MaxFusion: Plug&Play Multi-Modal Generation in Text-to-Image Diffusion Models
2404.09977
0
1

Abstract
Large diffusion-based Text-to-Image (T2I) models have shown impressive generative powers for text-to-image generation as well as spatially conditioned image generation. For most applications, we can train the model end-toend with paired data to obtain photorealistic generation quality. However, to add an additional task, one often needs to retrain the model from scratch using paired data across all modalities to retain good generation performance. In this paper, we tackle this issue and propose a novel strategy to scale a generative model across new tasks with minimal compute. During our experiments, we discovered that the variance maps of intermediate feature maps of diffusion models capture the intensity of conditioning. Utilizing this prior information, we propose MaxFusion, an efficient strategy to scale up text-to-image generation models to accommodate new modality conditions. Specifically, we combine aligned features of multiple models, hence bringing a compositional effect. Our fusion strategy can be integrated into off-the-shelf models to enhance their generative prowess.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper presents a new method called MaxFusion for enabling multi-modal conditioning in text-to-image diffusion models.
- The key innovation is a "plug-and-play" approach that allows for seamless integration of different modalities, such as text, images, and even 3D models, into the diffusion process.
- This allows for flexible and powerful multi-modal generation capabilities, going beyond standard text-to-image generation.
Plain English Explanation
MaxFusion is a new technique that lets you combine different types of information, like text, images, and 3D models, when generating new images using diffusion models. Diffusion models are a powerful type of AI that can create highly realistic images, but they've mostly been limited to generating images from just text so far.
With MaxFusion, you can now feed in a mix of information - for example, a text description plus a reference image - and the model will use all of that to generate a new, unique image. This unlocks a lot of new creative possibilities, like generating images that blend multiple concepts or styles together.
The key innovation is that MaxFusion lets you plug in these different modalities in a flexible, "plug-and-play" way. You don't have to completely redesign the model to work with new types of inputs - you can just easily add them in. This makes it much easier for researchers and developers to experiment with multi-modal generation and expand the capabilities of these powerful diffusion models.
Technical Explanation
The paper introduces a new method called MaxFusion that enables flexible multi-modal conditioning in text-to-image diffusion models. Diffusion models [link to "Scalability of Diffusion-based Text-to-Image Generation"] have shown impressive results in generating high-quality images from text prompts, but have been limited to single-modal conditioning.
MaxFusion proposes a "plug-and-play" approach that allows seamless integration of different modalities, such as text, images, and even 3D models, into the diffusion process. This is achieved by concatenating the embeddings of the various inputs and passing them through a shared cross-attention mechanism.
The authors demonstrate the effectiveness of MaxFusion on several benchmarks, showing that it can outperform existing multi-modal fusion methods [link to "CapsuleFusion: Rethinking Image-Text Data at Scale"] in terms of both image quality and multi-modal alignment. They also show that MaxFusion can be easily integrated with state-of-the-art diffusion models [link to "DiffScaler: Enhancing the Generative Prowess of Diffusion Transformers"] to further boost performance.
Critical Analysis
The MaxFusion approach presented in this paper is a promising step forward in enabling more flexible and powerful multi-modal generation with diffusion models. By allowing easy integration of various input modalities, it opens up new creative possibilities for researchers and developers.
However, the paper does not address some potential limitations and areas for further exploration. For example, it's unclear how MaxFusion would scale to handling a large number of diverse modalities simultaneously, or how it might handle conflicting or contradictory input signals.
Additionally, while the paper demonstrates strong performance on benchmarks, it would be valuable to see more real-world use cases and evaluations of the generated outputs from end users' perspectives. [link to "Concept Weaver: Enabling Multi-Concept Fusion in Text-to-Image Generation"]
Overall, MaxFusion represents an important advance in multi-modal diffusion models, but there is still room for further research and development to fully unlock the potential of this [link to "Data-Efficient Multimodal Fusion on a Single GPU"] approach.
Conclusion
The MaxFusion method presented in this paper is a significant step forward in enabling multi-modal conditioning for text-to-image diffusion models. By introducing a flexible, "plug-and-play" approach, it allows for seamless integration of various input modalities, opening up new creative possibilities for generation.
