Medical Spoken Named Entity Recognition
2406.13337
0
0
Abstract
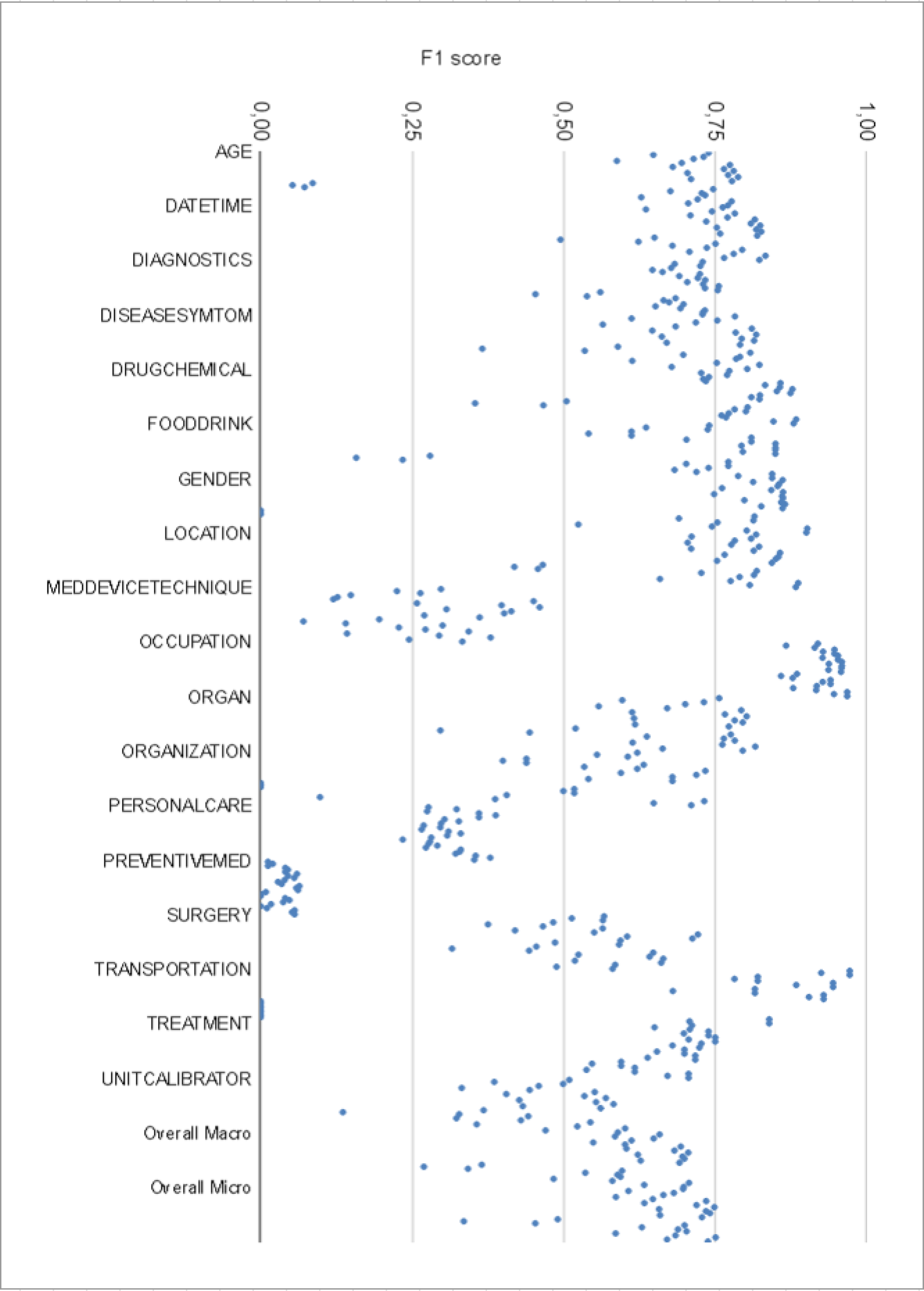
Spoken Named Entity Recognition (NER) aims to extracting named entities from speech and categorizing them into types like person, location, organization, etc. In this work, we present VietMed-NER - the first spoken NER dataset in the medical domain. To our best knowledge, our real-world dataset is the largest spoken NER dataset in the world in terms of the number of entity types, featuring 18 distinct types. Secondly, we present baseline results using various state-of-the-art pre-trained models: encoder-only and sequence-to-sequence. We found that pre-trained multilingual models XLM-R outperformed all monolingual models on both reference text and ASR output. Also in general, encoders perform better than sequence-to-sequence models for the NER task. By simply translating, the transcript is applicable not just to Vietnamese but to other languages as well. All code, data and models are made publicly available here: https://github.com/leduckhai/MultiMed
Create account to get full access
Overview
- This research paper focuses on medical spoken named entity recognition (Medical SNER), which aims to identify and classify important medical entities from spoken medical conversations.
