M$^3$AV: A Multimodal, Multigenre, and Multipurpose Audio-Visual Academic Lecture Dataset

0
Sign in to get full access
Overview
- This paper introduces M³AV, a novel multimodal, multigenre, and multipurpose audio-visual academic lecture dataset.
- The dataset contains high-quality video recordings of lectures across diverse academic disciplines, along with corresponding slide presentations and other supporting materials.
- The researchers designed M³AV to enable the development of advanced multimodal machine learning models for a variety of academic and educational applications.
Plain English Explanation
The researchers have created a new dataset called M³AV that contains recordings of university-level lectures, along with the slides and other materials used in those lectures. This dataset is special because it includes lectures from many different academic subjects, not just a single topic. The goal is to help researchers and developers create smarter AI systems that can understand and work with educational content in multiple formats, like video, audio, and text.
By having access to this diverse set of lecture materials, researchers can develop models that are better at processing and comprehending complex academic content. This could lead to improved educational technology, such as AI-powered virtual tutors or automated grading systems. The dataset could also be used to train models that can summarize lectures or translate them into different languages.
Overall, this new M³AV dataset provides a valuable resource for advancing the field of multimodal machine learning and creating smarter educational technologies.
Technical Explanation
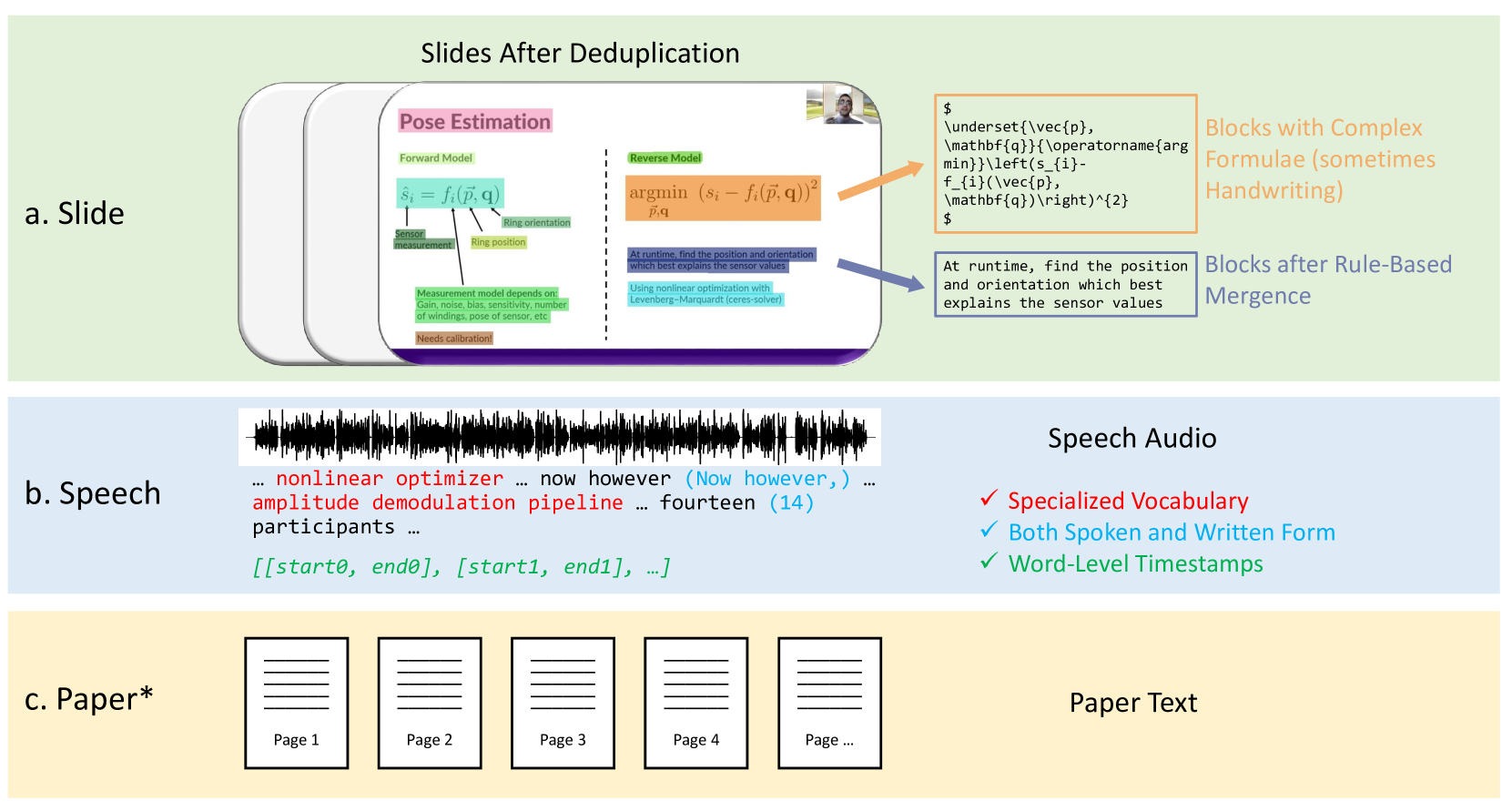
The M³AV dataset contains high-quality video recordings of academic lectures, along with corresponding slide presentations, instructor notes, and other supporting materials. The lectures span a diverse range of academic disciplines, including STEM fields, social sciences, and humanities.
To create the dataset, the researchers recruited volunteer instructors from various universities and recorded their lectures in a controlled studio environment. They then carefully annotated the video recordings, synchronizing them with the slide presentations and other supplementary content.
The key innovation of M³AV is its multimodal, multigenre, and multipurpose design. The multimodal aspect refers to the inclusion of both audio-visual lecture recordings and corresponding textual/visual materials. The multigenre aspect reflects the broad coverage of academic topics. And the multipurpose aspect indicates that the dataset can be used to train and evaluate a variety of machine learning models, such as those for multimodal content recognition, cross-modal translation, and multimodal summarization.
Critical Analysis
The M³AV dataset addresses an important gap in the availability of high-quality, multidisciplinary educational datasets for training multimodal machine learning models. However, the dataset is primarily focused on lecture-style academic content, which may limit its applicability to other educational formats, such as interactive tutorials or hands-on demonstrations.
