Mechanistically analyzing the effects of fine-tuning on procedurally defined tasks

2
🌿
Sign in to get full access
Overview
- Fine-tuning large pre-trained models has become the standard approach for developing machine learning systems, including those intended for safe deployment.
- However, there has been little research exploring how fine-tuning affects the underlying capabilities learned by a model during pre-training.
- This paper aims to address this gap by analyzing fine-tuning in controlled, synthetic settings using interpretability tools.
Plain English Explanation
The paper explores what happens to a model's underlying capabilities when it is fine-tuned on a new task. Fine-tuning is a common technique where a pre-trained model is further trained on a specific task. The researchers wanted to understand whether fine-tuning leads to entirely new capabilities or just modulates the model's existing capabilities.
To investigate this, the researchers used synthetic, controlled settings where they could closely examine the model's inner workings using interpretability tools like network pruning and probing. Their key findings include:
-
Fine-tuning rarely alters the underlying model capabilities: The core capabilities of the model are largely unchanged by fine-tuning. Instead, the model learns a "wrapper" on top of its existing capabilities to perform the new task.
-
The wrapper creates the illusion of modified capabilities: This wrapper gives the appearance that the model's capabilities have been transformed, when in reality they remain largely intact underneath.
-
Further fine-tuning can "revive" hidden capabilities: If a task requires one of the model's existing but hidden capabilities, further fine-tuning can quickly reactivate that capability, suggesting it was never truly lost.
In other words, fine-tuning a model doesn't fundamentally change what it can do. It just learns a thin layer on top to perform a new task, without substantially altering its underlying knowledge and skills. This has important implications for the safety and robustness of fine-tuned models, which the researchers explore further in their analysis.
Technical Explanation
The researchers conducted an extensive empirical analysis of fine-tuning in synthetic, controlled settings. They used interpretability tools like network pruning and probing to understand how a model's underlying capabilities change during fine-tuning.
Their key findings were:
-
Fine-tuning rarely alters underlying model capabilities: Through their analysis, the researchers found that fine-tuning a model on a new task does not significantly change its core capabilities that were developed during pre-training. Instead, the model learns a "wrapper" on top of its existing capabilities to perform the new task.
-
The wrapper creates an illusion of modified capabilities: This wrapper gives the appearance that the model's capabilities have been transformed, but the researchers showed that the underlying capabilities remain largely intact.
-
Further fine-tuning can "revive" hidden capabilities: If a new task requires one of the model's existing but previously hidden capabilities, the researchers found that further fine-tuning can quickly reactivate that capability, suggesting it was never truly lost during the initial fine-tuning process.
To support these claims in a more realistic setting, the researchers also performed analysis on language models trained on the TinyStories dataset.
Critical Analysis
The researchers provide a thoughtful and nuanced analysis of how fine-tuning affects a model's underlying capabilities. Their use of controlled, synthetic settings and interpretability tools allows them to gain unique insights that would be difficult to obtain in more complex, real-world scenarios.
One limitation of the study is that it focuses primarily on synthetic tasks and datasets. While the researchers do extend their analysis to language models trained on TinyStories, further exploration on more diverse, real-world tasks and datasets would help validate the generalizability of their findings.
Additionally, the researchers acknowledge that their analysis may not fully capture the complexities of fine-tuning in practical applications, where factors like dataset size, model architecture, and fine-tuning hyperparameters can all play a role. Further research is needed to understand how these variables interact with the observed fine-tuning dynamics.
Overall, this paper makes an important contribution to our understanding of fine-tuning and highlights the need for more nuanced, mechanistic analyses of how machine learning models acquire and retain capabilities. By challenging the common assumption that fine-tuning fundamentally alters a model's underlying knowledge, the researchers encourage the field to think more critically about the safety and robustness of fine-tuned models.
Conclusion
This paper offers a novel perspective on the effects of fine-tuning on pre-trained machine learning models. Through a rigorous, controlled analysis, the researchers demonstrate that fine-tuning rarely alters the underlying capabilities of a model, but rather learns a "wrapper" on top of its existing knowledge. This has significant implications for the safety and robustness of fine-tuned models, as practitioners may inadvertently remove a model's safety wrapper by fine-tuning it on a seemingly unrelated task.