- The paper introduces a new multilingual speech dataset for medical SNER, called MedicalSNER, which covers multiple languages including English, Vietnamese, and Mandarin Chinese.
- The researchers also propose several novel models and techniques to improve the performance of medical SNER, including leveraging large language models and handling accented speech.
Plain English Explanation
The research paper discusses the challenge of automatically identifying and categorizing important medical terms from spoken conversations between patients and healthcare providers. This is an important task for improving medical documentation, patient monitoring, and clinical decision support systems.
The researchers created a new dataset, called MedicalSNER, which contains transcripts of spoken medical conversations in multiple languages, including English, Vietnamese, and Mandarin Chinese. This dataset can be used to train and evaluate models for medical spoken named entity recognition.
The paper also presents several new techniques to improve the performance of these models. One approach is to leverage large language models, which are trained on massive amounts of text data, to help the models better understand medical terminology and context. Another technique focuses on handling accented speech, which can be a challenge for speech recognition systems, especially in medical settings with diverse patient populations.
Overall, this research aims to advance the state-of-the-art in automatically extracting and categorizing important medical information from spoken conversations, which could have significant benefits for healthcare workflows and patient care.
Technical Explanation
The researchers introduce a new multilingual dataset for medical spoken named entity recognition called MedicalSNER. The dataset contains transcripts of doctor-patient conversations in English, Vietnamese, and Mandarin Chinese, with named entities annotated across various medical categories such as medications, symptoms, and diagnoses.
To address the challenges of medical SNER, the paper proposes several novel models and techniques:
- VANER: a model that leverages large pre-trained language models to improve performance on medical SNER tasks, especially for low-resource languages.
- PerformantASR: a technique to build robust automatic speech recognition (ASR) models that can handle accented speech, a common issue in medical settings with diverse patient populations.
- VietMED: a dataset and benchmark for Vietnamese medical speech recognition, which can be used to evaluate models on accented speech.
The researchers conduct extensive experiments on the MedicalSNER dataset, evaluating the performance of their proposed models and techniques. They demonstrate significant improvements in medical SNER accuracy compared to baseline approaches, highlighting the value of their contributions.
Critical Analysis
The researchers have made a valuable contribution to the field of medical spoken named entity recognition by introducing a new multilingual dataset and proposing several innovative models and techniques. The MedicalSNER dataset is a particularly noteworthy contribution, as it provides a standardized benchmark for evaluating medical SNER systems across different languages.
However, the paper does not fully address the limitations of the proposed approaches. For example, the researchers acknowledge that their models may still struggle with rare or complex medical entities, and the performance on accented speech, while improved, may still have room for further enhancement.
Additionally, the paper does not provide a comprehensive analysis of the potential biases or ethical implications of the developed models. As medical SNER systems become more widely adopted, it will be important to ensure they are fair, unbiased, and respect patient privacy and data rights.
Future research in this area could explore ways to further improve model robustness, generalizability, and fairness, as well as investigate the real-world deployment and impact of medical SNER technologies in clinical settings.
Conclusion
This research paper makes significant advances in the field of medical spoken named entity recognition by introducing a new multilingual dataset, MedicalSNER, and proposing several novel modeling techniques, including VANER and PerformantASR.
The researchers demonstrate substantial improvements in medical SNER accuracy, particularly for low-resource languages and accented speech, which are common challenges in real-world medical settings. This work has the potential to enhance medical documentation, patient monitoring, and clinical decision support systems, ultimately leading to improved healthcare outcomes.
