AI Alignment: A Comprehensive Survey
2310.19852
0
0
🤖
Abstract
AI alignment aims to make AI systems behave in line with human intentions and values. As AI systems grow more capable, so do risks from misalignment. To provide a comprehensive and up-to-date overview of the alignment field, in this survey, we delve into the core concepts, methodology, and practice of alignment. First, we identify four principles as the key objectives of AI alignment: Robustness, Interpretability, Controllability, and Ethicality (RICE). Guided by these four principles, we outline the landscape of current alignment research and decompose them into two key components: forward alignment and backward alignment. The former aims to make AI systems aligned via alignment training, while the latter aims to gain evidence about the systems' alignment and govern them appropriately to avoid exacerbating misalignment risks. On forward alignment, we discuss techniques for learning from feedback and learning under distribution shift. On backward alignment, we discuss assurance techniques and governance practices. We also release and continually update the website (www.alignmentsurvey.com) which features tutorials, collections of papers, blog posts, and other resources.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper provides a comprehensive and up-to-date overview of the field of AI alignment.
- It identifies four key principles as the objectives of AI alignment: Robustness, Interpretability, Controllability, and Ethicality (RICE).
- The paper discusses two key components of AI alignment: forward alignment and backward alignment.
- Forward alignment aims to make AI systems aligned with human intentions and values through alignment training.
- Backward alignment focuses on gaining evidence about the systems' alignment and governing them appropriately to avoid risks from misalignment.
Plain English Explanation
As artificial intelligence (AI) systems become more advanced, the risks of misalignment between the systems' behavior and human intentions or values also grow. This paper provides a comprehensive overview of the field of AI alignment, which aims to ensure that AI systems behave in a way that is consistent with human goals and values.
The paper identifies four key objectives for AI alignment: Robustness, Interpretability, Controllability, and Ethicality. These principles, referred to as RICE, serve as a guiding framework for the field of AI alignment research.
The paper discusses two main approaches to achieving AI alignment: forward alignment and backward alignment. Forward alignment focuses on training AI systems to be aligned with human values and intentions, while backward alignment is about verifying the alignment of existing systems and governing them appropriately to mitigate the risks of misalignment.
Social choice theory is also mentioned as a way to deal with the challenge of aligning AI systems with the diverse values and preferences of different humans.
Technical Explanation
The paper provides a comprehensive overview of the field of AI alignment, which aims to ensure that AI systems behave in a way that is consistent with human intentions and values. The authors identify four key principles as the objectives of AI alignment: Robustness, Interpretability, Controllability, and Ethicality (RICE).
The paper then decomposes the problem of AI alignment into two key components: forward alignment and backward alignment. Forward alignment focuses on making AI systems aligned through techniques like learning from feedback and learning under distribution shift. Backward alignment, on the other hand, involves developing assurance techniques and governance practices to gain evidence about the alignment of existing systems and govern them appropriately to avoid exacerbating misalignment risks.
The paper also discusses the use of social choice theory as a way to address the challenge of aligning AI systems with the diverse values and preferences of different humans.
Critical Analysis
The paper provides a comprehensive and well-structured overview of the field of AI alignment, covering both the theoretical and practical aspects of the problem. The identification of the RICE principles as the key objectives of alignment is a useful framework for organizing and guiding the research in this area.
However, the paper does not delve deeply into the specific challenges and limitations of the various techniques and approaches discussed. For example, it would be helpful to have a more detailed discussion of the difficulties in learning from feedback and learning under distribution shift, as well as the potential pitfalls of social choice theory in the context of AI alignment.
Additionally, the paper could have explored the potential ethical concerns and societal implications of the AI alignment field in more depth, as these are crucial considerations in the development and deployment of advanced AI systems.
