MobileSpeech: A Fast and High-Fidelity Framework for Mobile Zero-Shot Text-to-Speech
2402.09378
0
0
💬
Abstract
Zero-shot text-to-speech (TTS) has gained significant attention due to its powerful voice cloning capabilities, requiring only a few seconds of unseen speaker voice prompts. However, all previous work has been developed for cloud-based systems. Taking autoregressive models as an example, although these approaches achieve high-fidelity voice cloning, they fall short in terms of inference speed, model size, and robustness. Therefore, we propose MobileSpeech, which is a fast, lightweight, and robust zero-shot text-to-speech system based on mobile devices for the first time. Specifically: 1) leveraging discrete codec, we design a parallel speech mask decoder module called SMD, which incorporates hierarchical information from the speech codec and weight mechanisms across different codec layers during the generation process. Moreover, to bridge the gap between text and speech, we introduce a high-level probabilistic mask that simulates the progression of information flow from less to more during speech generation. 2) For speaker prompts, we extract fine-grained prompt duration from the prompt speech and incorporate text, prompt speech by cross attention in SMD. We demonstrate the effectiveness of MobileSpeech on multilingual datasets at different levels, achieving state-of-the-art results in terms of generating speed and speech quality. MobileSpeech achieves RTF of 0.09 on a single A100 GPU and we have successfully deployed MobileSpeech on mobile devices. Audio samples are available at url{https://mobilespeech.github.io/} .
Create account to get full access
Overview
- This paper presents a novel zero-shot text-to-speech (TTS) system called MobileSpeech that is designed to run efficiently on mobile devices.
- Previous zero-shot TTS approaches have been limited to cloud-based systems, which have drawbacks in terms of inference speed, model size, and robustness.
- MobileSpeech addresses these limitations by leveraging a discrete codec and introducing a parallel speech mask decoder module to enable fast, lightweight, and robust zero-shot voice cloning on mobile devices.
Plain English Explanation
MobileSpeech is a new technology that allows you to clone someone's voice using just a few seconds of their speech, even if you've never heard that person speak before. This is called "zero-shot" voice cloning.
Previous zero-shot voice cloning systems have all been cloud-based, meaning they run on powerful computers in the cloud. While these cloud-based systems can produce very realistic voice clones, they have some drawbacks. They can be slow, the models can be very large, and they may not always work reliably.
MobileSpeech is different because it's designed to run on mobile devices like smartphones and tablets. To achieve this, the researchers used a special type of audio encoding called a "discrete codec." They also created a new part of the system called the "speech mask decoder" that helps bridge the gap between the text you want to say and the voice you want to clone.
The result is a voice cloning system that is fast, compact, and robust, allowing you to clone voices on your mobile device. This could have lots of useful applications, like translating text into a celebrity's voice or creating custom audio assistants.
Technical Explanation
MobileSpeech is a novel zero-shot text-to-speech (TTS) system designed to run efficiently on mobile devices. Unlike previous zero-shot TTS approaches, which have been limited to cloud-based systems, MobileSpeech addresses the key limitations of inference speed, model size, and robustness.
