On the Scalability of Diffusion-based Text-to-Image Generation
2404.02883
0
1
Abstract
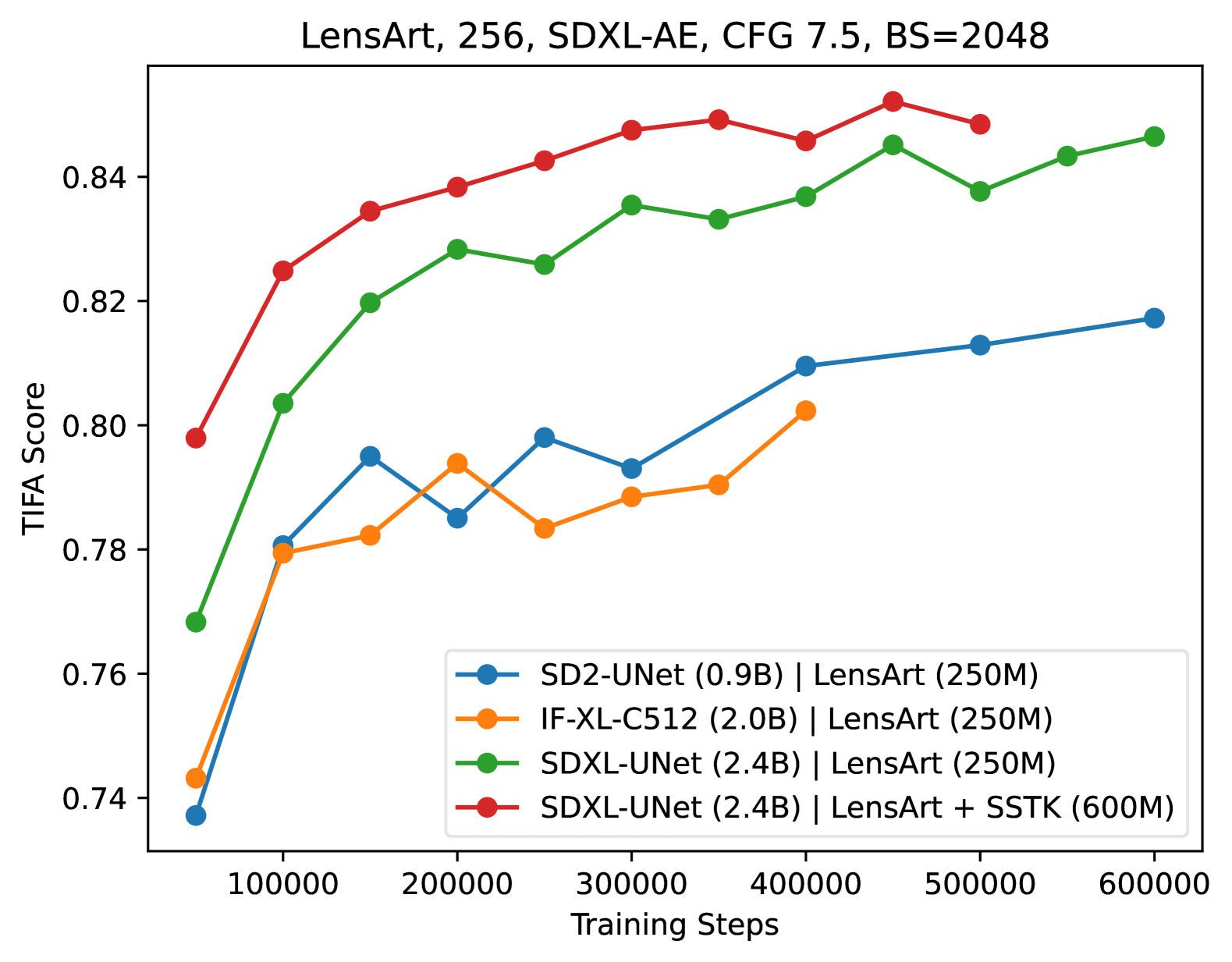
Scaling up model and data size has been quite successful for the evolution of LLMs. However, the scaling law for the diffusion based text-to-image (T2I) models is not fully explored. It is also unclear how to efficiently scale the model for better performance at reduced cost. The different training settings and expensive training cost make a fair model comparison extremely difficult. In this work, we empirically study the scaling properties of diffusion based T2I models by performing extensive and rigours ablations on scaling both denoising backbones and training set, including training scaled UNet and Transformer variants ranging from 0.4B to 4B parameters on datasets upto 600M images. For model scaling, we find the location and amount of cross attention distinguishes the performance of existing UNet designs. And increasing the transformer blocks is more parameter-efficient for improving text-image alignment than increasing channel numbers. We then identify an efficient UNet variant, which is 45% smaller and 28% faster than SDXL's UNet. On the data scaling side, we show the quality and diversity of the training set matters more than simply dataset size. Increasing caption density and diversity improves text-image alignment performance and the learning efficiency. Finally, we provide scaling functions to predict the text-image alignment performance as functions of the scale of model size, compute and dataset size.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper examines the scalability of diffusion-based text-to-image generation models, which are a type of AI system that can generate images from text descriptions.
