DisCo: Disentangled Control for Realistic Human Dance Generation
2307.00040
0
0

Abstract
Generative AI has made significant strides in computer vision, particularly in text-driven image/video synthesis (T2I/T2V). Despite the notable advancements, it remains challenging in human-centric content synthesis such as realistic dance generation. Current methodologies, primarily tailored for human motion transfer, encounter difficulties when confronted with real-world dance scenarios (e.g., social media dance), which require to generalize across a wide spectrum of poses and intricate human details. In this paper, we depart from the traditional paradigm of human motion transfer and emphasize two additional critical attributes for the synthesis of human dance content in social media contexts: (i) Generalizability: the model should be able to generalize beyond generic human viewpoints as well as unseen human subjects, backgrounds, and poses; (ii) Compositionality: it should allow for the seamless composition of seen/unseen subjects, backgrounds, and poses from different sources. To address these challenges, we introduce DISCO, which includes a novel model architecture with disentangled control to improve the compositionality of dance synthesis, and an effective human attribute pre-training for better generalizability to unseen humans. Extensive qualitative and quantitative results demonstrate that DisCc can generate high-quality human dance images and videos with diverse appearances and flexible motions. Code is available at https://disco-dance.github.io/.
Create account to get full access
Overview
- This paper introduces DisCo, a method for generating human dance motions in the real world based on referring phrases.
- DisCo leverages a disentangled representation to independently control different aspects of the dance, such as style, rhythm, and motion, enabling fine-grained control over the generated dance.
- The model is trained on a large dataset of human dance videos and can generate diverse and realistic dance motions that correspond to natural language descriptions.
Plain English Explanation
DisCo is a system that can generate realistic human dance movements based on written descriptions. Rather than just copying existing dances, DisCo can create new dances that match the specified characteristics.
The key innovation is that DisCo separates the different elements of dance - like the style, the rhythm, and the specific movements - into independent parts of its internal representation. This "disentangled" approach allows the system to independently control each of these dance aspects, giving the user fine-grained control over the generated dance.
For example, a user could ask DisCo to create a "playful, upbeat ballet dance," and the system would generate a novel dance routine that matches those qualities, rather than just reproducing an existing ballet dance. This level of control and flexibility is a significant advance over previous dance generation systems.
DisCo is trained on a large dataset of human dance videos, allowing it to learn the characteristics of different dance styles and how they are expressed through movement. The system can then use this knowledge to generate diverse and realistic dance motions that correspond to natural language descriptions provided by the user.
Technical Explanation
DisCo is a deep learning model that takes a referring phrase as input and generates a corresponding dance motion sequence as output. The key innovation is its disentangled representation, which allows independent control over different aspects of the dance, such as style, rhythm, and motion.
The model consists of an encoder that maps the referring phrase into a disentangled latent space, and a decoder that generates the dance motion sequence from this latent representation. The latent space is structured to have separate dimensions for style, rhythm, and motion, enabling fine-grained control over the generated dance.
During training, the model is optimized to accurately reconstruct dance motion sequences from their corresponding referring phrases, while also ensuring that the latent representation is well-disentangled. This is achieved through a combination of reconstruction and disentanglement loss terms.
Experiments on a large dataset of human dance videos demonstrate that DisCo can generate diverse and realistic dance motions that closely match the semantics of the input referring phrases. Compared to previous dance generation approaches, DisCo offers significantly improved control and flexibility, allowing users to create custom dances with desired style, rhythm, and motion characteristics.
Critical Analysis
One potential limitation of DisCo is that it may struggle to generalize to completely novel dance styles or movements that are not well-represented in the training data. The model's ability to generate dance is still constrained by the diversity of the dataset it was trained on.
Additionally, the paper does not provide a comprehensive evaluation of the generated dances in terms of their realism, coherence, and suitability for real-world applications. Further user studies or perceptual evaluations would be needed to fully assess the practical utility of the DisCo system.
It would also be interesting to see how DisCo's disentangled representation could be leveraged for other dance-related tasks, such as dance style transfer or interactive dance choreography tools. Exploring the broader applications of this disentangled approach could help further demonstrate its value and significance.