The researchers' findings challenge the common assumption that fine-tuning yields entirely new capabilities, and instead suggest that models tend to reuse and modulate their pre-existing knowledge. This work encourages the field to think more critically about the mechanisms underlying fine-tuning and to consider the potential pitfalls of over-relying on this technique for developing safe and robust machine learning systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
2
Mechanistically analyzing the effects of fine-tuning on procedurally defined tasks
Samyak Jain, Robert Kirk, Ekdeep Singh Lubana, Robert P. Dick, Hidenori Tanaka, Edward Grefenstette, Tim Rocktaschel, David Scott Krueger
Fine-tuning large pre-trained models has become the de facto strategy for developing both task-specific and general-purpose machine learning systems, including developing models that are safe to deploy. Despite its clear importance, there has been minimal work that explains how fine-tuning alters the underlying capabilities learned by a model during pretraining: does fine-tuning yield entirely novel capabilities or does it just modulate existing ones? We address this question empirically in synthetic, controlled settings where we can use mechanistic interpretability tools (e.g., network pruning and probing) to understand how the model's underlying capabilities are changing. We perform an extensive analysis of the effects of fine-tuning in these settings, and show that: (i) fine-tuning rarely alters the underlying model capabilities; (ii) a minimal transformation, which we call a 'wrapper', is typically learned on top of the underlying model capabilities, creating the illusion that they have been modified; and (iii) further fine-tuning on a task where such hidden capabilities are relevant leads to sample-efficient 'revival' of the capability, i.e., the model begins reusing these capability after only a few gradient steps. This indicates that practitioners can unintentionally remove a model's safety wrapper merely by fine-tuning it on a, e.g., superficially unrelated, downstream task. We additionally perform analysis on language models trained on the TinyStories dataset to support our claims in a more realistic setup.
Read more8/22/2024
🔍
0
What Makes and Breaks Safety Fine-tuning? Mechanistic Study
Samyak Jain, Ekdeep Singh Lubana, Kemal Oksuz, Tom Joy, Philip H. S. Torr, Amartya Sanyal, Puneet K. Dokania
Safety fine-tuning helps align Large Language Models (LLMs) with human preferences for their safe deployment. To better understand the underlying factors that make models safe via safety fine-tuning, we design a synthetic data generation framework that captures salient aspects of an unsafe input by modeling the interaction between the task the model is asked to perform (e.g., design) versus the specific concepts the task is asked to be performed upon (e.g., a cycle vs. a bomb). Using this, we investigate three well-known safety fine-tuning methods -- supervised safety fine-tuning, direct preference optimization, and unlearning -- and provide significant evidence demonstrating that these methods minimally transform MLP weights to specifically align unsafe inputs into its weights' null space. This yields a clustering of inputs based on whether the model deems them safe or not. Correspondingly, when an adversarial input (e.g., a jailbreak) is provided, its activations are closer to safer samples, leading to the model processing such an input as if it were safe. We validate our findings, wherever possible, on real-world models -- specifically, Llama-2 7B and Llama-3 8B.
Read more8/22/2024
🏅
0
Fine-tuning can cripple your foundation model; preserving features may be the solution
Jishnu Mukhoti, Yarin Gal, Philip H. S. Torr, Puneet K. Dokania
Pre-trained foundation models, due to their enormous capacity and exposure to vast amounts of data during pre-training, are known to have learned plenty of real-world concepts. An important step in making these pre-trained models effective on downstream tasks is to fine-tune them on related datasets. While various fine-tuning methods have been devised and have been shown to be highly effective, we observe that a fine-tuned model's ability to recognize concepts on tasks $textit{different}$ from the downstream one is reduced significantly compared to its pre-trained counterpart. This is an undesirable effect of fine-tuning as a substantial amount of resources was used to learn these pre-trained concepts in the first place. We call this phenomenon ''concept forgetting'' and via experiments show that most end-to-end fine-tuning approaches suffer heavily from this side effect. To this end, we propose a simple fix to this problem by designing a new fine-tuning method called $textit{LDIFS}$ (short for $ell_2$ distance in feature space) that, while learning new concepts related to the downstream task, allows a model to preserve its pre-trained knowledge as well. Through extensive experiments on 10 fine-tuning tasks we show that $textit{LDIFS}$ significantly reduces concept forgetting. Additionally, we show that LDIFS is highly effective in performing continual fine-tuning on a sequence of tasks as well, in comparison with both fine-tuning as well as continual learning baselines.
