Maximal Volume Matrix Cross Approximation for Image Compression and Least Squares Solution

0
🖼️
Sign in to get full access
Overview
- The paper focuses on improving the classic matrix cross approximation technique based on maximal volume submatrices.
- The main contributions include a better estimate for the classic matrix cross approximation and a greedy approach for finding maximal volume submatrices.
- The proposed algorithms have theoretical guarantees of convergence.
- Applications explored include image compression and least squares approximation of continuous functions.
Plain English Explanation
The paper presents an improved method for matrix cross approximation, a technique used to efficiently represent and work with large matrices. The core idea is to find a smaller "submatrix" that captures the most important information in the original matrix.
The researchers introduce a new mathematical proof that provides a better estimate of how well the submatrix can approximate the original matrix. They also propose a "greedy" algorithm, which means it makes the best local decision at each step to efficiently find the optimal submatrix.
These improvements make matrix cross approximation more computationally efficient and accurate. The researchers demonstrate the benefits of their approach through two applications:
- Image compression: By representing images as matrices, the method can compress images without significant loss of quality.
- Least squares approximation: The technique can be used to efficiently approximate continuous functions, which is useful in fields like data analysis and scientific computing.
Overall, the paper advances the state-of-the-art in matrix cross approximation, offering a more powerful tool for working with large datasets and continuous functions.
Technical Explanation
The paper focuses on improving the classic matrix cross approximation technique, which is used to efficiently represent and work with large matrices. The key idea is to find a smaller "submatrix" that captures the most important information in the original matrix.
The researchers present two main contributions:
-
Improved estimate for matrix cross approximation: The paper provides a new proof of the classic estimate for matrix cross approximation, with an improved constant in the inequality. This leads to a tighter bound on the approximation error.
-
Greedy algorithms for finding maximal volume submatrices: The researchers propose a family of greedy algorithms to efficiently find the maximal volume submatrices, which are crucial for accurate matrix cross approximation. These algorithms have theoretical guarantees of convergence.
The paper also explores two applications of the improved matrix cross approximation technique:
- Image compression: By representing images as matrices, the method can be used to compress images without significant loss of quality.
- Least squares approximation of continuous functions: The technique can be applied to efficiently approximate continuous functions, which is useful in fields like data analysis and scientific computing.
The researchers present numerical results demonstrating the effective performance of their approach compared to classic matrix cross approximation.
Critical Analysis
The paper makes valuable contributions to the field of matrix cross approximation, providing both theoretical and practical advancements. The improved estimate for the classic matrix cross approximation and the greedy algorithms for finding maximal volume submatrices are significant improvements that can lead to more efficient and accurate representations of large matrices.
However, the paper does not address some potential limitations of the proposed approach. For example, the performance of the greedy algorithms may depend on the specific structure of the input matrix, and there could be cases where the algorithms fail to find the optimal submatrix. Additionally, the paper does not explore the sensitivity of the method to noise or outliers in the input data, which could be an important consideration in real-world applications.
Further research could investigate the robustness of the proposed techniques, explore alternative greedy algorithms, and compare the performance of the method to other matrix approximation techniques, such as low-rank matrix completion or adversarial robust low-rank matrix estimation. Additionally, the applications presented in the paper could be expanded to include a wider range of domains and use cases.
Conclusion
This paper presents significant improvements to the classic matrix cross approximation technique, including a better estimate for the approximation error and efficient greedy algorithms for finding maximal volume submatrices. These advancements can lead to more accurate and computationally efficient representations of large matrices, with applications in areas like image compression and function approximation.
While the paper does not address all potential limitations of the proposed approach, it represents an important step forward in the field of matrix cross approximation and provides a solid foundation for future research and development in this area.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Maximal Volume Matrix Cross Approximation for Image Compression and Least Squares Solution
Kenneth Allen, Ming-Jun Lai, Zhaiming Shen
We study the classic matrix cross approximation based on the maximal volume submatrices. Our main results consist of an improvement of the classic estimate for matrix cross approximation and a greedy approach for finding the maximal volume submatrices. More precisely, we present a new proof of the classic estimate of the inequality with an improved constant. Also, we present a family of greedy maximal volume algorithms to improve the computational efficiency of matrix cross approximation. The proposed algorithms are shown to have theoretical guarantees of convergence. Finally, we present two applications: image compression and the least squares approximation of continuous functions. Our numerical results at the end of the paper demonstrate the effective performance of our approach.
Read more8/7/2024

0
Dual Simplex Volume Maximization for Simplex-Structured Matrix Factorization
Maryam Abdolali, Giovanni Barbarino, Nicolas Gillis
Simplex-structured matrix factorization (SSMF) is a generalization of nonnegative matrix factorization, a fundamental interpretable data analysis model, and has applications in hyperspectral unmixing and topic modeling. To obtain identifiable solutions, a standard approach is to find minimum-volume solutions. By taking advantage of the duality/polarity concept for polytopes, we convert minimum-volume SSMF in the primal space to a maximum-volume problem in the dual space. We first prove the identifiability of this maximum-volume dual problem. Then, we use this dual formulation to provide a novel optimization approach which bridges the gap between two existing families of algorithms for SSMF, namely volume minimization and facet identification. Numerical experiments show that the proposed approach performs favorably compared to the state-of-the-art SSMF algorithms.