Conclusion
DisCo represents a significant step forward in human dance generation by introducing a disentangled control mechanism that allows for fine-grained manipulation of dance characteristics. This approach enables the creation of diverse and customizable dance motions that closely match natural language descriptions, opening up new possibilities for interactive dance experiences and choreography tools.
While the current implementation has some limitations, the core ideas behind DisCo's disentangled representation could have broader implications for other areas of motion generation and control, such as human gesture generation, 3D animation, and video synthesis. Further research and development in this direction could lead to more advanced and versatile motion control systems, with applications across various domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
May the Dance be with You: Dance Generation Framework for Non-Humanoids
Hyemin Ahn
0
0
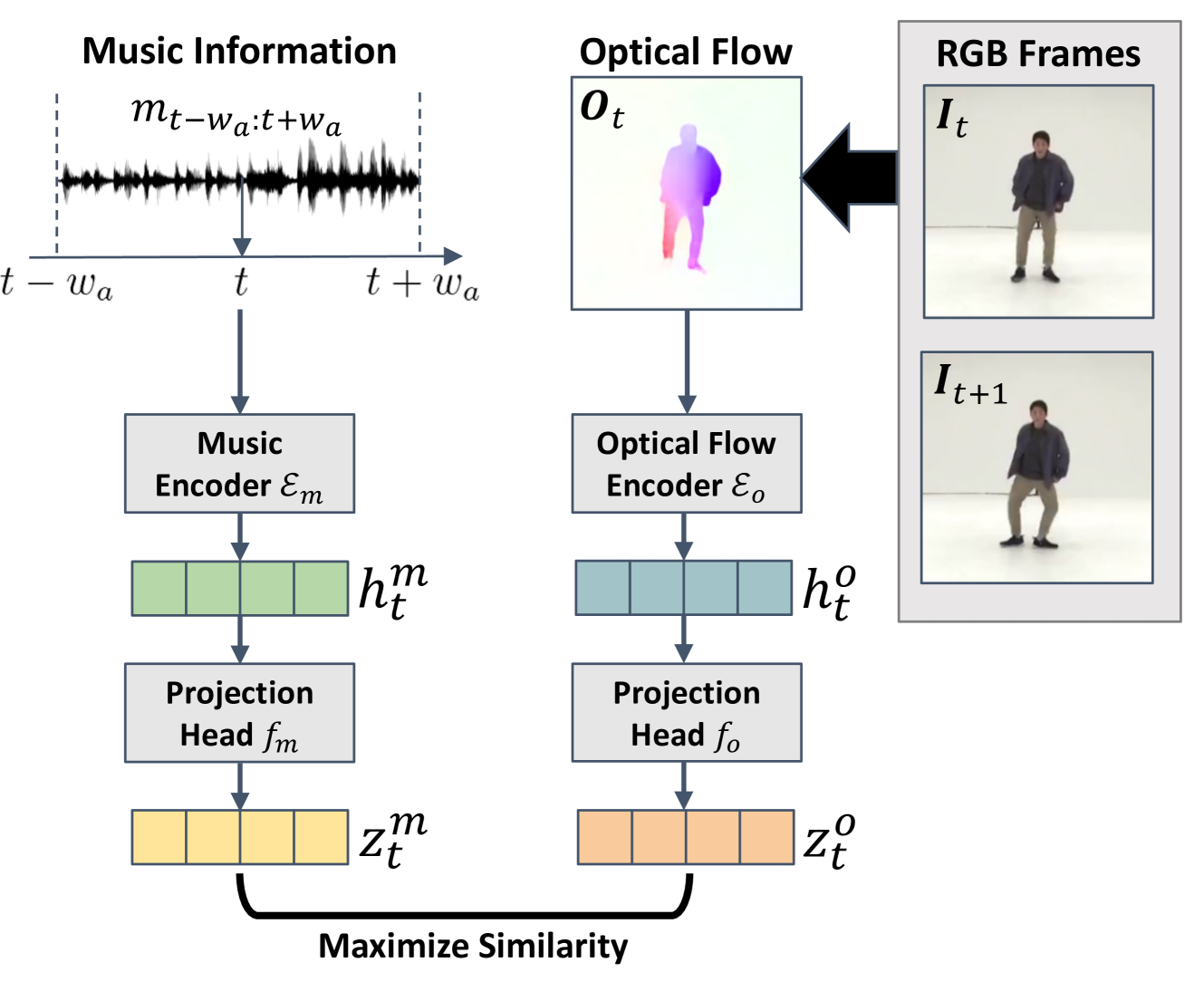
We hypothesize dance as a motion that forms a visual rhythm from music, where the visual rhythm can be perceived from an optical flow. If an agent can recognize the relationship between visual rhythm and music, it will be able to dance by generating a motion to create a visual rhythm that matches the music. Based on this, we propose a framework for any kind of non-humanoid agents to learn how to dance from human videos. Our framework works in two processes: (1) training a reward model which perceives the relationship between optical flow (visual rhythm) and music from human dance videos, (2) training the non-humanoid dancer based on that reward model, and reinforcement learning. Our reward model consists of two feature encoders for optical flow and music. They are trained based on contrastive learning which makes the higher similarity between concurrent optical flow and music features. With this reward model, the agent learns dancing by getting a higher reward when its action creates an optical flow whose feature has a higher similarity with the given music feature. Experiment results show that generated dance motion can align with the music beat properly, and user study result indicates that our framework is more preferred by humans compared to the baselines. To the best of our knowledge, our work of non-humanoid agents which learn dance from human videos is unprecedented. An example video can be found at https://youtu.be/dOUPvo-O3QY.
5/31/2024
🛸
InterControl: Zero-shot Human Interaction Generation by Controlling Every Joint
Zhenzhi Wang, Jingbo Wang, Yixuan Li, Dahua Lin, Bo Dai
0
0
