BIMM: Brain Inspired Masked Modeling for Video Representation Learning
2405.12757
0
0
🗣️
Abstract
The visual pathway of human brain includes two sub-pathways, ie, the ventral pathway and the dorsal pathway, which focus on object identification and dynamic information modeling, respectively. Both pathways comprise multi-layer structures, with each layer responsible for processing different aspects of visual information. Inspired by visual information processing mechanism of the human brain, we propose the Brain Inspired Masked Modeling (BIMM) framework, aiming to learn comprehensive representations from videos. Specifically, our approach consists of ventral and dorsal branches, which learn image and video representations, respectively. Both branches employ the Vision Transformer (ViT) as their backbone and are trained using masked modeling method. To achieve the goals of different visual cortices in the brain, we segment the encoder of each branch into three intermediate blocks and reconstruct progressive prediction targets with light weight decoders. Furthermore, drawing inspiration from the information-sharing mechanism in the visual pathways, we propose a partial parameter sharing strategy between the branches during training. Extensive experiments demonstrate that BIMM achieves superior performance compared to the state-of-the-art methods.
Create account to get full access
Overview
- The paper proposes a Brain Inspired Masked Modeling (BIMM) framework for learning comprehensive representations from videos.
- BIMM is inspired by the visual information processing mechanism of the human brain, which has two sub-pathways: the ventral pathway for object identification and the dorsal pathway for dynamic information modeling.
- BIMM consists of ventral and dorsal branches that learn image and video representations, respectively, using the Vision Transformer (ViT) as the backbone and a masked modeling method for training.
Plain English Explanation
The human brain has a complex visual processing system with two main pathways: the ventral pathway for identifying objects and the dorsal pathway for modeling dynamic information. These pathways work together to help us understand the world around us.
The researchers behind this paper were inspired by this brain mechanism and developed a new framework called Brain Inspired Masked Modeling (BIMM) to learn comprehensive representations from videos. BIMM has two main components: a ventral branch that learns image representations and a dorsal branch that learns video representations.
Both branches use a type of artificial intelligence model called a Vision Transformer (ViT) as their backbone. They are trained using a technique called masked modeling, where the model has to predict the missing parts of the input. This helps the model learn more robust and meaningful representations.
To further mimic the brain's visual processing, the researchers divided the encoder in each branch into three blocks and used lightweight decoders to reconstruct progressive prediction targets. They also proposed a way for the two branches to share some parameters during training, inspired by the information-sharing mechanism in the brain's visual pathways.
The researchers show that this BIMM framework outperforms other state-of-the-art methods, demonstrating the value of incorporating insights from the human visual system into artificial intelligence models.
Technical Explanation
The proposed Brain Inspired Masked Modeling (BIMM) framework is inspired by the visual information processing mechanism of the human brain, which has two sub-pathways: the ventral pathway for object identification and the dorsal pathway for dynamic information modeling.
BIMM consists of two branches: a ventral branch that learns image representations and a dorsal branch that learns video representations. Both branches use the Vision Transformer (ViT) as their backbone and are trained using a masked modeling method.
To achieve the goals of the different visual cortices in the brain, the researchers segmented the encoder of each branch into three intermediate blocks and used lightweight decoders to reconstruct progressive prediction targets. This allows the model to learn representations at different levels of abstraction.
Furthermore, drawing inspiration from the information-sharing mechanism in the visual pathways, the researchers proposed a partial parameter sharing strategy between the ventral and dorsal branches during training. This helps the model leverage the knowledge learned in one pathway to improve the other.
Extensive experiments demonstrate that BIMM achieves superior performance compared to the state-of-the-art methods on various video understanding tasks, validating the effectiveness of incorporating insights from the human visual system into artificial intelligence models.
Critical Analysis
The paper presents a well-designed and novel approach to video representation learning, drawing inspiration from the human visual system. The segmentation of the encoder and the use of lightweight decoders are interesting ideas that may help the model learn more comprehensive and fine-grained representations.
However, the paper does not provide a detailed analysis of the limitations of the BIMM framework. For example, it would be helpful to understand the computational and memory requirements of the model, as well as any potential trade-offs between the performance gains and the increased complexity.