Additionally, the controlled studio recording environment used to capture the lectures may not fully reflect the real-world challenges of processing audio-visual educational content, such as variations in recording quality, camera angles, and background noise. Further research is needed to assess the dataset's robustness and generalizability to more diverse educational settings.
The researchers also acknowledge the potential for biases in the dataset, as the lecture recordings were collected from a relatively small number of universities and instructors. Expanding the dataset to include a more geographically and demographically diverse set of educational materials could help address these concerns.
Conclusion
The M³AV dataset represents a significant contribution to the field of multimodal machine learning for educational applications. By providing a large, high-quality collection of academic lecture recordings and supporting materials, the dataset enables the development of advanced AI models that can better understand and interact with complex educational content.
The multipurpose design of M³AV also suggests its potential for a wide range of applications, from automated lecture summarization and translation to personalized learning assistants and intelligent tutoring systems. As the field of educational technology continues to evolve, resources like M³AV will play an increasingly important role in driving innovation and improving educational outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
M$^3$AV: A Multimodal, Multigenre, and Multipurpose Audio-Visual Academic Lecture Dataset
Zhe Chen, Heyang Liu, Wenyi Yu, Guangzhi Sun, Hongcheng Liu, Ji Wu, Chao Zhang, Yu Wang, Yanfeng Wang
Publishing open-source academic video recordings is an emergent and prevalent approach to sharing knowledge online. Such videos carry rich multimodal information including speech, the facial and body movements of the speakers, as well as the texts and pictures in the slides and possibly even the papers. Although multiple academic video datasets have been constructed and released, few of them support both multimodal content recognition and understanding tasks, which is partially due to the lack of high-quality human annotations. In this paper, we propose a novel multimodal, multigenre, and multipurpose audio-visual academic lecture dataset (M$^3$AV), which has almost 367 hours of videos from five sources covering computer science, mathematics, and medical and biology topics. With high-quality human annotations of the slide text and spoken words, in particular high-valued name entities, the dataset can be used for multiple audio-visual recognition and understanding tasks. Evaluations performed on contextual speech recognition, speech synthesis, and slide and script generation tasks demonstrate that the diversity of M$^3$AV makes it a challenging dataset.
