Pre-training with Random Orthogonal Projection Image Modeling
2310.18737
0
0
🖼️
Abstract
Masked Image Modeling (MIM) is a powerful self-supervised strategy for visual pre-training without the use of labels. MIM applies random crops to input images, processes them with an encoder, and then recovers the masked inputs with a decoder, which encourages the network to capture and learn structural information about objects and scenes. The intermediate feature representations obtained from MIM are suitable for fine-tuning on downstream tasks. In this paper, we propose an Image Modeling framework based on random orthogonal projection instead of binary masking as in MIM. Our proposed Random Orthogonal Projection Image Modeling (ROPIM) reduces spatially-wise token information under guaranteed bound on the noise variance and can be considered as masking entire spatial image area under locally varying masking degrees. Since ROPIM uses a random subspace for the projection that realizes the masking step, the readily available complement of the subspace can be used during unmasking to promote recovery of removed information. In this paper, we show that using random orthogonal projection leads to superior performance compared to crop-based masking. We demonstrate state-of-the-art results on several popular benchmarks.
Create account to get full access
Overview
- This paper proposes a new self-supervised approach called Random Orthogonal Projection Image Modeling (ROPIM) for pre-training visual models without using labeled data.
- ROPIM applies random orthogonal projection to input images instead of the binary masking used in other Masked Image Modeling (MIM) techniques.
- The authors show that ROPIM outperforms crop-based masking on several popular benchmarks, leading to state-of-the-art results.
Plain English Explanation
The paper introduces a new way to pre-train computer vision models without using labeled data. This approach, called Random Orthogonal Projection Image Modeling (ROPIM), is an alternative to Masked Image Modeling (MIM) techniques.
In MIM, the model is trained to recover parts of an image that have been randomly hidden or "masked". This encourages the model to learn about the structure and relationships in the image, which can then be useful for other tasks.
ROPIM does something similar, but instead of masking out parts of the image, it reduces the information in the image by projecting it onto a random subspace. This projection preserves the overall structure of the image, but removes some of the detailed information.
The key insight is that the complement of this random subspace can be used to help the model recover the missing information during the training process. This allows the model to learn about the image structure in a more efficient way compared to simple masking.
The authors show that this ROPIM approach outperforms traditional masking techniques on several commonly used benchmarks, leading to state-of-the-art results. This suggests that random orthogonal projection may be a more effective way to train visual models in a self-supervised manner.
Technical Explanation
The paper proposes a new self-supervised pre-training framework called Random Orthogonal Projection Image Modeling (ROPIM). ROPIM is an alternative to Masked Image Modeling (MIM) techniques, where the model is trained to recover randomly masked parts of an input image.
Instead of binary masking, ROPIM applies a random orthogonal projection to the input image. This projection reduces the spatial information in the image, but preserves the overall structure. Importantly, the complement of the random subspace used for the projection can be leveraged during the unmasking/recovery process.
The authors show that this random orthogonal projection approach has several advantages over simple cropping or masking:
- It provides a guaranteed bound on the noise variance introduced by the projection, allowing the model to more effectively learn the underlying image structure.
- The available complement of the projection subspace can be used to promote the recovery of removed information during training, leading to more efficient learning.
- ROPIM can be seen as a way to mask entire spatial regions of the image with varying degrees of masking, rather than just binary masking of individual tokens.
The authors evaluate ROPIM on several popular computer vision benchmarks, including ImageNet, COCO, and ADE20K. They demonstrate that ROPIM outperforms traditional MIM approaches and achieves state-of-the-art results on these tasks.
Critical Analysis
The paper presents a compelling alternative to standard Masked Image Modeling (MIM) techniques for self-supervised pre-training of visual models. The key innovation of using random orthogonal projection instead of binary masking is well-motivated and the authors provide a thorough technical explanation of the potential benefits.
One potential limitation of the ROPIM approach is that the random projection may remove important details from the image that are crucial for certain downstream tasks. The authors acknowledge this and suggest that an adaptive masking strategy could be a promising direction to address this.
Additionally, while the results on standard benchmarks are impressive, it would be valuable to see how ROPIM performs on a wider range of tasks and datasets, including more complex or domain-specific applications. This could help validate the broader applicability of the approach.
Overall, the Image Modeling framework based on random orthogonal projection proposed in this paper represents an interesting and potentially valuable addition to the field of self-supervised visual representation learning. Further exploration and refinement of this technique could lead to significant advancements in how we train powerful computer vision models without the need for extensive labeled data.