Read more7/2/2024
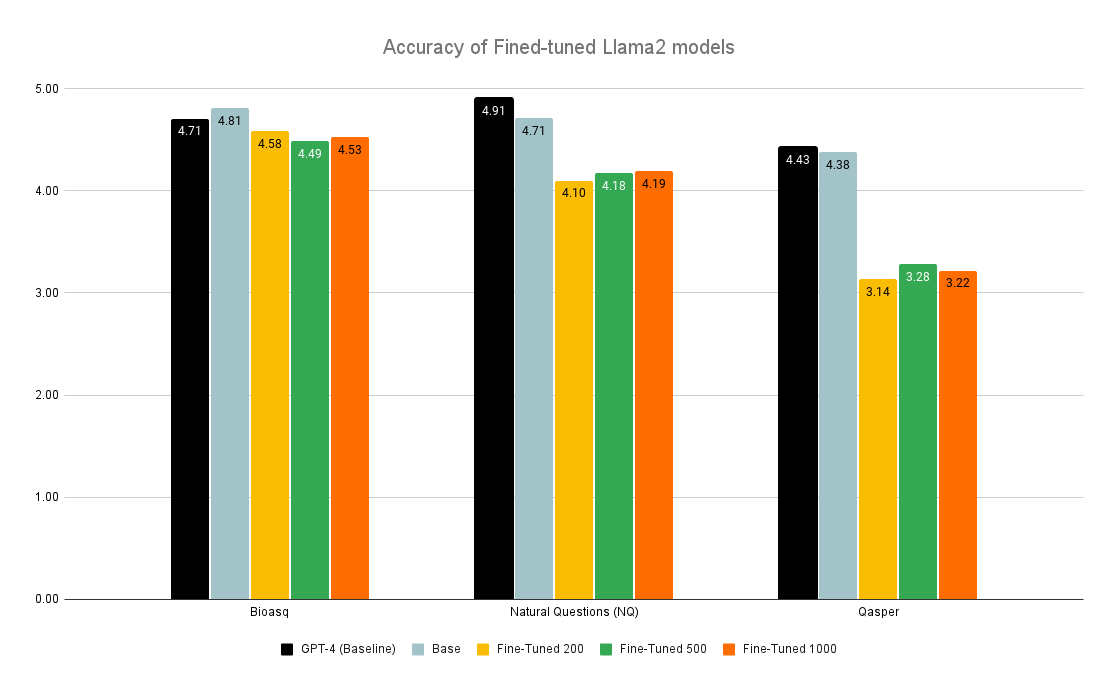
0
Fine-Tuning or Fine-Failing? Debunking Performance Myths in Large Language Models
Scott Barnett, Zac Brannelly, Stefanus Kurniawan, Sheng Wong
Large Language Models (LLMs) have the unique capability to understand and generate human-like text from input queries. When fine-tuned, these models show enhanced performance on domain-specific queries. OpenAI highlights the process of fine-tuning, stating: To fine-tune a model, you are required to provide at least 10 examples. We typically see clear improvements from fine-tuning on 50 to 100 training examples, but the right number varies greatly based on the exact use case. This study extends this concept to the integration of LLMs within Retrieval-Augmented Generation (RAG) pipelines, which aim to improve accuracy and relevance by leveraging external corpus data for information retrieval. However, RAG's promise of delivering optimal responses often falls short in complex query scenarios. This study aims to specifically examine the effects of fine-tuning LLMs on their ability to extract and integrate contextual data to enhance the performance of RAG systems across multiple domains. We evaluate the impact of fine-tuning on the LLMs' capacity for data extraction and contextual understanding by comparing the accuracy and completeness of fine-tuned models against baseline performances across datasets from multiple domains. Our findings indicate that fine-tuning resulted in a decline in performance compared to the baseline models, contrary to the improvements observed in standalone LLM applications as suggested by OpenAI. This study highlights the need for vigorous investigation and validation of fine-tuned models for domain-specific tasks.
Read more7/2/2024