The core innovations of MobileSpeech include:
-
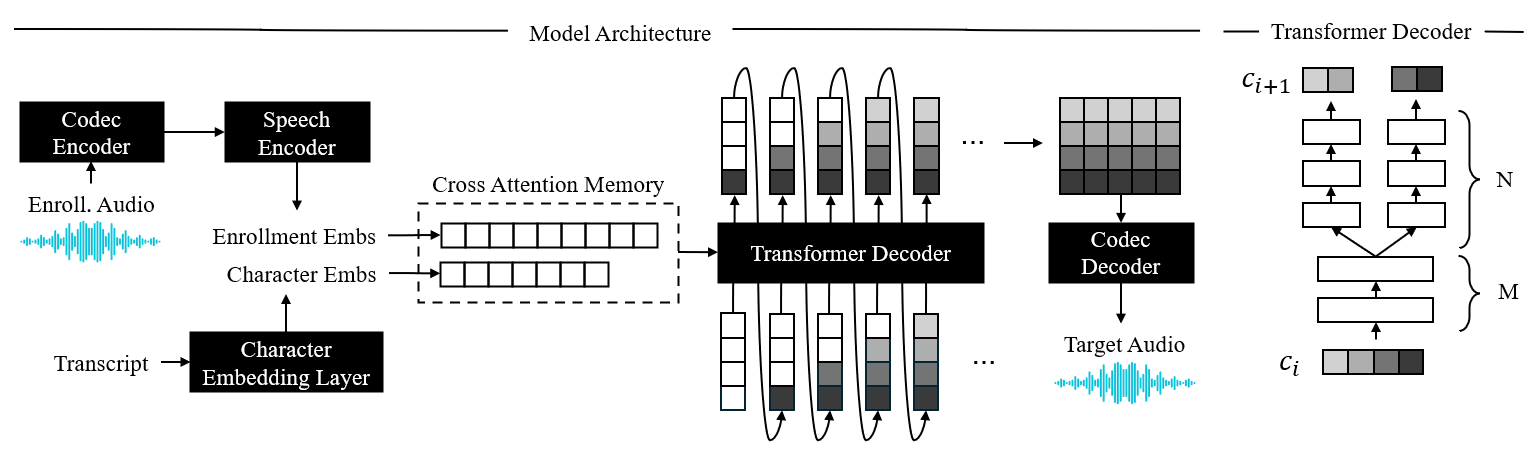
Discrete Codec and Speech Mask Decoder (SMD): The authors leverage a discrete speech codec to design a parallel SMD module that incorporates hierarchical information from the speech codec and attention mechanisms across different codec layers during the generation process. This allows for fast and lightweight speech synthesis.
-
Bridging Text and Speech: To bridge the gap between text and speech, MobileSpeech introduces a high-level probabilistic mask that simulates the progression of information flow from less to more during speech generation.
-
Speaker Prompt Integration: For speaker prompts, MobileSpeech extracts fine-grained prompt duration information and incorporates both text and prompt speech using cross-attention in the SMD module.
Through these innovations, MobileSpeech achieves state-of-the-art results in terms of generation speed and speech quality, with an RTF (real-time factor) of 0.09 on a single A100 GPU. The authors have successfully deployed MobileSpeech on mobile devices, demonstrating its practical feasibility.
Critical Analysis
The MobileSpeech paper presents a compelling solution for efficient zero-shot text-to-speech on mobile devices. By addressing the limitations of previous cloud-based approaches, the authors have made significant progress in bringing high-quality voice cloning capabilities to the edge.
One potential area for further research is the robustness of the system to noisy or diverse speaker prompts. The paper focuses on clean, high-quality prompts, but real-world scenarios may involve more challenging audio conditions. Exploring techniques to improve the system's resilience to such scenarios could further enhance its practical applicability.
Additionally, the authors mention that MobileSpeech has been successfully deployed on mobile devices, but they do not provide detailed performance metrics or user studies. Evaluating the system's real-world performance, user experience, and potential use cases on mobile platforms would help validate its practical utility and inform future development.
Overall, the MobileSpeech paper represents an important step forward in bringing powerful voice cloning capabilities to mobile devices. The technical innovations and promising results warrant further exploration and refinement to unlock the full potential of this technology.
Conclusion
MobileSpeech is a groundbreaking zero-shot text-to-speech system that addresses the limitations of previous cloud-based approaches by enabling efficient, high-quality voice cloning on mobile devices. By leveraging a discrete codec and introducing a novel speech mask decoder module, the researchers have developed a fast, lightweight, and robust solution that could have widespread applications in areas such as personalized audio assistants, language translation, and content creation.
The successful deployment of MobileSpeech on mobile platforms is a significant milestone, paving the way for more accessible and user-friendly voice cloning technologies. As the field of zero-shot TTS continues to evolve, the innovations and insights presented in this paper will likely inspire further advancements and push the boundaries of what is possible in terms of mobile-based speech synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
LiveSpeech: Low-Latency Zero-shot Text-to-Speech via Autoregressive Modeling of Audio Discrete Codes
Trung Dang, David Aponte, Dung Tran, Kazuhito Koishida
0
0
Prior works have demonstrated zero-shot text-to-speech by using a generative language model on audio tokens obtained via a neural audio codec. It is still challenging, however, to adapt them to low-latency scenarios. In this paper, we present LiveSpeech - a fully autoregressive language model-based approach for zero-shot text-to-speech, enabling low-latency streaming of the output audio. To allow multiple token prediction within a single decoding step, we propose (1) using adaptive codebook loss weights that consider codebook contribution in each frame and focus on hard instances, and (2) grouping codebooks and processing groups in parallel. Experiments show our proposed models achieve competitive results to state-of-the-art baselines in terms of content accuracy, speaker similarity, audio quality, and inference speed while being suitable for low-latency streaming applications.
