Measuring Error Alignment for Decision-Making Systems

0

Sign in to get full access
Overview
- Measure how well a decision-making system's errors are aligned with human values and preferences
- Propose new metrics to quantify error alignment for AI systems
- Experiments to evaluate these metrics on large language models and other decision-making agents
Plain English Explanation
Measuring Error Alignment is crucial for ensuring AI Alignment - the idea that AI systems behave in a way that is consistent with human values and intentions. This paper introduces new ways to quantify the alignment between a system's errors and human preferences.
The key insight is that even if an AI system makes accurate predictions overall, its errors may not be aligned with what humans care about. For example, an AI assistant might be very good at answering questions, but make mistakes that disproportionately harm vulnerable populations. The proposed metrics aim to capture this mismatch between the system's mistakes and human values.
The authors test these new alignment metrics on large language models and other decision-making agents. This allows them to compare different alignment measures and gain insights into the complex relationship between a system's accuracy, its errors, and its overall behavioral alignment with human preferences.
Technical Explanation
The paper introduces several new metrics to quantify the alignment between a decision-making system's errors and human values:
- Error Alignment Score (EAS): Measures how well the system's errors are correlated with important human preferences.
- Weighted Error Alignment Score (WEAS): Extends EAS by allowing certain human preferences to be weighted more heavily.
- Rank-Weighted Error Alignment Score (RWEAS): Further extends WEAS by considering the ranking of errors, not just their magnitudes.
These metrics are evaluated on large language models and other AI agents making decisions across a range of tasks. The experiments show that high overall accuracy does not necessarily imply good error alignment, highlighting the importance of directly measuring this property.
The authors also explore how these alignment metrics relate to other evaluation frameworks, such as behavior alignment and sociotechnical understanding. This provides a more comprehensive view of how well an AI system's decisions and mistakes match human values and preferences.
Critical Analysis
The paper makes a compelling case for the importance of directly measuring error alignment, rather than relying solely on overall accuracy metrics. The proposed metrics provide a nuanced way to evaluate this crucial property of AI systems.
However, the authors acknowledge that these metrics are not a silver bullet. They may be sensitive to the specific choice of human preferences used in the evaluation, and can be challenging to apply in real-world scenarios with complex, multidimensional value structures.
Additionally, the experiments in the paper are limited to relatively narrow decision-making tasks. Further research is needed to understand how these alignment metrics scale and perform in more complex, open-ended domains where the potential for harmful mistakes is even greater.
Conclusion
This paper takes an important step towards quantifying the alignment between AI systems and human values. By focusing on the distribution of errors, rather than just overall accuracy, the proposed metrics provide a more nuanced way to evaluate the safety and reliability of decision-making agents.
As AI systems become more capable and influential, ensuring their errors are aligned with human preferences will be crucial for building trustworthy and beneficial technology. This research contributes to the broader effort to align AI with human values and create systems that reliably act in accordance with our interests.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Measuring Error Alignment for Decision-Making Systems
Binxia Xu, Antonis Bikakis, Daniel Onah, Andreas Vlachidis, Luke Dickens
Given that AI systems are set to play a pivotal role in future decision-making processes, their trustworthiness and reliability are of critical concern. Due to their scale and complexity, modern AI systems resist direct interpretation, and alternative ways are needed to establish trust in those systems, and determine how well they align with human values. We argue that good measures of the information processing similarities between AI and humans, may be able to achieve these same ends. While Representational alignment (RA) approaches measure similarity between the internal states of two systems, the associated data can be expensive and difficult to collect for human systems. In contrast, Behavioural alignment (BA) comparisons are cheaper and easier, but questions remain as to their sensitivity and reliability. We propose two new behavioural alignment metrics misclassification agreement which measures the similarity between the errors of two systems on the same instances, and class-level error similarity which measures the similarity between the error distributions of two systems. We show that our metrics correlate well with RA metrics, and provide complementary information to another BA metric, within a range of domains, and set the scene for a new approach to value alignment.