However, the paper also highlights the need for further research to address the limitations of the current approaches and ensure the ethical and responsible deployment of these technologies. By continuing to push the boundaries of medical SNER, researchers can make a lasting impact on the delivery of high-quality, equitable healthcare.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

MSNER: A Multilingual Speech Dataset for Named Entity Recognition
Quentin Meeus, Marie-Francine Moens, Hugo Van hamme
0
0
While extensively explored in text-based tasks, Named Entity Recognition (NER) remains largely neglected in spoken language understanding. Existing resources are limited to a single, English-only dataset. This paper addresses this gap by introducing MSNER, a freely available, multilingual speech corpus annotated with named entities. It provides annotations to the VoxPopuli dataset in four languages (Dutch, French, German, and Spanish). We have also releasing an efficient annotation tool that leverages automatic pre-annotations for faster manual refinement. This results in 590 and 15 hours of silver-annotated speech for training and validation, alongside a 17-hour, manually-annotated evaluation set. We further provide an analysis comparing silver and gold annotations. Finally, we present baseline NER models to stimulate further research on this newly available dataset.
5/21/2024
🗣️
VietMed: A Dataset and Benchmark for Automatic Speech Recognition of Vietnamese in the Medical Domain
Khai Le-Duc
0
0
Due to privacy restrictions, there's a shortage of publicly available speech recognition datasets in the medical domain. In this work, we present VietMed - a Vietnamese speech recognition dataset in the medical domain comprising 16h of labeled medical speech, 1000h of unlabeled medical speech and 1200h of unlabeled general-domain speech. To our best knowledge, VietMed is by far the world's largest public medical speech recognition dataset in 7 aspects: total duration, number of speakers, diseases, recording conditions, speaker roles, unique medical terms and accents. VietMed is also by far the largest public Vietnamese speech dataset in terms of total duration. Additionally, we are the first to present a medical ASR dataset covering all ICD-10 disease groups and all accents within a country. Moreover, we release the first public large-scale pre-trained models for Vietnamese ASR, w2v2-Viet and XLSR-53-Viet, along with the first public large-scale fine-tuned models for medical ASR. Even without any medical data in unsupervised pre-training, our best pre-trained model XLSR-53-Viet generalizes very well to the medical domain by outperforming state-of-the-art XLSR-53, from 51.8% to 29.6% WER on test set (a relative reduction of more than 40%). All code, data and models are made publicly available: https://github.com/leduckhai/MultiMed.
5/29/2024
Performant ASR Models for Medical Entities in Accented Speech
Tejumade Afonja, Tobi Olatunji, Sewade Ogun, Naome A. Etori, Abraham Owodunni, Moshood Yekini
0
0
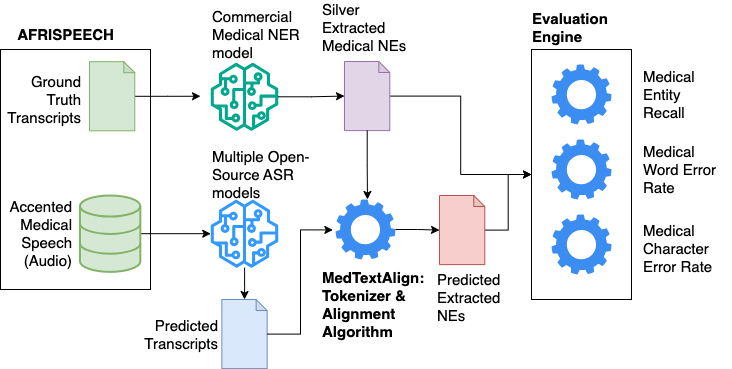
Recent strides in automatic speech recognition (ASR) have accelerated their application in the medical domain where their performance on accented medical named entities (NE) such as drug names, diagnoses, and lab results, is largely unknown. We rigorously evaluate multiple ASR models on a clinical English dataset of 93 African accents. Our analysis reveals that despite some models achieving low overall word error rates (WER), errors in clinical entities are higher, potentially posing substantial risks to patient safety. To empirically demonstrate this, we extract clinical entities from transcripts, develop a novel algorithm to align ASR predictions with these entities, and compute medical NE Recall, medical WER, and character error rate. Our results show that fine-tuning on accented clinical speech improves medical WER by a wide margin (25-34 % relative), improving their practical applicability in healthcare environments.