- It explores the challenges and limitations of scaling up these models to handle more complex and diverse image generation tasks.
- The research aims to provide insights into the tradeoffs and design choices involved in building scalable and efficient text-to-image generation systems.
Plain English Explanation
Diffusion-based text-to-image generation models are a type of artificial intelligence (AI) system that can create images based on written descriptions. These models have shown impressive capabilities, but as they are scaled up to handle more complex tasks, there are challenges that arise.
The paper investigates these scalability issues, looking at how the performance and efficiency of the models change as they are made larger and more powerful. This is important because it can help researchers and developers understand the tradeoffs involved in building larger, more capable text-to-image generation systems.
By exploring the limitations and bottlenecks of scaling up these models, the paper aims to provide insights that can guide the development of future text-to-image generation technologies. This could lead to more powerful and versatile AI systems that can create high-quality images from textual descriptions, with potential applications in areas like art, design, and content creation.
Technical Explanation
The paper examines the scalability of diffusion-based text-to-image generation models, which are a type of AI system that can generate images from textual descriptions. The researchers investigate how the performance and efficiency of these models change as they are scaled up in size and complexity.
The experiments involve training and evaluating diffusion-based text-to-image models of varying sizes, from smaller "base" models to larger "scaled-up" versions. The researchers analyze metrics like image quality, generation speed, and resource consumption to understand the tradeoffs and challenges of scaling up these models.
The paper presents several key insights, including the observation that link to "Bigger is not always better: Scaling properties" larger models do not necessarily lead to proportional improvements in performance. The researchers also explore techniques like link to "Upsample Guidance: Scale up Diffusion Models without Increasing Model Size" to improve the scalability of these models without relying solely on increasing their size.
Additionally, the paper discusses the link to "Severity Controlled Text-to-Image Generative Model" and link to "DiffAgent: Fast and Accurate Text-to-Image API" as potential approaches to address the scalability challenges, as well as the link to "Exploiting Diffusion Prior for Generalizable Dense Prediction" as a way to leverage diffusion-based models for other tasks beyond text-to-image generation.
Critical Analysis
The paper provides a comprehensive analysis of the scalability challenges faced by diffusion-based text-to-image generation models. The researchers acknowledge the limitations of their study, noting that their experiments are primarily focused on a specific set of models and datasets, and that the findings may not generalize to all text-to-image generation systems.
One potential area for further research could be investigating the scalability of these models on more diverse and challenging datasets, as well as exploring the performance of alternative architectures or training techniques that may be more scalable.
Additionally, the paper could have delved deeper into the potential societal implications and ethical considerations of scaling up text-to-image generation technologies, such as the potential for misuse or the impact on creative industries.
Overall, the paper presents a valuable contribution to the understanding of the scalability challenges in this field, and the insights it provides can inform the development of more scalable and efficient text-to-image generation systems in the future.
Conclusion
The paper examines the scalability of diffusion-based text-to-image generation models, exploring the challenges and tradeoffs involved in scaling up these systems to handle more complex and diverse image generation tasks.