The technical evaluations demonstrate the effectiveness of MaxFusion in outperforming existing multi-modal fusion techniques, and its ability to be easily combined with state-of-the-art diffusion models. While there are still some areas for further exploration, MaxFusion represents an important advancement that could have wide-ranging implications for the field of generative AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Generative AI Beyond LLMs: System Implications of Multi-Modal Generation
Alicia Golden, Samuel Hsia, Fei Sun, Bilge Acun, Basil Hosmer, Yejin Lee, Zachary DeVito, Jeff Johnson, Gu-Yeon Wei, David Brooks, Carole-Jean Wu
0
0
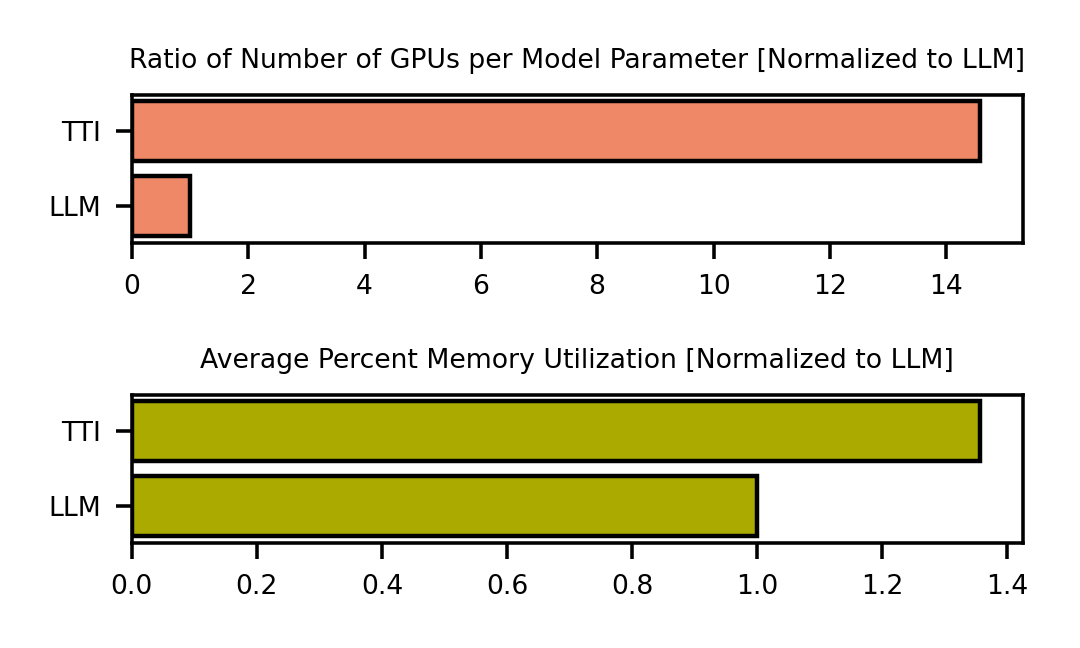
As the development of large-scale Generative AI models evolve beyond text (1D) generation to include image (2D) and video (3D) generation, processing spatial and temporal information presents unique challenges to quality, performance, and efficiency. We present the first work towards understanding this new system design space for multi-modal text-to-image (TTI) and text-to-video (TTV) generation models. Current model architecture designs are bifurcated into 2 categories: Diffusion- and Transformer-based models. Our systematic performance characterization on a suite of eight representative TTI/TTV models shows that after state-of-the-art optimization techniques such as Flash Attention are applied, Convolution accounts for up to 44% of execution time for Diffusion-based TTI models, while Linear layers consume up to 49% of execution time for Transformer-based models. We additionally observe that Diffusion-based TTI models resemble the Prefill stage of LLM inference, and benefit from 1.1-2.5x greater speedup from Flash Attention than Transformer-based TTI models that resemble the Decode phase. Since optimizations designed for LLMs do not map directly onto TTI/TTV models, we must conduct a thorough characterization of these workloads to gain insights for new optimization opportunities. In doing so, we define sequence length in the context of TTI/TTV models and observe sequence length can vary up to 4x in Diffusion model inference. We additionally observe temporal aspects of TTV workloads pose unique system bottlenecks, with Temporal Attention accounting for over 60% of total Attention time. Overall, our in-depth system performance characterization is a critical first step towards designing efficient and deployable systems for emerging TTI/TTV workloads.