Read more9/24/2024
0
Quantifying Misalignment Between Agents
Aidan Kierans, Avijit Ghosh, Hananel Hazan, Shiri Dori-Hacohen
Existing work on the alignment problem has focused mainly on (1) qualitative descriptions of the alignment problem; (2) attempting to align AI actions with human interests by focusing on value specification and learning; and/or (3) focusing on a single agent or on humanity as a monolith. Recent sociotechnical approaches highlight the need to understand complex misalignment among multiple human and AI agents. We address this gap by adapting a computational social science model of human contention to the alignment problem. Our model quantifies misalignment in large, diverse agent groups with potentially conflicting goals across various problem areas. Misalignment scores in our framework depend on the observed agent population, the domain in question, and conflict between agents' weighted preferences. Through simulations, we demonstrate how our model captures intuitive aspects of misalignment across different scenarios. We then apply our model to two case studies, including an autonomous vehicle setting, showcasing its practical utility. Our approach offers enhanced explanatory power for complex sociotechnical environments and could inform the design of more aligned AI systems in real-world applications.
Read more9/10/2024
🤖
0
AI Alignment: A Comprehensive Survey
Jiaming Ji, Tianyi Qiu, Boyuan Chen, Borong Zhang, Hantao Lou, Kaile Wang, Yawen Duan, Zhonghao He, Jiayi Zhou, Zhaowei Zhang, Fanzhi Zeng, Kwan Yee Ng, Juntao Dai, Xuehai Pan, Aidan O'Gara, Yingshan Lei, Hua Xu, Brian Tse, Jie Fu, Stephen McAleer, Yaodong Yang, Yizhou Wang, Song-Chun Zhu, Yike Guo, Wen Gao
AI alignment aims to make AI systems behave in line with human intentions and values. As AI systems grow more capable, so do risks from misalignment. To provide a comprehensive and up-to-date overview of the alignment field, in this survey, we delve into the core concepts, methodology, and practice of alignment. First, we identify four principles as the key objectives of AI alignment: Robustness, Interpretability, Controllability, and Ethicality (RICE). Guided by these four principles, we outline the landscape of current alignment research and decompose them into two key components: forward alignment and backward alignment. The former aims to make AI systems aligned via alignment training, while the latter aims to gain evidence about the systems' alignment and govern them appropriately to avoid exacerbating misalignment risks. On forward alignment, we discuss techniques for learning from feedback and learning under distribution shift. On backward alignment, we discuss assurance techniques and governance practices. We also release and continually update the website (www.alignmentsurvey.com) which features tutorials, collections of papers, blog posts, and other resources.
Read more5/2/2024
0
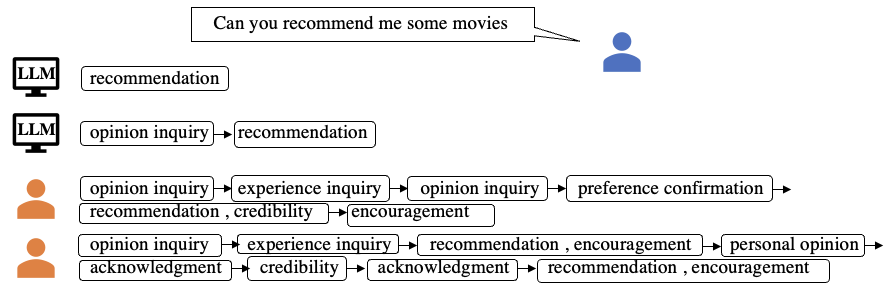
Behavior Alignment: A New Perspective of Evaluating LLM-based Conversational Recommendation Systems
Dayu Yang, Fumian Chen, Hui Fang
Large Language Models (LLMs) have demonstrated great potential in Conversational Recommender Systems (CRS). However, the application of LLMs to CRS has exposed a notable discrepancy in behavior between LLM-based CRS and human recommenders: LLMs often appear inflexible and passive, frequently rushing to complete the recommendation task without sufficient inquiry.This behavior discrepancy can lead to decreased accuracy in recommendations and lower user satisfaction. Despite its importance, existing studies in CRS lack a study about how to measure such behavior discrepancy. To fill this gap, we propose Behavior Alignment, a new evaluation metric to measure how well the recommendation strategies made by a LLM-based CRS are consistent with human recommenders'. Our experiment results show that the new metric is better aligned with human preferences and can better differentiate how systems perform than existing evaluation metrics. As Behavior Alignment requires explicit and costly human annotations on the recommendation strategies, we also propose a classification-based method to implicitly measure the Behavior Alignment based on the responses. The evaluation results confirm the robustness of the method.
Read more4/19/2024