Additionally, the researchers could have explored the generalization capabilities of BIMM by evaluating its performance on a wider range of video understanding tasks or datasets. This would help assess the robustness and versatility of the proposed approach.
While the paper demonstrates the effectiveness of incorporating insights from the human visual system, it would be valuable to understand the limitations of this approach and identify potential areas for further research and improvement.
Conclusion
The Brain Inspired Masked Modeling (BIMM) framework represents a promising step towards developing artificial intelligence models that can learn comprehensive representations from videos by leveraging insights from the human visual system.
The proposed approach, with its ventral and dorsal branches, segmented encoders, and partial parameter sharing, demonstrates the benefits of incorporating brain-inspired mechanisms into machine learning architectures. The superior performance of BIMM compared to state-of-the-art methods highlights the potential of this research direction.
As the field of computer vision continues to advance, further exploration of the interplay between human and machine vision could lead to even more powerful and versatile AI models that can better understand and interact with the visual world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Masked Image Modeling as a Framework for Self-Supervised Learning across Eye Movements
Robin Weiler, Matthias Brucklacher, Cyriel M. A. Pennartz, Sander M. Boht'e
0
0
To make sense of their surroundings, intelligent systems must transform complex sensory inputs to structured codes that are reduced to task-relevant information such as object category. Biological agents achieve this in a largely autonomous manner, presumably via self-allowbreak super-allowbreak vised learning. Whereas previous attempts to model the underlying mechanisms were largely discriminative in nature, there is ample evidence that the brain employs a generative model of the world. Here, we propose that eye movements, in combination with the focused nature of primate vision, constitute a generative, self-supervised task of predicting and revealing visual information. We construct a proof-of-principle model starting from the framework of masked image modeling (MIM), a common approach in deep representation learning. To do so, we analyze how core components of MIM such as masking technique and data augmentation influence the formation of category-specific representations. This allows us not only to better understand the principles behind MIM, but to then reassemble a MIM more in line with the focused nature of biological perception. From a theoretical angle, we find that MIM disentangles neurons in latent space, a property that has been suggested to structure visual representations in primates, without explicit regulation. Together with previous findings of invariance learning, this highlights an interesting connection of MIM to latent regularization approaches for self-supervised learning. The source code is available under https://github.com/RobinWeiler/FocusMIM
4/15/2024
📈
Biologically-Motivated Learning Model for Instructed Visual Processing
Roy Abel, Shimon Ullman
0
0
As part of understanding how the brain learns, ongoing work seeks to combine biological knowledge and current artificial intelligence (AI) modeling in an attempt to find an efficient biologically plausible learning scheme. Current models of biologically plausible learning often use a cortical-like combination of bottom-up (BU) and top-down (TD) processing, where the TD part carries feedback signals used for learning. However, in the visual cortex, the TD pathway plays a second major role of visual attention, by guiding the visual process to locations and tasks of interest. A biological model should therefore combine the two tasks, and learn to guide the visual process. We introduce a model that uses a cortical-like combination of BU and TD processing that naturally integrates the two major functions of the TD stream. The integrated model is obtained by an appropriate connectivity pattern between the BU and TD streams, a novel processing cycle that uses the TD part twice, and the use of 'Counter-Hebb' learning that operates across the streams. We show that the 'Counter-Hebb' mechanism can provide an exact backpropagation synaptic modification. We further demonstrate the model's ability to guide the visual stream to perform a task of interest, achieving competitive performance compared with AI models on standard multi-task learning benchmarks. The successful combination of learning and visual guidance could provide a new view on combining BU and TD processing in human vision, and suggests possible directions for both biologically plausible models and artificial instructed models, such as vision-language models (VLMs).