Text-conditioned motion synthesis has made remarkable progress with the emergence of diffusion models. However, the majority of these motion diffusion models are primarily designed for a single character and overlook multi-human interactions. In our approach, we strive to explore this problem by synthesizing human motion with interactions for a group of characters of any size in a zero-shot manner. The key aspect of our approach is the adaptation of human-wise interactions as pairs of human joints that can be either in contact or separated by a desired distance. In contrast to existing methods that necessitate training motion generation models on multi-human motion datasets with a fixed number of characters, our approach inherently possesses the flexibility to model human interactions involving an arbitrary number of individuals, thereby transcending the limitations imposed by the training data. We introduce a novel controllable motion generation method, InterControl, to encourage the synthesized motions maintaining the desired distance between joint pairs. It consists of a motion controller and an inverse kinematics guidance module that realistically and accurately aligns the joints of synthesized characters to the desired location. Furthermore, we demonstrate that the distance between joint pairs for human-wise interactions can be generated using an off-the-shelf Large Language Model (LLM). Experimental results highlight the capability of our framework to generate interactions with multiple human characters and its potential to work with off-the-shelf physics-based character simulators.
6/18/2024

Harmonious Group Choreography with Trajectory-Controllable Diffusion
Yuqin Dai, Wanlu Zhu, Ronghui Li, Zeping Ren, Xiangzheng Zhou, Xiu Li, Jun Li, Jian Yang
0
0
Creating group choreography from music has gained attention in cultural entertainment and virtual reality, aiming to coordinate visually cohesive and diverse group movements. Despite increasing interest, recent works face challenges in achieving aesthetically appealing choreography, primarily for two key issues: multi-dancer collision and single-dancer foot slide. To address these issues, we propose a Trajectory-Controllable Diffusion (TCDiff), a novel approach that harnesses non-overlapping trajectories to facilitate coherent dance movements. Specifically, to tackle dancer collisions, we introduce a Dance-Beat Navigator capable of generating trajectories for multiple dancers based on the music, complemented by a Distance-Consistency loss to maintain appropriate spacing among trajectories within a reasonable threshold. To mitigate foot sliding, we present a Footwork Adaptor that utilizes trajectory displacement from adjacent frames to enable flexible footwork, coupled with a Relative Forward-Kinematic loss to adjust the positioning of individual dancers' root nodes and joints. Extensive experiments demonstrate that our method achieves state-of-the-art results.