6/19/2024
VANER: Leveraging Large Language Model for Versatile and Adaptive Biomedical Named Entity Recognition
Junyi Biana, Weiqi Zhai, Xiaodi Huang, Jiaxuan Zheng, Shanfeng Zhu
0
0
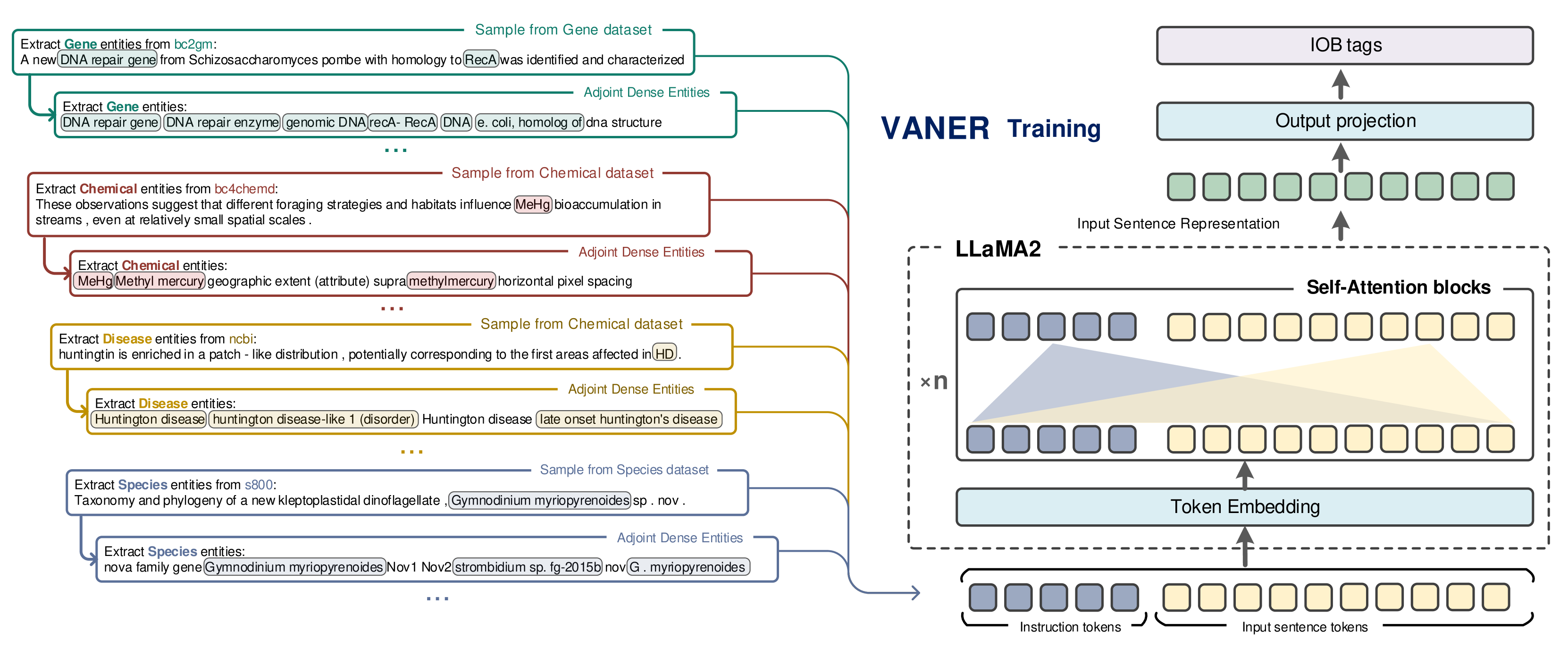
Prevalent solution for BioNER involves using representation learning techniques coupled with sequence labeling. However, such methods are inherently task-specific, demonstrate poor generalizability, and often require dedicated model for each dataset. To leverage the versatile capabilities of recently remarkable large language models (LLMs), several endeavors have explored generative approaches to entity extraction. Yet, these approaches often fall short of the effectiveness of previouly sequence labeling approaches. In this paper, we utilize the open-sourced LLM LLaMA2 as the backbone model, and design specific instructions to distinguish between different types of entities and datasets. By combining the LLM's understanding of instructions with sequence labeling techniques, we use mix of datasets to train a model capable of extracting various types of entities. Given that the backbone LLMs lacks specialized medical knowledge, we also integrate external entity knowledge bases and employ instruction tuning to compel the model to densely recognize carefully curated entities. Our model VANER, trained with a small partition of parameters, significantly outperforms previous LLMs-based models and, for the first time, as a model based on LLM, surpasses the majority of conventional state-of-the-art BioNER systems, achieving the highest F1 scores across three datasets.
4/30/2024