6/18/2024

Instruction-Guided Visual Masking
Jinliang Zheng, Jianxiong Li, Sijie Cheng, Yinan Zheng, Jiaming Li, Jihao Liu, Yu Liu, Jingjing Liu, Xianyuan Zhan
0
0
Instruction following is crucial in contemporary LLM. However, when extended to multimodal setting, it often suffers from misalignment between specific textual instruction and targeted local region of an image. To achieve more accurate and nuanced multimodal instruction following, we introduce Instruction-guided Visual Masking (IVM), a new versatile visual grounding model that is compatible with diverse multimodal models, such as LMM and robot model. By constructing visual masks for instruction-irrelevant regions, IVM-enhanced multimodal models can effectively focus on task-relevant image regions to better align with complex instructions. Specifically, we design a visual masking data generation pipeline and create an IVM-Mix-1M dataset with 1 million image-instruction pairs. We further introduce a new learning technique, Discriminator Weighted Supervised Learning (DWSL) for preferential IVM training that prioritizes high-quality data samples. Experimental results on generic multimodal tasks such as VQA and embodied robotic control demonstrate the versatility of IVM, which as a plug-and-play tool, significantly boosts the performance of diverse multimodal models, yielding new state-of-the-art results across challenging multimodal benchmarks. Code is available at https://github.com/2toinf/IVM.
5/31/2024
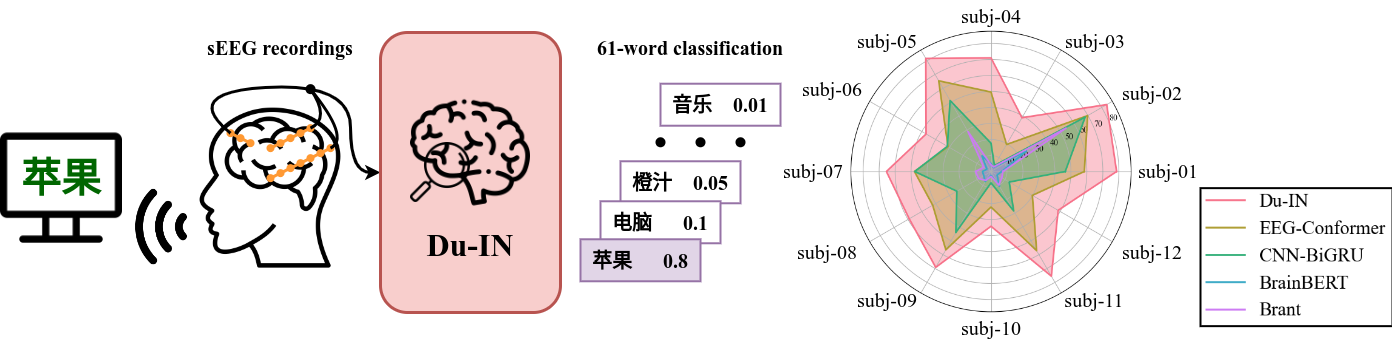
Du-IN: Discrete units-guided mask modeling for decoding speech from Intracranial Neural signals
Hui Zheng, Hai-Teng Wang, Wei-Bang Jiang, Zhong-Tao Chen, Li He, Pei-Yang Lin, Peng-Hu Wei, Guo-Guang Zhao, Yun-Zhe Liu
0
0
Invasive brain-computer interfaces have garnered significant attention due to their high performance. The current intracranial stereoElectroEncephaloGraphy (sEEG) foundation models typically build univariate representations based on a single channel. Some of them further use Transformer to model the relationship among channels. However, due to the locality and specificity of brain computation, their performance on more difficult tasks, e.g., speech decoding, which demands intricate processing in specific brain regions, is yet to be fully investigated. We hypothesize that building multi-variate representations within certain brain regions can better capture the specific neural processing. To explore this hypothesis, we collect a well-annotated Chinese word-reading sEEG dataset, targeting language-related brain networks, over 12 subjects. Leveraging this benchmark dataset, we developed the Du-IN model that can extract contextual embeddings from specific brain regions through discrete codebook-guided mask modeling. Our model achieves SOTA performance on the downstream 61-word classification task, surpassing all baseline models. Model comparison and ablation analysis reveal that our design choices, including (i) multi-variate representation by fusing channels in vSMC and STG regions and (ii) self-supervision by discrete codebook-guided mask modeling, significantly contribute to these performances. Collectively, our approach, inspired by neuroscience findings, capitalizing on multi-variate neural representation from specific brain regions, is suitable for invasive brain modeling. It marks a promising neuro-inspired AI approach in BCI.
5/21/2024