Conclusion
This paper introduces a new self-supervised pre-training approach called Random Orthogonal Projection Image Modeling (ROPIM) that outperforms traditional Masked Image Modeling (MIM) techniques. By using random orthogonal projection instead of binary masking, ROPIM is able to more effectively capture the underlying structure of images and facilitate the recovery of removed information during training.
The authors demonstrate that ROPIM achieves state-of-the-art results on several popular computer vision benchmarks, suggesting that this approach may be a valuable contribution to the field of self-supervised visual representation learning. While there are some potential limitations to consider, the core ideas presented in this paper represent an interesting and promising direction for further research and development.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Emerging Property of Masked Token for Effective Pre-training
Hyesong Choi, Hunsang Lee, Seyoung Joung, Hyejin Park, Jiyeong Kim, Dongbo Min
0
0
Driven by the success of Masked Language Modeling (MLM), the realm of self-supervised learning for computer vision has been invigorated by the central role of Masked Image Modeling (MIM) in driving recent breakthroughs. Notwithstanding the achievements of MIM across various downstream tasks, its overall efficiency is occasionally hampered by the lengthy duration of the pre-training phase. This paper presents a perspective that the optimization of masked tokens as a means of addressing the prevailing issue. Initially, we delve into an exploration of the inherent properties that a masked token ought to possess. Within the properties, we principally dedicated to articulating and emphasizing the `data singularity' attribute inherent in masked tokens. Through a comprehensive analysis of the heterogeneity between masked tokens and visible tokens within pre-trained models, we propose a novel approach termed masked token optimization (MTO), specifically designed to improve model efficiency through weight recalibration and the enhancement of the key property of masked tokens. The proposed method serves as an adaptable solution that seamlessly integrates into any MIM approach that leverages masked tokens. As a result, MTO achieves a considerable improvement in pre-training efficiency, resulting in an approximately 50% reduction in pre-training epochs required to attain converged performance of the recent approaches.
4/15/2024
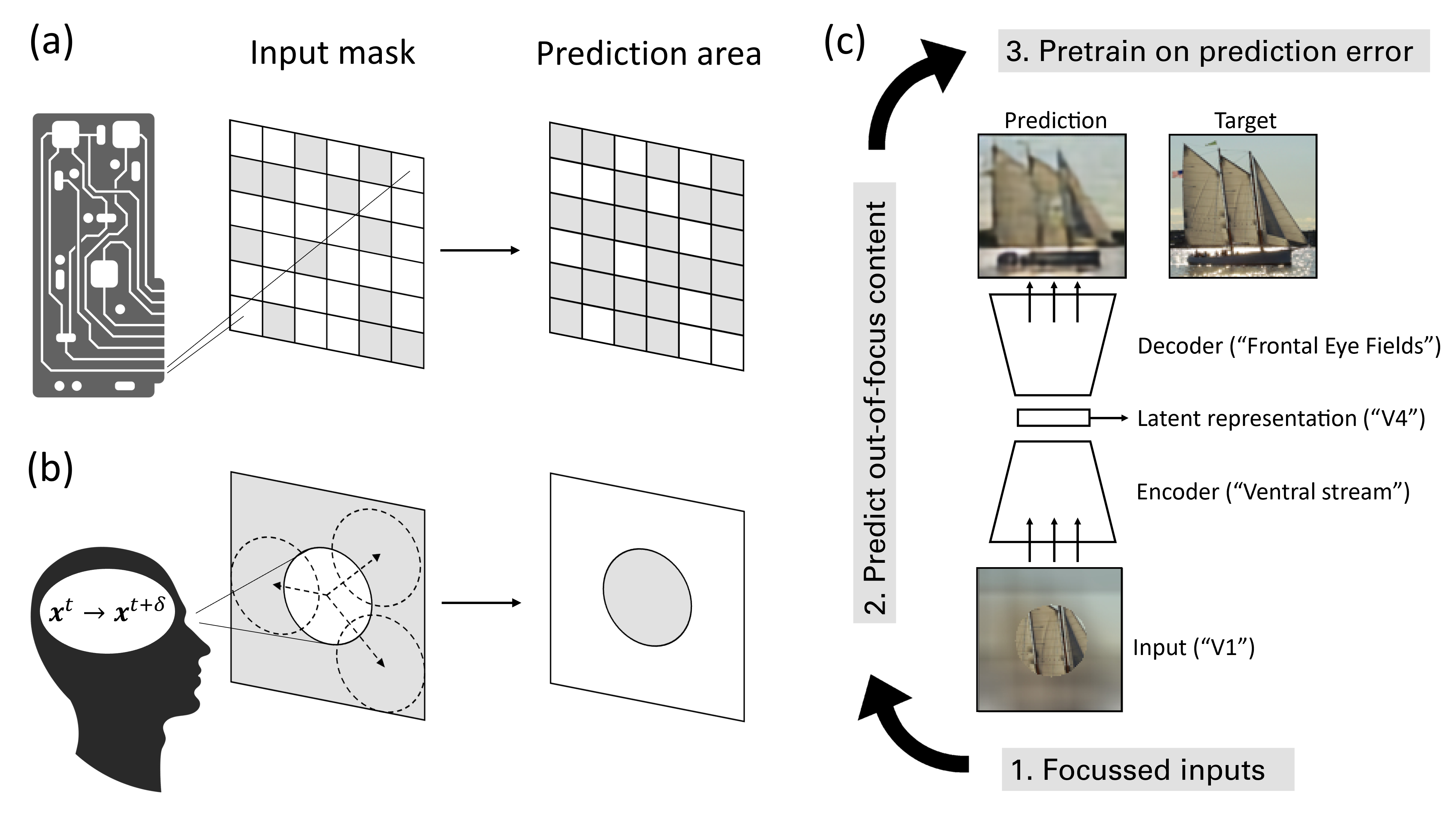