The research provides valuable insights into the performance and efficiency characteristics of larger, more powerful text-to-image generation models, highlighting the importance of considering scalability in the design and development of these AI systems.
The findings from this paper can inform the ongoing efforts to create more scalable and efficient text-to-image generation technologies, with potential applications in areas like art, design, and content creation. By understanding the limitations and bottlenecks of scaling up these models, researchers and developers can work towards building more capable and versatile text-to-image generation systems that can unlock new creative possibilities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Diffscaler: Enhancing the Generative Prowess of Diffusion Transformers
Nithin Gopalakrishnan Nair, Jeya Maria Jose Valanarasu, Vishal M. Patel
0
0
Recently, diffusion transformers have gained wide attention with its excellent performance in text-to-image and text-to-vidoe models, emphasizing the need for transformers as backbone for diffusion models. Transformer-based models have shown better generalization capability compared to CNN-based models for general vision tasks. However, much less has been explored in the existing literature regarding the capabilities of transformer-based diffusion backbones and expanding their generative prowess to other datasets. This paper focuses on enabling a single pre-trained diffusion transformer model to scale across multiple datasets swiftly, allowing for the completion of diverse generative tasks using just one model. To this end, we propose DiffScaler, an efficient scaling strategy for diffusion models where we train a minimal amount of parameters to adapt to different tasks. In particular, we learn task-specific transformations at each layer by incorporating the ability to utilize the learned subspaces of the pre-trained model, as well as the ability to learn additional task-specific subspaces, which may be absent in the pre-training dataset. As these parameters are independent, a single diffusion model with these task-specific parameters can be used to perform multiple tasks simultaneously. Moreover, we find that transformer-based diffusion models significantly outperform CNN-based diffusion models methods while performing fine-tuning over smaller datasets. We perform experiments on four unconditional image generation datasets. We show that using our proposed method, a single pre-trained model can scale up to perform these conditional and unconditional tasks, respectively, with minimal parameter tuning while performing as close as fine-tuning an entire diffusion model for that particular task.
4/16/2024

MaxFusion: Plug&Play Multi-Modal Generation in Text-to-Image Diffusion Models
Nithin Gopalakrishnan Nair, Jeya Maria Jose Valanarasu, Vishal M Patel
0
0
Large diffusion-based Text-to-Image (T2I) models have shown impressive generative powers for text-to-image generation as well as spatially conditioned image generation. For most applications, we can train the model end-toend with paired data to obtain photorealistic generation quality. However, to add an additional task, one often needs to retrain the model from scratch using paired data across all modalities to retain good generation performance. In this paper, we tackle this issue and propose a novel strategy to scale a generative model across new tasks with minimal compute. During our experiments, we discovered that the variance maps of intermediate feature maps of diffusion models capture the intensity of conditioning. Utilizing this prior information, we propose MaxFusion, an efficient strategy to scale up text-to-image generation models to accommodate new modality conditions. Specifically, we combine aligned features of multiple models, hence bringing a compositional effect. Our fusion strategy can be integrated into off-the-shelf models to enhance their generative prowess.
4/16/2024

Bigger is not Always Better: Scaling Properties of Latent Diffusion Models
Kangfu Mei, Zhengzhong Tu, Mauricio Delbracio, Hossein Talebi, Vishal M. Patel, Peyman Milanfar
0
0
We study the scaling properties of latent diffusion models (LDMs) with an emphasis on their sampling efficiency. While improved network architecture and inference algorithms have shown to effectively boost sampling efficiency of diffusion models, the role of model size -- a critical determinant of sampling efficiency -- has not been thoroughly examined. Through empirical analysis of established text-to-image diffusion models, we conduct an in-depth investigation into how model size influences sampling efficiency across varying sampling steps. Our findings unveil a surprising trend: when operating under a given inference budget, smaller models frequently outperform their larger equivalents in generating high-quality results. Moreover, we extend our study to demonstrate the generalizability of the these findings by applying various diffusion samplers, exploring diverse downstream tasks, evaluating post-distilled models, as well as comparing performance relative to training compute. These findings open up new pathways for the development of LDM scaling strategies which can be employed to enhance generative capabilities within limited inference budgets.