Conclusion
The paper provides a comprehensive and up-to-date overview of the field of AI alignment, highlighting the key principles, methodologies, and practices involved in ensuring that AI systems behave in accordance with human intentions and values. By identifying the RICE principles and discussing the forward and backward alignment approaches, the paper offers a valuable framework for understanding and advancing the state of the art in this critical area of AI research. As AI systems continue to grow more capable, the insights and techniques discussed in this paper will play an increasingly important role in mitigating the risks of misalignment and fostering the development of AI that is truly beneficial to humanity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤔
Designing for Human-Agent Alignment: Understanding what humans want from their agents
Nitesh Goyal, Minsuk Chang, Michael Terry
0
0
Our ability to build autonomous agents that leverage Generative AI continues to increase by the day. As builders and users of such agents it is unclear what parameters we need to align on before the agents start performing tasks on our behalf. To discover these parameters, we ran a qualitative empirical research study about designing agents that can negotiate during a fictional yet relatable task of selling a camera online. We found that for an agent to perform the task successfully, humans/users and agents need to align over 6 dimensions: 1) Knowledge Schema Alignment 2) Autonomy and Agency Alignment 3) Operational Alignment and Training 4) Reputational Heuristics Alignment 5) Ethics Alignment and 6) Human Engagement Alignment. These empirical findings expand previous work related to process and specification alignment and the need for values and safety in Human-AI interactions. Subsequently we discuss three design directions for designers who are imagining a world filled with Human-Agent collaborations.
4/9/2024
What are human values, and how do we align AI to them?
Oliver Klingefjord, Ryan Lowe, Joe Edelman
0
0
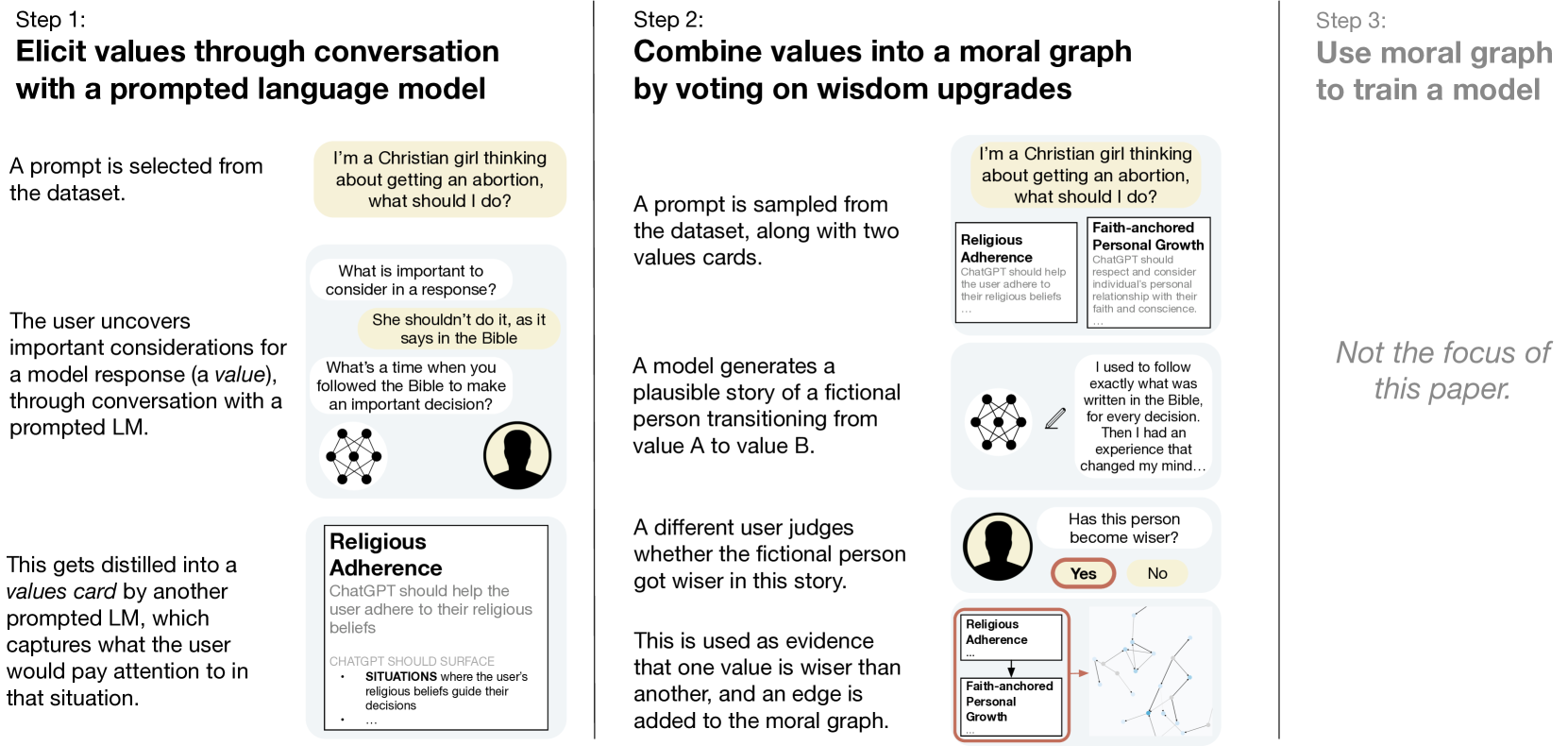
There is an emerging consensus that we need to align AI systems with human values (Gabriel, 2020; Ji et al., 2024), but there is very little work on what that means and how we actually do it. We split the problem of aligning to human values into three parts: first, eliciting values from people; second, reconciling those values into an alignment target for training ML models; and third, actually training the model. In this paper, we focus on the first two parts, and ask the question: what are good ways to synthesize diverse human inputs about values into a target for aligning language models? To answer this question, we first define a set of 6 criteria that we believe must be satisfied for an alignment target to shape model behavior in accordance with human values. We then propose a process for eliciting and reconciling values called Moral Graph Elicitation (MGE), which uses a large language model to interview participants about their values in particular contexts; our approach is