6/11/2024
🗣️
FlashSpeech: Efficient Zero-Shot Speech Synthesis
Zhen Ye, Zeqian Ju, Haohe Liu, Xu Tan, Jianyi Chen, Yiwen Lu, Peiwen Sun, Jiahao Pan, Weizhen Bian, Shulin He, Qifeng Liu, Yike Guo, Wei Xue
0
0
Recent progress in large-scale zero-shot speech synthesis has been significantly advanced by language models and diffusion models. However, the generation process of both methods is slow and computationally intensive. Efficient speech synthesis using a lower computing budget to achieve quality on par with previous work remains a significant challenge. In this paper, we present FlashSpeech, a large-scale zero-shot speech synthesis system with approximately 5% of the inference time compared with previous work. FlashSpeech is built on the latent consistency model and applies a novel adversarial consistency training approach that can train from scratch without the need for a pre-trained diffusion model as the teacher. Furthermore, a new prosody generator module enhances the diversity of prosody, making the rhythm of the speech sound more natural. The generation processes of FlashSpeech can be achieved efficiently with one or two sampling steps while maintaining high audio quality and high similarity to the audio prompt for zero-shot speech generation. Our experimental results demonstrate the superior performance of FlashSpeech. Notably, FlashSpeech can be about 20 times faster than other zero-shot speech synthesis systems while maintaining comparable performance in terms of voice quality and similarity. Furthermore, FlashSpeech demonstrates its versatility by efficiently performing tasks like voice conversion, speech editing, and diverse speech sampling. Audio samples can be found in https://flashspeech.github.io/.
4/26/2024

Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Shun Lei, Yixuan Zhou, Liyang Chen, Dan Luo, Zhiyong Wu, Xixin Wu, Shiyin Kang, Tao Jiang, Yahui Zhou, Yuxing Han, Helen Meng
0
0
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
4/10/2024
🗣️
Mega-TTS 2: Boosting Prompting Mechanisms for Zero-Shot Speech Synthesis
Ziyue Jiang, Jinglin Liu, Yi Ren, Jinzheng He, Zhenhui Ye, Shengpeng Ji, Qian Yang, Chen Zhang, Pengfei Wei, Chunfeng Wang, Xiang Yin, Zejun Ma, Zhou Zhao
0
0
Zero-shot text-to-speech (TTS) aims to synthesize voices with unseen speech prompts, which significantly reduces the data and computation requirements for voice cloning by skipping the fine-tuning process. However, the prompting mechanisms of zero-shot TTS still face challenges in the following aspects: 1) previous works of zero-shot TTS are typically trained with single-sentence prompts, which significantly restricts their performance when the data is relatively sufficient during the inference stage. 2) The prosodic information in prompts is highly coupled with timbre, making it untransferable to each other. This paper introduces Mega-TTS 2, a generic prompting mechanism for zero-shot TTS, to tackle the aforementioned challenges. Specifically, we design a powerful acoustic autoencoder that separately encodes the prosody and timbre information into the compressed latent space while providing high-quality reconstructions. Then, we propose a multi-reference timbre encoder and a prosody latent language model (P-LLM) to extract useful information from multi-sentence prompts. We further leverage the probabilities derived from multiple P-LLM outputs to produce transferable and controllable prosody. Experimental results demonstrate that Mega-TTS 2 could not only synthesize identity-preserving speech with a short prompt of an unseen speaker from arbitrary sources but consistently outperform the fine-tuning method when the volume of data ranges from 10 seconds to 5 minutes. Furthermore, our method enables to transfer various speaking styles to the target timbre in a fine-grained and controlled manner. Audio samples can be found in https://boostprompt.github.io/boostprompt/.
4/11/2024