Masked Image Modeling as a Framework for Self-Supervised Learning across Eye Movements
Robin Weiler, Matthias Brucklacher, Cyriel M. A. Pennartz, Sander M. Boht'e
0
0
To make sense of their surroundings, intelligent systems must transform complex sensory inputs to structured codes that are reduced to task-relevant information such as object category. Biological agents achieve this in a largely autonomous manner, presumably via self-allowbreak super-allowbreak vised learning. Whereas previous attempts to model the underlying mechanisms were largely discriminative in nature, there is ample evidence that the brain employs a generative model of the world. Here, we propose that eye movements, in combination with the focused nature of primate vision, constitute a generative, self-supervised task of predicting and revealing visual information. We construct a proof-of-principle model starting from the framework of masked image modeling (MIM), a common approach in deep representation learning. To do so, we analyze how core components of MIM such as masking technique and data augmentation influence the formation of category-specific representations. This allows us not only to better understand the principles behind MIM, but to then reassemble a MIM more in line with the focused nature of biological perception. From a theoretical angle, we find that MIM disentangles neurons in latent space, a property that has been suggested to structure visual representations in primates, without explicit regulation. Together with previous findings of invariance learning, this highlights an interesting connection of MIM to latent regularization approaches for self-supervised learning. The source code is available under https://github.com/RobinWeiler/FocusMIM
4/15/2024

Morphing Tokens Draw Strong Masked Image Models
Taekyung Kim, Byeongho Heo, Dongyoon Han
0
0
Masked image modeling (MIM) is a promising option for training Vision Transformers among various self-supervised learning (SSL) methods. The essence of MIM lies in token-wise masked token predictions, with targets tokenized from images or generated by pre-trained models such as vision-language models. While tokenizers or pre-trained models are plausible MIM targets, they often offer spatially inconsistent targets even for neighboring tokens, complicating models to learn unified discriminative representations. Our pilot study confirms that addressing spatial inconsistencies has the potential to enhance representation quality. Motivated by the findings, we introduce