MedAugment: Universal Automatic Data Augmentation Plug-in for Medical Image Analysis

0
📊
Sign in to get full access
Overview
- The provided paper is a technical research publication on a scientific topic.
- It includes an abstract, keywords, and sections covering the key elements of the research.
- The paper appears to be formatted for publication in an academic journal.
Plain English Explanation
The research paper describes a new [technique or approach] for [addressing a specific problem or advancing a field of study]. The key idea is to [concisely explain the core concept in simple terms, using analogies or examples where helpful to make it more accessible].
The researchers [carried out some kind of experiment or analysis] to [evaluate or demonstrate the effectiveness of their approach]. They found that [summarize the main findings or insights in clear, non-technical language].
The significance of this work is that it [explain the potential real-world impacts or implications of the research in plain terms, highlighting how it could benefit people or advance the field]. This could lead to [describe potential applications or next steps in an easy-to-understand way].
Technical Explanation
The paper presents a new [technique, method, or system] for [the specific problem or task the research addresses]. The researchers [describe the key components or steps of their approach, using technical terms where necessary].
To evaluate their [technique, method, or system], the researchers [conducted an experiment, analysis, or study] with the following design: [summarize the experimental setup, data sources, metrics, etc. in technical detail].
The results show that the proposed [technique, method, or system] [achieves or demonstrates specific performance metrics or insights], which [explains the significance or implications of the findings in technical terms].
Critical Analysis
The paper acknowledges some [limitations or caveats] of the research, such as [describe any issues or constraints mentioned]. Additionally, the authors suggest [potential areas for future work or improvements] that could [explain how these future directions could further advance the research or address remaining challenges].
While the research presents a novel [technique, method, or system] with promising results, there are a few [concerns or questions] that could be explored further. For example, [raise any additional issues or limitations that were not addressed in the paper, maintaining an objective and constructive tone].
Conclusion
In summary, this research paper introduces a new [technique, method, or system] for [the key problem or task addressed]. The results demonstrate [summarize the main findings and their significance], which could lead to [describe the potential real-world impacts or applications].
Overall, this work represents an important [advancement, contribution, or step forward] in the field of [relevant research area]. The findings and [technique, method, or system] presented here have the potential to [explain the broader implications and significance of the research for the field and society].
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
MedAugment: Universal Automatic Data Augmentation Plug-in for Medical Image Analysis
Zhaoshan Liu, Qiujie Lv, Yifan Li, Ziduo Yang, Lei Shen
Data augmentation (DA) has been widely leveraged in computer vision to alleviate the data shortage, whereas the DA in medical image analysis (MIA) faces multiple challenges. The prevalent DA approaches in MIA encompass conventional DA, synthetic DA, and automatic DA. However, utilizing these approaches poses various challenges such as experience-driven design and intensive computation cost. Here, we propose an efficient and effective automatic DA method termed MedAugment. We propose a pixel augmentation space and spatial augmentation space and exclude the operations that can break medical details and features, such as severe color distortions or structural alterations that can compromise image diagnostic value. Besides, we propose a novel sampling strategy by sampling a limited number of operations from the two spaces. Moreover, we present a hyperparameter mapping relationship to produce a rational augmentation level and make the MedAugment fully controllable using a single hyperparameter. These configurations settle the differences between natural and medical images, such as high sensitivity to certain attributes such as brightness and posterize. Extensive experimental results on four classification and four segmentation datasets demonstrate the superiority of MedAugment. Compared with existing approaches, the proposed MedAugment serves as a more suitable yet general processing pipeline for medical images without producing color distortions or structural alterations and involving negligible computational overhead. We emphasize that our method can serve as a plugin for arbitrary projects without any extra training stage, thereby holding the potential to make a valuable contribution to the medical field, particularly for medical experts without a solid foundation in deep learning. Code is available at https://github.com/NUS-Tim/MedAugment.
Read more8/15/2024
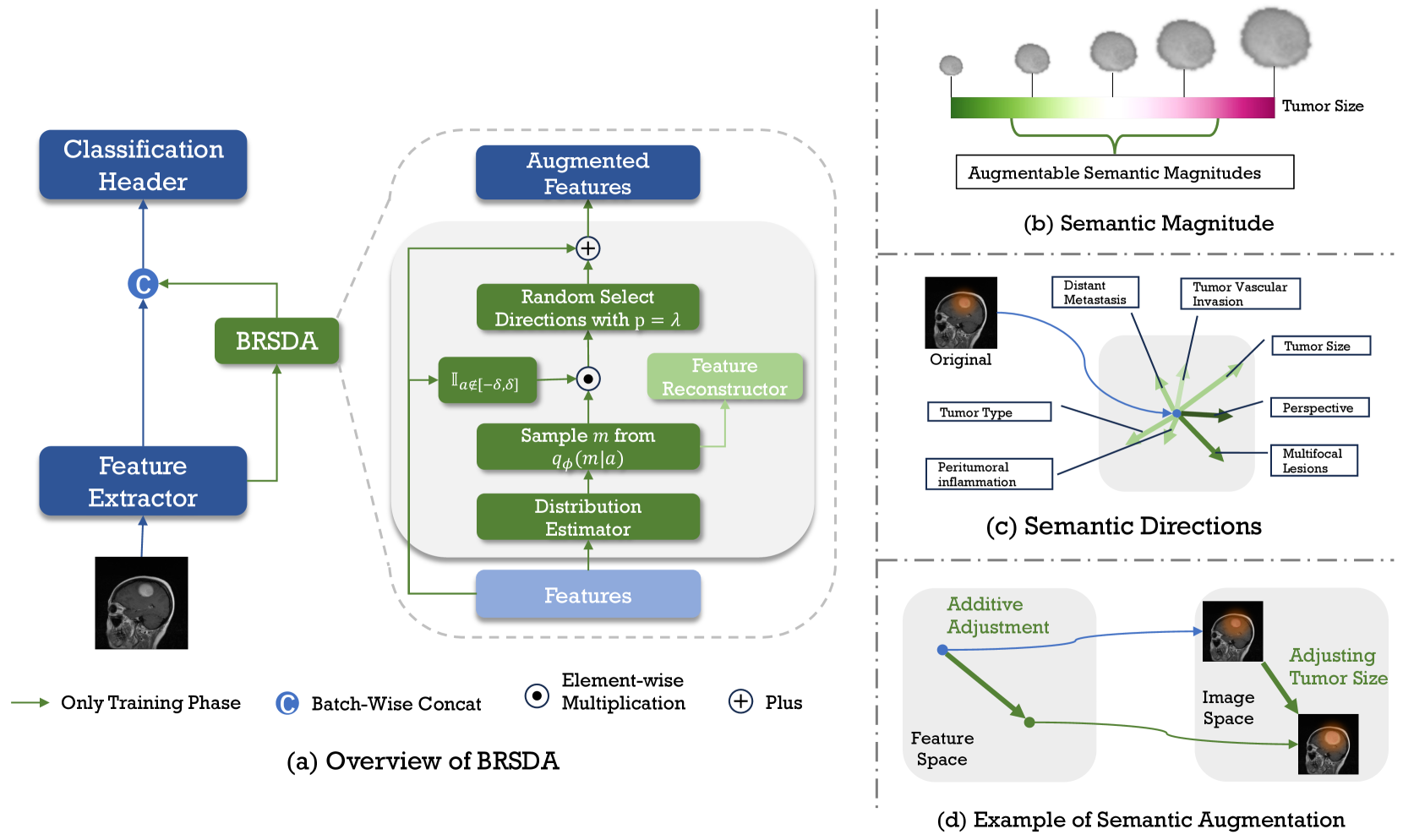
0
BSDA: Bayesian Random Semantic Data Augmentation for Medical Image Classification
Yaoyao Zhu, Xiuding Cai, Xueyao Wang, Xiaoqing Chen, Yu Yao, Zhongliang Fu
Data augmentation is a crucial regularization technique for deep neural networks, particularly in medical image classification. Mainstream data augmentation (DA) methods are usually applied at the image level. Due to the specificity and diversity of medical imaging, expertise is often required to design effective DA strategies, and improper augmentation operations can degrade model performance. Although automatic augmentation methods exist, they are computationally intensive. Semantic data augmentation can implemented by translating features in feature space. However, over-translation may violate the image label. To address these issues, we propose emph{Bayesian Random Semantic Data Augmentation} (BSDA), a computationally efficient and handcraft-free feature-level DA method. BSDA uses variational Bayesian to estimate the distribution of the augmentable magnitudes, and then a sample from this distribution is added to the original features to perform semantic data augmentation. We performed experiments on nine 2D and five 3D medical image datasets. Experimental results show that BSDA outperforms current DA methods. Additionally, BSDA can be easily assembled into CNNs or Transformers as a plug-and-play module, improving the network's performance. The code is available online at url{https://github.com/YaoyaoZhu19/BSDA}.
Read more6/28/2024