5/7/2024
On the Scalability of Diffusion-based Text-to-Image Generation
Hao Li, Yang Zou, Ying Wang, Orchid Majumder, Yusheng Xie, R. Manmatha, Ashwin Swaminathan, Zhuowen Tu, Stefano Ermon, Stefano Soatto
0
0
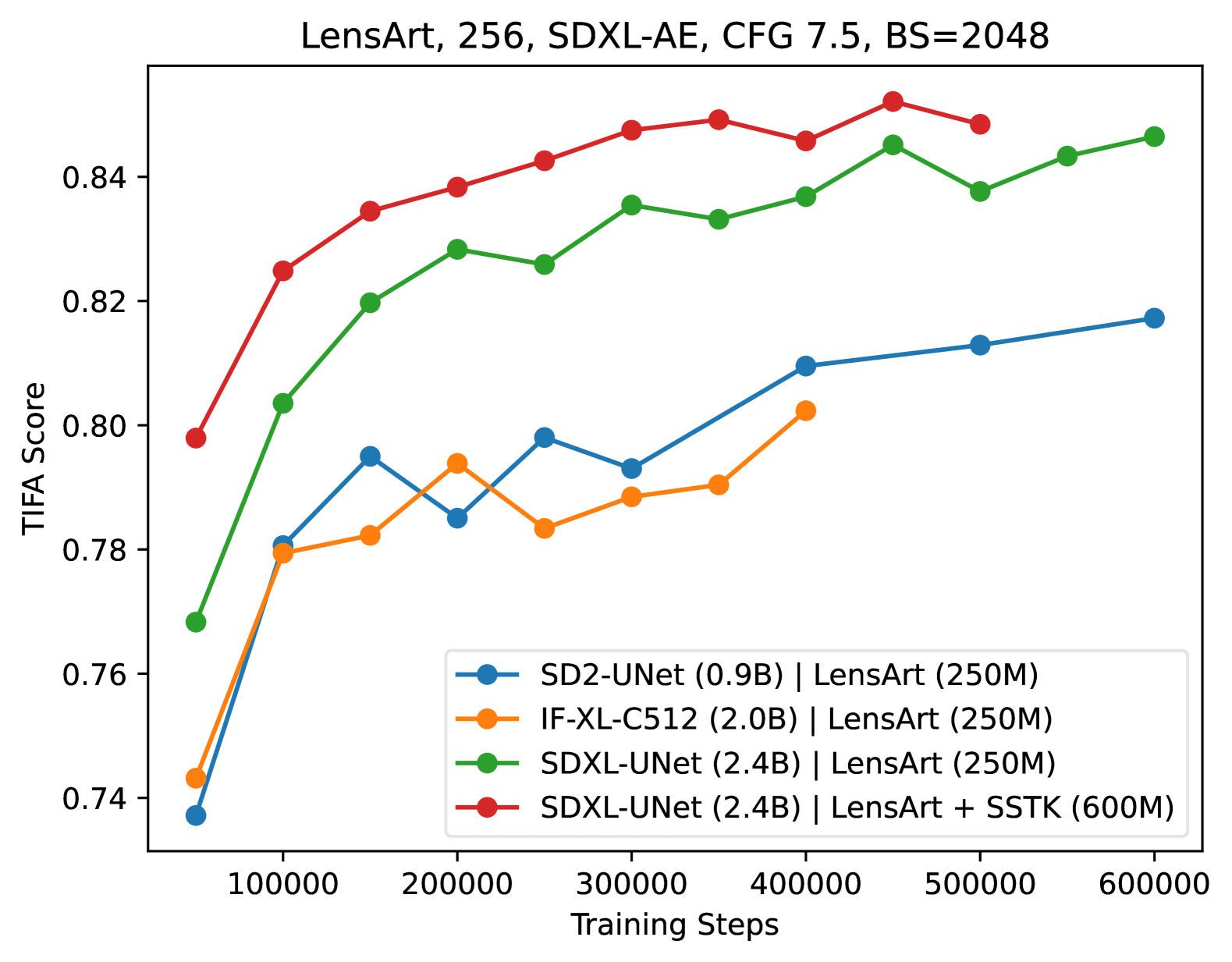
Scaling up model and data size has been quite successful for the evolution of LLMs. However, the scaling law for the diffusion based text-to-image (T2I) models is not fully explored. It is also unclear how to efficiently scale the model for better performance at reduced cost. The different training settings and expensive training cost make a fair model comparison extremely difficult. In this work, we empirically study the scaling properties of diffusion based T2I models by performing extensive and rigours ablations on scaling both denoising backbones and training set, including training scaled UNet and Transformer variants ranging from 0.4B to 4B parameters on datasets upto 600M images. For model scaling, we find the location and amount of cross attention distinguishes the performance of existing UNet designs. And increasing the transformer blocks is more parameter-efficient for improving text-image alignment than increasing channel numbers. We then identify an efficient UNet variant, which is 45% smaller and 28% faster than SDXL's UNet. On the data scaling side, we show the quality and diversity of the training set matters more than simply dataset size. Increasing caption density and diversity improves text-image alignment performance and the learning efficiency. Finally, we provide scaling functions to predict the text-image alignment performance as functions of the scale of model size, compute and dataset size.
4/4/2024
🛸
FlexEControl: Flexible and Efficient Multimodal Control for Text-to-Image Generation
Xuehai He, Jian Zheng, Jacob Zhiyuan Fang, Robinson Piramuthu, Mohit Bansal, Vicente Ordonez, Gunnar A Sigurdsson, Nanyun Peng, Xin Eric Wang
0
0
Controllable text-to-image (T2I) diffusion models generate images conditioned on both text prompts and semantic inputs of other modalities like edge maps. Nevertheless, current controllable T2I methods commonly face challenges related to efficiency and faithfulness, especially when conditioning on multiple inputs from either the same or diverse modalities. In this paper, we