Read more6/5/2024
👁️
0
Versatile audio-visual learning for emotion recognition
Lucas Goncalves, Seong-Gyun Leem, Wei-Cheng Lin, Berrak Sisman, Carlos Busso
Most current audio-visual emotion recognition models lack the flexibility needed for deployment in practical applications. We envision a multimodal system that works even when only one modality is available and can be implemented interchangeably for either predicting emotional attributes or recognizing categorical emotions. Achieving such flexibility in a multimodal emotion recognition system is difficult due to the inherent challenges in accurately interpreting and integrating varied data sources. It is also a challenge to robustly handle missing or partial information while allowing direct switch between regression or classification tasks. This study proposes a versatile audio-visual learning (VAVL) framework for handling unimodal and multimodal systems for emotion regression or emotion classification tasks. We implement an audio-visual framework that can be trained even when audio and visual paired data is not available for part of the training set (i.e., audio only or only video is present). We achieve this effective representation learning with audio-visual shared layers, residual connections over shared layers, and a unimodal reconstruction task. Our experimental results reveal that our architecture significantly outperforms strong baselines on the CREMA-D, MSP-IMPROV, and CMU-MOSEI corpora. Notably, VAVL attains a new state-of-the-art performance in the emotional attribute prediction task on the MSP-IMPROV corpus.
Read more7/31/2024
🌐
0
AV-Deepfake1M: A Large-Scale LLM-Driven Audio-Visual Deepfake Dataset
Zhixi Cai, Shreya Ghosh, Aman Pankaj Adatia, Munawar Hayat, Abhinav Dhall, Tom Gedeon, Kalin Stefanov
The detection and localization of highly realistic deepfake audio-visual content are challenging even for the most advanced state-of-the-art methods. While most of the research efforts in this domain are focused on detecting high-quality deepfake images and videos, only a few works address the problem of the localization of small segments of audio-visual manipulations embedded in real videos. In this research, we emulate the process of such content generation and propose the AV-Deepfake1M dataset. The dataset contains content-driven (i) video manipulations, (ii) audio manipulations, and (iii) audio-visual manipulations for more than 2K subjects resulting in a total of more than 1M videos. The paper provides a thorough description of the proposed data generation pipeline accompanied by a rigorous analysis of the quality of the generated data. The comprehensive benchmark of the proposed dataset utilizing state-of-the-art deepfake detection and localization methods indicates a significant drop in performance compared to previous datasets. The proposed dataset will play a vital role in building the next-generation deepfake localization methods. The dataset and associated code are available at https://github.com/ControlNet/AV-Deepfake1M .
Read more7/30/2024
🔮
0
Auto-ACD: A Large-scale Dataset for Audio-Language Representation Learning
Luoyi Sun, Xuenan Xu, Mengyue Wu, Weidi Xie
Recently, the AI community has made significant strides in developing powerful foundation models, driven by large-scale multimodal datasets. However, for audio representation learning, existing datasets suffer from limitations in the following aspects: insufficient volume, simplistic content, and arduous collection procedures. To establish an audio dataset with high-quality captions, we propose an innovative, automatic approach leveraging multimodal inputs, such as video frames, audio streams. Specifically, we construct a large-scale, high-quality, audio-language dataset, named as Auto-ACD, comprising over 1.5M audio-text pairs. We exploit a series of pre-trained models or APIs, to determine audio-visual synchronisation, generate image captions, object detection, or audio tags for specific videos. Subsequently, we employ LLM to paraphrase a congruent caption for each audio, guided by the extracted multi-modality clues. To demonstrate the effectiveness of the proposed dataset, we train widely used models on our dataset and show performance improvement on various downstream tasks, for example, audio-language retrieval, audio captioning, zero-shot classification. In addition, we establish a novel benchmark with environmental information and provide a benchmark for audio-text tasks.
Read more9/10/2024