6/7/2024
Diverse 3D Human Pose Generation in Scenes based on Decoupled Structure
Bowen Dang, Xi Zhao
0
0
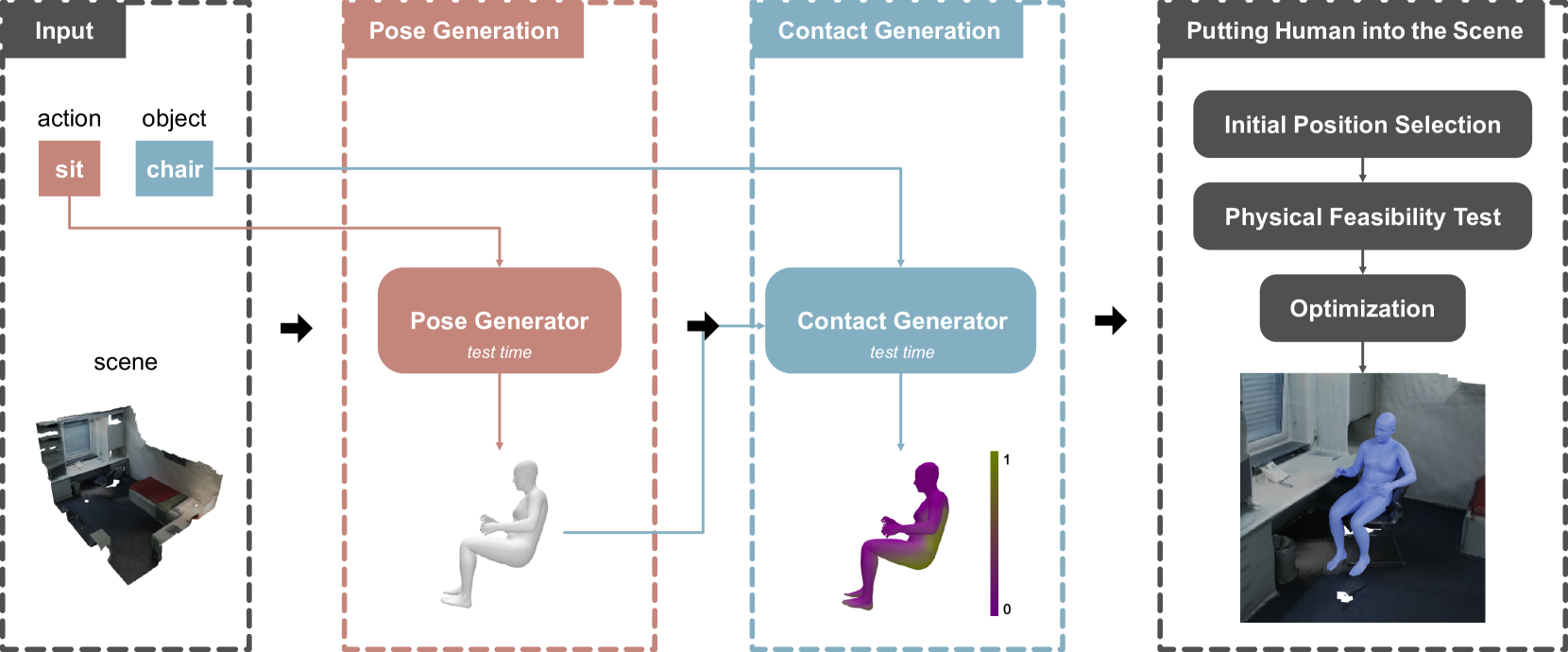
This paper presents a novel method for generating diverse 3D human poses in scenes with semantic control. Existing methods heavily rely on the human-scene interaction dataset, resulting in a limited diversity of the generated human poses. To overcome this challenge, we propose to decouple the pose and interaction generation process. Our approach consists of three stages: pose generation, contact generation, and putting human into the scene. We train a pose generator on the human dataset to learn rich pose prior, and a contact generator on the human-scene interaction dataset to learn human-scene contact prior. Finally, the placing module puts the human body into the scene in a suitable and natural manner. The experimental results on the PROX dataset demonstrate that our method produces more physically plausible interactions and exhibits more diverse human poses. Furthermore, experiments on the MP3D-R dataset further validates the generalization ability of our method.
6/11/2024