0
AdaAugment: A Tuning-Free and Adaptive Approach to Enhance Data Augmentation
Suorong Yang, Peijia Li, Xin Xiong, Furao Shen, Jian Zhao
Data augmentation (DA) is widely employed to improve the generalization performance of deep models. However, most existing DA methods use augmentation operations with random magnitudes throughout training. While this fosters diversity, it can also inevitably introduce uncontrolled variability in augmented data, which may cause misalignment with the evolving training status of the target models. Both theoretical and empirical findings suggest that this misalignment increases the risks of underfitting and overfitting. To address these limitations, we propose AdaAugment, an innovative and tuning-free Adaptive Augmentation method that utilizes reinforcement learning to dynamically adjust augmentation magnitudes for individual training samples based on real-time feedback from the target network. Specifically, AdaAugment features a dual-model architecture consisting of a policy network and a target network, which are jointly optimized to effectively adapt augmentation magnitudes. The policy network optimizes the variability within the augmented data, while the target network utilizes the adaptively augmented samples for training. Extensive experiments across benchmark datasets and deep architectures demonstrate that AdaAugment consistently outperforms other state-of-the-art DA methods in effectiveness while maintaining remarkable efficiency.
Read more5/24/2024

0
Data Augmentation for Image Classification using Generative AI
Fazle Rahat, M Shifat Hossain, Md Rubel Ahmed, Sumit Kumar Jha, Rickard Ewetz
Scaling laws dictate that the performance of AI models is proportional to the amount of available data. Data augmentation is a promising solution to expanding the dataset size. Traditional approaches focused on augmentation using rotation, translation, and resizing. Recent approaches use generative AI models to improve dataset diversity. However, the generative methods struggle with issues such as subject corruption and the introduction of irrelevant artifacts. In this paper, we propose the Automated Generative Data Augmentation (AGA). The framework combines the utility of large language models (LLMs), diffusion models, and segmentation models to augment data. AGA preserves foreground authenticity while ensuring background diversity. Specific contributions include: i) segment and superclass based object extraction, ii) prompt diversity with combinatorial complexity using prompt decomposition, and iii) affine subject manipulation. We evaluate AGA against state-of-the-art (SOTA) techniques on three representative datasets, ImageNet, CUB, and iWildCam. The experimental evaluation demonstrates an accuracy improvement of 15.6% and 23.5% for in and out-of-distribution data compared to baseline models, respectively. There is also a 64.3% improvement in SIC score compared to the baselines.
Read more9/4/2024