MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer

0
Sign in to get full access
Overview
- A new text-to-speech (TTS) model called MaskGCT that can generate high-quality speech from text without requiring parallel speech-text training data
- Uses a masked generative codec transformer (GCT) to learn a speech representation that can be conditioned on text
- Enables zero-shot TTS - generating speech for any text, even for languages or speakers not seen during training
Plain English Explanation
The MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer paper introduces a novel approach to text-to-speech (TTS) generation. Typically, TTS models require large datasets of paired text and audio recordings to learn the connection between written language and spoken output.
However, the MaskGCT model takes a different approach. It learns a general representation of speech that can be conditioned on any input text, even for languages or speakers that were not part of the training data. This "zero-shot" capability means the model can generate high-quality speech for any text, without needing parallel speech-text examples for that specific content.
The key innovation is the use of a "masked generative codec transformer" (GCT) architecture. This allows the model to learn an abstract speech representation that captures the important acoustic features, while still being flexible enough to be adapted to new text inputs. By masking parts of the input during training, the GCT learns to predict the missing speech elements based on the surrounding context.
This zero-shot TTS capability opens up exciting possibilities, such as generating speech for low-resource languages or creating custom voice assistants without the need for extensive data collection and model retraining.
Technical Explanation
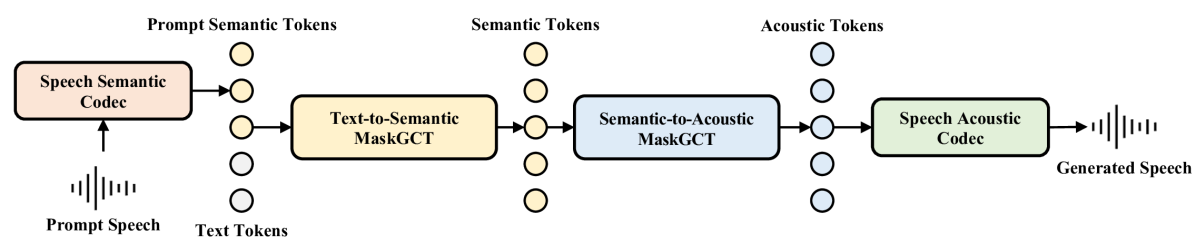
The MaskGCT model consists of two key components:
-
A Generative Codec Transformer (GCT) that learns a compact, discrete speech representation. The GCT is trained using a masked language modeling objective, where portions of the input speech are randomly masked and the model must predict the missing elements.
-
A Text Encoder that maps input text to the speech representation learned by the GCT. This allows the model to generate speech conditioned on any text input, even for languages or speakers not seen during training.
The training process proceeds in two stages:
-
Pre-training the GCT: The GCT is trained on a large corpus of unlabeled speech data to learn a high-quality speech representation, without any text information.
-
Training the end-to-end TTS model: The text encoder is then trained to map text inputs to the GCT's speech representation. This allows the full MaskGCT model to generate speech for any given text.
Key insights from the experimental results include:
- MaskGCT achieves state-of-the-art zero-shot TTS performance, outperforming previous approaches.
- The model can generate high-quality speech for languages and speakers not seen during training.
- The discrete speech representation learned by the GCT is compact and efficient, enabling fast inference speeds.
Critical Analysis
The paper presents a compelling approach to zero-shot TTS, but there are some potential limitations and areas for future work:
-
The experiments focus on a relatively narrow set of languages and speakers. It would be important to further evaluate the model's generalization to a wider range of languages, accents, and speaking styles.
-
The paper does not provide detailed analysis of the speech quality or intelligibility of the generated audio. More extensive human evaluation would be needed to fully assess the model's capabilities.
-
The training process involves two separate stages, which could be complex and time-consuming. Exploring ways to jointly train the GCT and text encoder components may lead to further efficiency gains.
-
While the discrete speech representation is efficient, the authors do not compare the model size and inference speed to previous zero-shot TTS approaches. Understanding the computational trade-offs would be valuable.
Despite these potential limitations, the MaskGCT model represents an exciting advance in the field of text-to-speech generation. Its ability to generate high-quality speech for any text, without requiring parallel speech-text data, opens up new possibilities for low-resource language support and personalized voice interfaces.
Conclusion
The MaskGCT paper introduces a novel text-to-speech model that can generate high-quality speech from text in a zero-shot manner. By learning a compact, discrete representation of speech and conditioning it on text input, the model can produce natural-sounding audio for any given text, even for languages and speakers not seen during training.
This breakthrough has the potential to significantly expand the reach and accessibility of text-to-speech technology, enabling support for low-resource languages and the creation of personalized voice assistants without the need for extensive data collection. As the authors continue to refine and expand the model, we may see MaskGCT and similar zero-shot TTS approaches become an integral part of the next generation of voice interfaces and language technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MaskGCT: Zero-Shot Text-to-Speech with Masked Generative Codec Transformer
Yuancheng Wang, Haoyue Zhan, Liwei Liu, Ruihong Zeng, Haotian Guo, Jiachen Zheng, Qiang Zhang, Shunsi Zhang, Zhizheng Wu
Nowadays, large-scale text-to-speech (TTS) systems are primarily divided into two types: autoregressive and non-autoregressive. The autoregressive systems have certain deficiencies in robustness and cannot control speech duration. In contrast, non-autoregressive systems require explicit prediction of phone-level duration, which may compromise their naturalness. We introduce the Masked Generative Codec Transformer (MaskGCT), a fully non-autoregressive model for TTS that does not require precise alignment information between text and speech. MaskGCT is a two-stage model: in the first stage, the model uses text to predict semantic tokens extracted from a speech self-supervised learning (SSL) model, and in the second stage, the model predicts acoustic tokens conditioned on these semantic tokens. MaskGCT follows the textit{mask-and-predict} learning paradigm. During training, MaskGCT learns to predict masked semantic or acoustic tokens based on given conditions and prompts. During inference, the model generates tokens of a specified length in a parallel manner. We scale MaskGCT to a large-scale multilingual dataset with 100K hours of in-the-wild speech. Our experiments demonstrate that MaskGCT achieves superior or competitive performance compared to state-of-the-art zero-shot TTS systems in terms of quality, similarity, and intelligibility while offering higher generation efficiency than diffusion-based or autoregressive TTS models. Audio samples are available at https://maskgct.github.io.
Read more9/4/2024
💬
0
MobileSpeech: A Fast and High-Fidelity Framework for Mobile Zero-Shot Text-to-Speech
Shengpeng Ji, Ziyue Jiang, Hanting Wang, Jialong Zuo, Zhou Zhao
Zero-shot text-to-speech (TTS) has gained significant attention due to its powerful voice cloning capabilities, requiring only a few seconds of unseen speaker voice prompts. However, all previous work has been developed for cloud-based systems. Taking autoregressive models as an example, although these approaches achieve high-fidelity voice cloning, they fall short in terms of inference speed, model size, and robustness. Therefore, we propose MobileSpeech, which is a fast, lightweight, and robust zero-shot text-to-speech system based on mobile devices for the first time. Specifically: 1) leveraging discrete codec, we design a parallel speech mask decoder module called SMD, which incorporates hierarchical information from the speech codec and weight mechanisms across different codec layers during the generation process. Moreover, to bridge the gap between text and speech, we introduce a high-level probabilistic mask that simulates the progression of information flow from less to more during speech generation. 2) For speaker prompts, we extract fine-grained prompt duration from the prompt speech and incorporate text, prompt speech by cross attention in SMD. We demonstrate the effectiveness of MobileSpeech on multilingual datasets at different levels, achieving state-of-the-art results in terms of generating speed and speech quality. MobileSpeech achieves RTF of 0.09 on a single A100 GPU and we have successfully deployed MobileSpeech on mobile devices. Audio samples are available at url{https://mobilespeech.github.io/} .
Read more6/4/2024