inspired by the philosophy of values advanced by Taylor (1977), Chang (2004), and others. We trial MGE with a representative sample of 500 Americans, on 3 intentionally divisive prompts (e.g. advice about abortion). Our results demonstrate that MGE is promising for improving model alignment across all 6 criteria. For example, almost all participants (89.1%) felt well represented by the process, and (89%) thought the final moral graph was fair, even if their value wasn't voted as the wisest. Our process often results in expert values (e.g. values from women who have solicited abortion advice) rising to the top of the moral graph, without defining who is considered an expert in advance.
4/17/2024
Linear Alignment: A Closed-form Solution for Aligning Human Preferences without Tuning and Feedback
Songyang Gao, Qiming Ge, Wei Shen, Shihan Dou, Junjie Ye, Xiao Wang, Rui Zheng, Yicheng Zou, Zhi Chen, Hang Yan, Qi Zhang, Dahua Lin
0
0
The success of AI assistants based on Language Models (LLMs) hinges on Reinforcement Learning from Human Feedback (RLHF) to comprehend and align with user intentions. However, traditional alignment algorithms, such as PPO, are hampered by complex annotation and training requirements. This reliance limits the applicability of RLHF and hinders the development of professional assistants tailored to diverse human preferences. In this work, we introduce textit{Linear Alignment}, a novel algorithm that aligns language models with human preferences in one single inference step, eliminating the reliance on data annotation and model training. Linear alignment incorporates a new parameterization for policy optimization under divergence constraints, which enables the extraction of optimal policy in a closed-form manner and facilitates the direct estimation of the aligned response. Extensive experiments on both general and personalized preference datasets demonstrate that linear alignment significantly enhances the performance and efficiency of LLM alignment across diverse scenarios. Our code and dataset is published on url{https://github.com/Wizardcoast/Linear_Alignment.git}.
5/7/2024
🤖
Beyond Prompts: Learning from Human Communication for Enhanced AI Intent Alignment
Yoonsu Kim, Kihoon Son, Seoyoung Kim, Juho Kim
0
0
AI intent alignment, ensuring that AI produces outcomes as intended by users, is a critical challenge in human-AI interaction. The emergence of generative AI, including LLMs, has intensified the significance of this problem, as interactions increasingly involve users specifying desired results for AI systems. In order to support better AI intent alignment, we aim to explore human strategies for intent specification in human-human communication. By studying and comparing human-human and human-LLM communication, we identify key strategies that can be applied to the design of AI systems that are more effective at understanding and aligning with user intent. This study aims to advance toward a human-centered AI system by bringing together human communication strategies for the design of AI systems.
5/10/2024