatially-wise token information under guaranteed bound on the noise variance and can be considered as masking entire spatial image area under locally varying masking degrees. Since ROPIM uses a random subspace for the projection that realizes the masking step, the readily available complement of the subspace can be used during unmasking to promote recovery of removed information. In this paper, we show that using random orthogonal projection leads to superior performance compared to crop-based masking. We demonstrate state-of-the-art results on several popular benchmarks.
4/23/2024

Morphing Tokens Draw Strong Masked Image Models
Taekyung Kim, Byeongho Heo, Dongyoon Han
0
0
Masked image modeling (MIM) is a promising option for training Vision Transformers among various self-supervised learning (SSL) methods. The essence of MIM lies in token-wise masked token predictions, with targets tokenized from images or generated by pre-trained models such as vision-language models. While tokenizers or pre-trained models are plausible MIM targets, they often offer spatially inconsistent targets even for neighboring tokens, complicating models to learn unified discriminative representations. Our pilot study confirms that addressing spatial inconsistencies has the potential to enhance representation quality. Motivated by the findings, we introduce a novel self-supervision signal called Dynamic Token Morphing (DTM), which dynamically aggregates contextually related tokens to yield contextualized targets. DTM is compatible with various SSL frameworks; we showcase an improved MIM by employing DTM, barely introducing extra training costs. Our experiments on ImageNet-1K and ADE20K demonstrate the superiority of our methods compared with state-of-the-art, complex MIM methods. Furthermore, the comparative evaluation of the iNaturalists and fine-grained visual classification datasets further validates the transferability of our method on various downstream tasks. Code is available at https://github.com/naver-ai/dtm
5/3/2024
🖼️
Masked Image Modelling for retinal OCT understanding
Theodoros Pissas, Pablo M'arquez-Neila, Sebastian Wolf, Martin Zinkernagel, Raphael Sznitman
0
0
This work explores the effectiveness of masked image modelling for learning representations of retinal OCT images. To this end, we leverage Masked Autoencoders (MAE), a simple and scalable method for self-supervised learning, to obtain a powerful and general representation for OCT images by training on 700K OCT images from 41K patients collected under real world clinical settings. We also provide the first extensive evaluation for a model of OCT on a challenging battery of 6 downstream tasks. Our model achieves strong performance when fully finetuned but can also serve as a versatile frozen feature extractor for many tasks using lightweight adapters. Furthermore, we propose an extension of the MAE pretraining to fuse OCT with an auxiliary modality, namely, IR fundus images and learn a joint model for both. We demonstrate our approach improves performance on a multimodal downstream application. Our experiments utilize most publicly available OCT datasets, thus enabling future comparisons. Our code and model weights are publicly available https://github.com/TheoPis/MIM_OCT.
5/24/2024