a novel self-supervision signal called Dynamic Token Morphing (DTM), which dynamically aggregates contextually related tokens to yield contextualized targets. DTM is compatible with various SSL frameworks; we showcase an improved MIM by employing DTM, barely introducing extra training costs. Our experiments on ImageNet-1K and ADE20K demonstrate the superiority of our methods compared with state-of-the-art, complex MIM methods. Furthermore, the comparative evaluation of the iNaturalists and fine-grained visual classification datasets further validates the transferability of our method on various downstream tasks. Code is available at https://github.com/naver-ai/dtm
5/3/2024
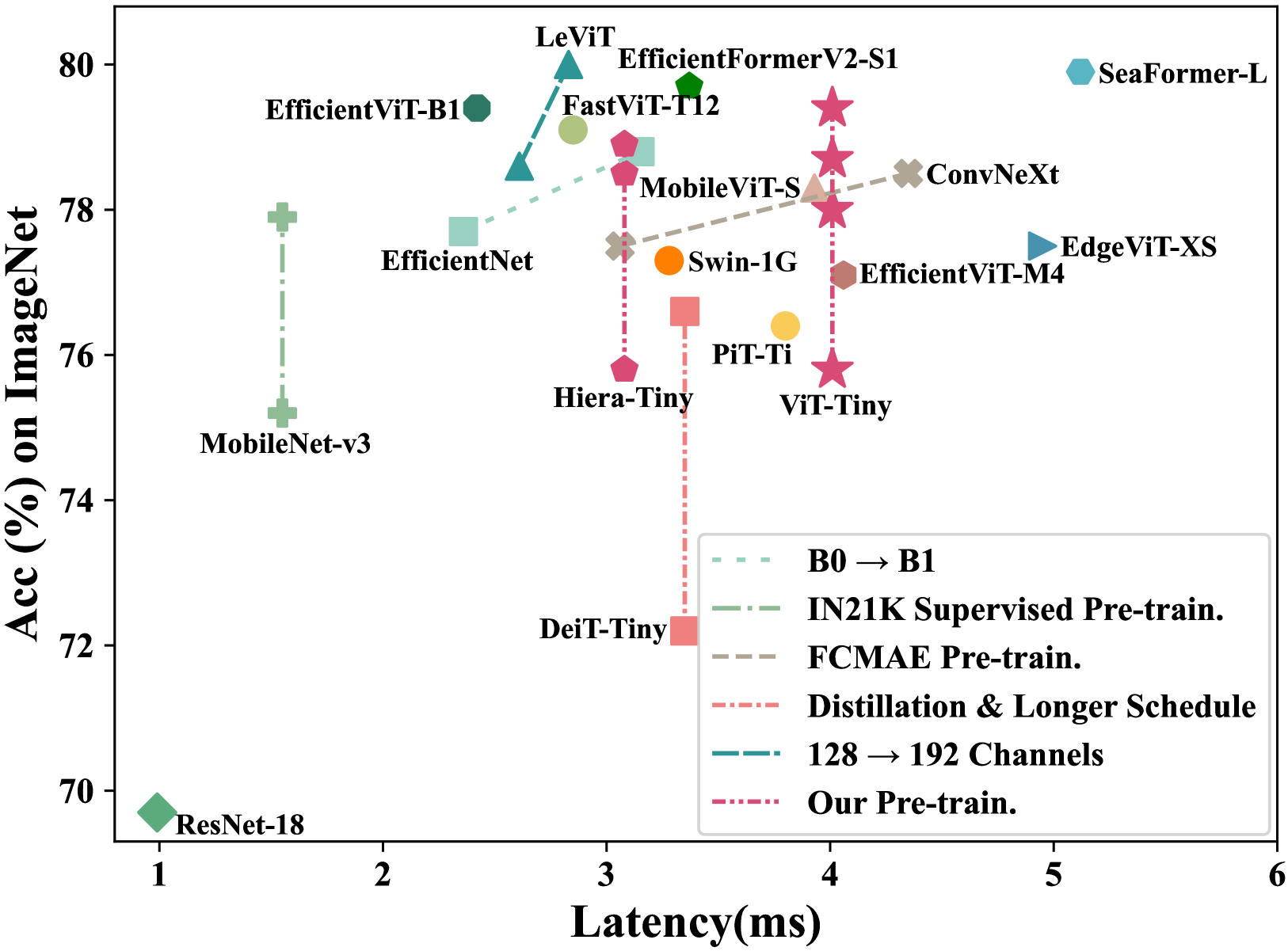
Observation, Analysis, and Solution: Exploring Strong Lightweight Vision Transformers via Masked Image Modeling Pre-Training
Jin Gao, Shubo Lin, Shaoru Wang, Yutong Kou, Zeming Li, Liang Li, Congxuan Zhang, Xiaoqin Zhang, Yizheng Wang, Weiming Hu
0
0
Masked image modeling (MIM) pre-training for large-scale vision transformers (ViTs) has enabled promising downstream performance on top of the learned self-supervised ViT features. In this paper, we question if the textit{extremely simple} lightweight ViTs' fine-tuning performance can also benefit from this pre-training paradigm, which is considerably less studied yet in contrast to the well-established lightweight architecture design methodology. We use an observation-analysis-solution flow for our study. We first systematically observe different behaviors among the evaluated pre-training methods with respect to the downstream fine-tuning data scales. Furthermore, we analyze the layer representation similarities and attention maps across the obtained models, which clearly show the inferior learning of MIM pre-training on higher layers, leading to unsatisfactory transfer performance on data-insufficient downstream tasks. This finding is naturally a guide to designing our distillation strategies during pre-training to solve the above deterioration problem. Extensive experiments have demonstrated the effectiveness of our approach. Our pre-training with distillation on pure lightweight ViTs with vanilla/hierarchical design ($5.7M$/$6.5M$) can achieve $79.4%$/$78.9%$ top-1 accuracy on ImageNet-1K. It also enables SOTA performance on the ADE20K segmentation task ($42.8%$ mIoU) and LaSOT tracking task ($66.1%$ AUC) in the lightweight regime. The latter even surpasses all the current SOTA lightweight CPU-realtime trackers.
5/28/2024