0
A Non-autoregressive Generation Framework for End-to-End Simultaneous Speech-to-Any Translation
Zhengrui Ma, Qingkai Fang, Shaolei Zhang, Shoutao Guo, Yang Feng, Min Zhang
Simultaneous translation models play a crucial role in facilitating communication. However, existing research primarily focuses on text-to-text or speech-to-text models, necessitating additional cascade components to achieve speech-to-speech translation. These pipeline methods suffer from error propagation and accumulate delays in each cascade component, resulting in reduced synchronization between the speaker and listener. To overcome these challenges, we propose a novel non-autoregressive generation framework for simultaneous speech translation (NAST-S2X), which integrates speech-to-text and speech-to-speech tasks into a unified end-to-end framework. We develop a non-autoregressive decoder capable of concurrently generating multiple text or acoustic unit tokens upon receiving fixed-length speech chunks. The decoder can generate blank or repeated tokens and employ CTC decoding to dynamically adjust its latency. Experimental results show that NAST-S2X outperforms state-of-the-art models in both speech-to-text and speech-to-speech tasks. It achieves high-quality simultaneous interpretation within a delay of less than 3 seconds and provides a 28 times decoding speedup in offline generation.
Read more6/12/2024

0
Generative Pre-trained Speech Language Model with Efficient Hierarchical Transformer
Yongxin Zhu, Dan Su, Liqiang He, Linli Xu, Dong Yu
While recent advancements in speech language models have achieved significant progress, they face remarkable challenges in modeling the long acoustic sequences of neural audio codecs. In this paper, we introduce textbf{G}enerative textbf{P}re-trained textbf{S}peech textbf{T}ransformer (GPST), a hierarchical transformer designed for efficient speech language modeling. GPST quantizes audio waveforms into two distinct types of discrete speech representations and integrates them within a hierarchical transformer architecture, allowing for a unified one-stage generation process and enhancing Hi-Res audio generation capabilities. By training on large corpora of speeches in an end-to-end unsupervised manner, GPST can generate syntactically consistent speech with diverse speaker identities. Given a brief 3-second prompt, GPST can produce natural and coherent personalized speech, demonstrating in-context learning abilities. Moreover, our approach can be easily extended to spoken cross-lingual speech generation by incorporating multi-lingual semantic tokens and universal acoustic tokens. Experimental results indicate that GPST significantly outperforms the existing speech language models in terms of word error rate, speech quality, and speaker similarity. See url{https://youngsheen.github.io/GPST/demo} for demo samples.
Read more6/4/2024