4/3/2024
Generative AI Beyond LLMs: System Implications of Multi-Modal Generation
Alicia Golden, Samuel Hsia, Fei Sun, Bilge Acun, Basil Hosmer, Yejin Lee, Zachary DeVito, Jeff Johnson, Gu-Yeon Wei, David Brooks, Carole-Jean Wu
0
0
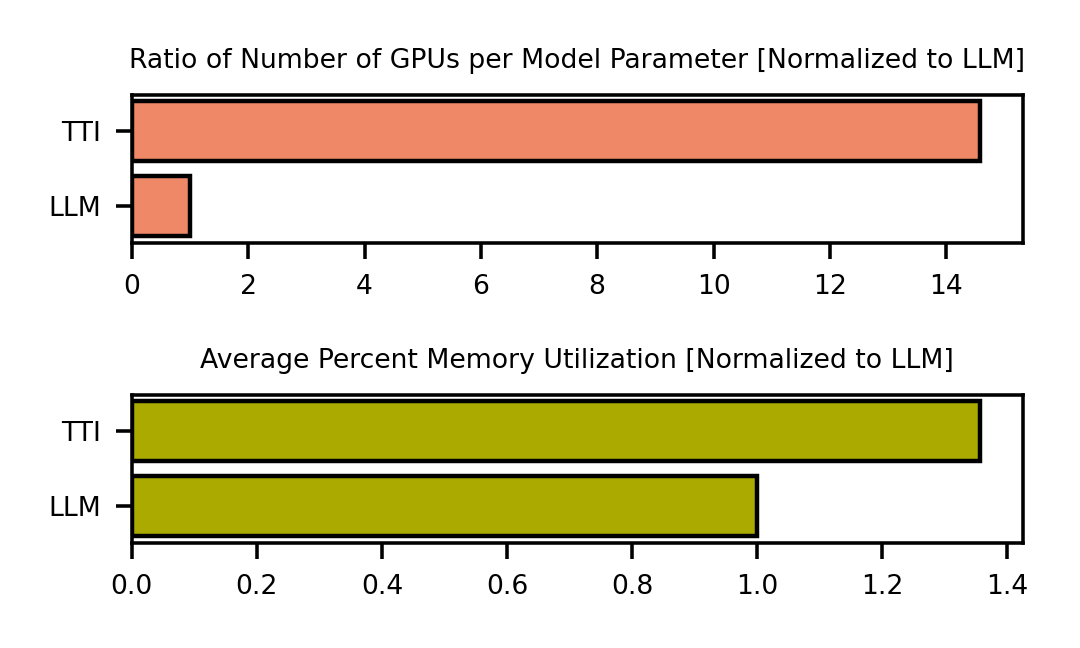
As the development of large-scale Generative AI models evolve beyond text (1D) generation to include image (2D) and video (3D) generation, processing spatial and temporal information presents unique challenges to quality, performance, and efficiency. We present the first work towards understanding this new system design space for multi-modal text-to-image (TTI) and text-to-video (TTV) generation models. Current model architecture designs are bifurcated into 2 categories: Diffusion- and Transformer-based models. Our systematic performance characterization on a suite of eight representative TTI/TTV models shows that after state-of-the-art optimization techniques such as Flash Attention are applied, Convolution accounts for up to 44% of execution time for Diffusion-based TTI models, while Linear layers consume up to 49% of execution time for Transformer-based models. We additionally observe that Diffusion-based TTI models resemble the Prefill stage of LLM inference, and benefit from 1.1-2.5x greater speedup from Flash Attention than Transformer-based TTI models that resemble the Decode phase. Since optimizations designed for LLMs do not map directly onto TTI/TTV models, we must conduct a thorough characterization of these workloads to gain insights for new optimization opportunities. In doing so, we define sequence length in the context of TTI/TTV models and observe sequence length can vary up to 4x in Diffusion model inference. We additionally observe temporal aspects of TTV workloads pose unique system bottlenecks, with Temporal Attention accounting for over 60% of total Attention time. Overall, our in-depth system performance characterization is a critical first step towards designing efficient and deployable systems for emerging TTI/TTV workloads.
5/7/2024