propose a novel Flexible and Efficient method, FlexEControl, for controllable T2I generation. At the core of FlexEControl is a unique weight decomposition strategy, which allows for streamlined integration of various input types. This approach not only enhances the faithfulness of the generated image to the control, but also significantly reduces the computational overhead typically associated with multimodal conditioning. Our approach achieves a reduction of 41% in trainable parameters and 30% in memory usage compared with Uni-ControlNet. Moreover, it doubles data efficiency and can flexibly generate images under the guidance of multiple input conditions of various modalities.
5/9/2024
📊
CapsFusion: Rethinking Image-Text Data at Scale
Qiying Yu, Quan Sun, Xiaosong Zhang, Yufeng Cui, Fan Zhang, Yue Cao, Xinlong Wang, Jingjing Liu
0
0
Large multimodal models demonstrate remarkable generalist ability to perform diverse multimodal tasks in a zero-shot manner. Large-scale web-based image-text pairs contribute fundamentally to this success, but suffer from excessive noise. Recent studies use alternative captions synthesized by captioning models and have achieved notable benchmark performance. However, our experiments reveal significant Scalability Deficiency and World Knowledge Loss issues in models trained with synthetic captions, which have been largely obscured by their initial benchmark success. Upon closer examination, we identify the root cause as the overly-simplified language structure and lack of knowledge details in existing synthetic captions. To provide higher-quality and more scalable multimodal pretraining data, we propose CapsFusion, an advanced framework that leverages large language models to consolidate and refine information from both web-based image-text pairs and synthetic captions. Extensive experiments show that CapsFusion captions exhibit remarkable all-round superiority over existing captions in terms of model performance (e.g., 18.8 and 18.3 improvements in CIDEr score on COCO and NoCaps), sample efficiency (requiring 11-16 times less computation than baselines), world knowledge depth, and scalability. These effectiveness, efficiency and scalability advantages position CapsFusion as a promising candidate for future scaling of LMM training.
4/8/2024