Read more4/1/2024
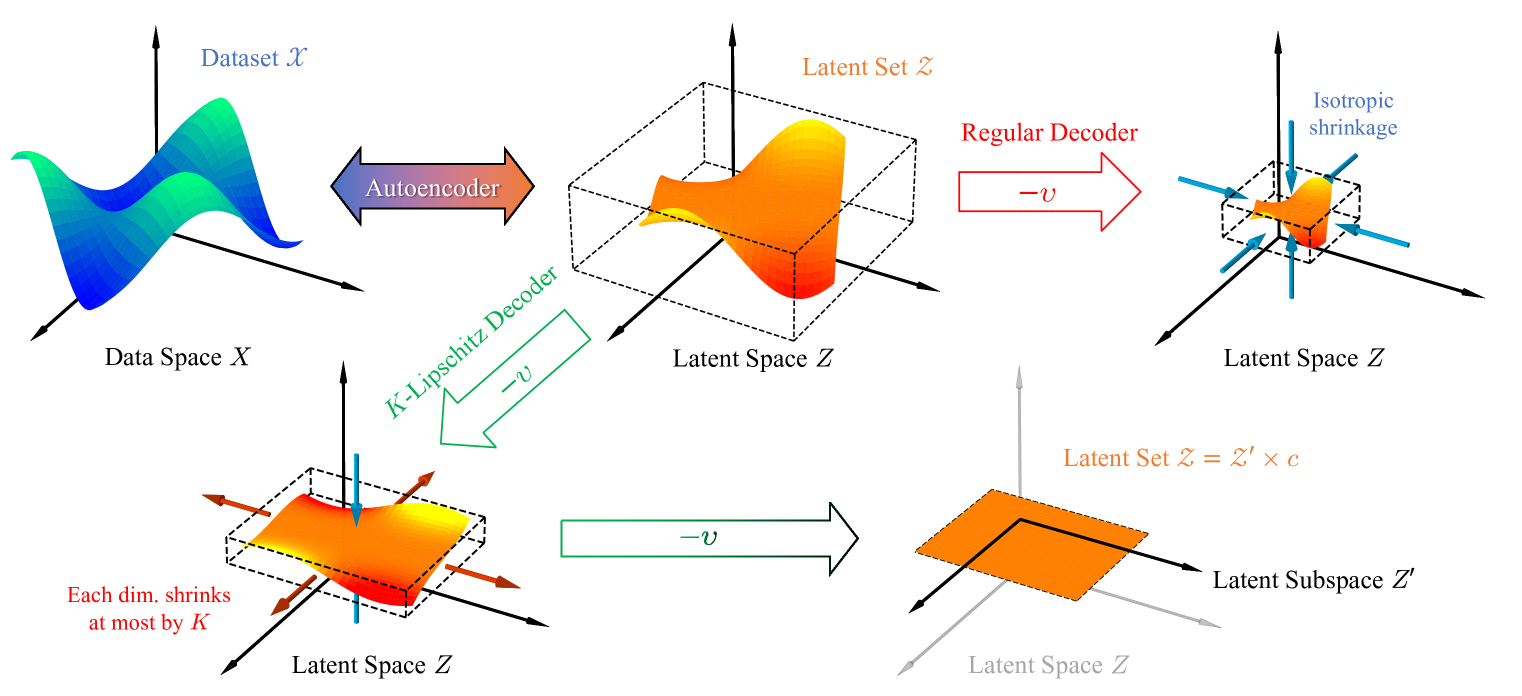
0
Compressing Latent Space via Least Volume
Qiuyi Chen, Mark Fuge
This paper introduces Least Volume-a simple yet effective regularization inspired by geometric intuition-that can reduce the necessary number of latent dimensions needed by an autoencoder without requiring any prior knowledge of the intrinsic dimensionality of the dataset. We show that the Lipschitz continuity of the decoder is the key to making it work, provide a proof that PCA is just a linear special case of it, and reveal that it has a similar PCA-like importance ordering effect when applied to nonlinear models. We demonstrate the intuition behind the regularization on some pedagogical toy problems, and its effectiveness on several benchmark problems, including MNIST, CIFAR-10 and CelebA.
Read more4/30/2024
⛏️
0
Adversarial Robust Low Rank Matrix Estimation: Compressed Sensing and Matrix Completion
Takeyuki Sasai, Hironori Fujisawa
We consider robust low rank matrix estimation as a trace regression when outputs are contaminated by adversaries. The adversaries are allowed to add arbitrary values to arbitrary outputs. Such values can depend on any samples. We deal with matrix compressed sensing, including lasso as a partial problem, and matrix completion, and then we obtain sharp estimation error bounds. To obtain the error bounds for different models such as matrix compressed sensing and matrix completion, we propose a simple unified approach based on a combination of the Huber loss function and the nuclear norm penalization, which is a different approach from the conventional ones. Some error bounds obtained in the present paper are sharper than the past ones.
Read more5/27/2024