VietMed: A Dataset and Benchmark for Automatic Speech Recognition of Vietnamese in the Medical Domain
2404.05659
0
0
🗣️
Abstract
Due to privacy restrictions, there's a shortage of publicly available speech recognition datasets in the medical domain. In this work, we present VietMed - a Vietnamese speech recognition dataset in the medical domain comprising 16h of labeled medical speech, 1000h of unlabeled medical speech and 1200h of unlabeled general-domain speech. To our best knowledge, VietMed is by far the world's largest public medical speech recognition dataset in 7 aspects: total duration, number of speakers, diseases, recording conditions, speaker roles, unique medical terms and accents. VietMed is also by far the largest public Vietnamese speech dataset in terms of total duration. Additionally, we are the first to present a medical ASR dataset covering all ICD-10 disease groups and all accents within a country. Moreover, we release the first public large-scale pre-trained models for Vietnamese ASR, w2v2-Viet and XLSR-53-Viet, along with the first public large-scale fine-tuned models for medical ASR. Even without any medical data in unsupervised pre-training, our best pre-trained model XLSR-53-Viet generalizes very well to the medical domain by outperforming state-of-the-art XLSR-53, from 51.8% to 29.6% WER on test set (a relative reduction of more than 40%). All code, data and models are made publicly available: https://github.com/leduckhai/MultiMed.
Create account to get full access
Overview
- This paper presents VietMed, a large-scale Vietnamese speech recognition dataset in the medical domain.
- VietMed includes 16 hours of labeled medical speech, 1000 hours of unlabeled medical speech, and 1200 hours of unlabeled general-domain speech.
- VietMed is the world's largest public medical speech recognition dataset in multiple aspects, including total duration, number of speakers, diseases covered, recording conditions, speaker roles, unique medical terms, and accents.
- The authors also release pre-trained and fine-tuned speech recognition models for Vietnamese, including the first public large-scale models for medical ASR.
Plain English Explanation
Speech recognition technology is becoming increasingly important in the medical field, as it can help healthcare providers more efficiently document patient information and interactions. However, a lack of publicly available datasets in the medical domain has posed a challenge for developing accurate speech recognition models.
To address this, the researchers created VietMed, a large-scale dataset of Vietnamese medical speech. This dataset includes over 16 hours of labeled medical speech, 1000 hours of unlabeled medical speech, and 1200 hours of unlabeled general-domain speech.
What makes VietMed unique is its size and comprehensiveness. It is the largest public medical speech recognition dataset in the world, covering a wide range of medical topics, speaker roles, recording conditions, and accents. This diversity helps ensure the models trained on VietMed can handle the real-world variability found in medical settings.
In addition to the dataset, the researchers also released pre-trained and fine-tuned speech recognition models for Vietnamese, including models specifically adapted for the medical domain. These models can serve as a valuable starting point for others working on speech recognition in the Vietnamese language, particularly in medical applications.
Technical Explanation
The researchers created the VietMed dataset to address the lack of publicly available speech recognition datasets in the medical domain, particularly for the Vietnamese language. VietMed includes 16 hours of labeled medical speech, 1000 hours of unlabeled medical speech, and 1200 hours of unlabeled general-domain speech.
Compared to other publicly available datasets, VietMed is the largest in several key aspects:
- Total duration: VietMed has over 2,200 hours of audio, far exceeding other medical speech datasets.
- Number of speakers: VietMed includes speech from thousands of speakers, providing greater diversity.
- Diseases covered: VietMed covers all 22 disease groups in the ICD-10 classification system.
- Recording conditions: The dataset includes speech recorded in various clinical settings, such as hospitals and clinics.
- Speaker roles: VietMed includes speech from healthcare providers, patients, and administrative staff.
- Unique medical terms: The dataset contains a large vocabulary of specialized medical terminology.
- Accents: VietMed represents all major accents within Vietnam, ensuring the models can handle diverse pronunciation.
In addition to the dataset, the researchers released pre-trained speech recognition models for Vietnamese, including w2v2-Viet and XLSR-53-Viet. They also fine-tuned these models on the VietMed dataset, creating specialized medical ASR models.
Interestingly, the researchers found that even without any medical data in the unsupervised pre-training, the XLSR-53-Viet model was able to generalize well to the medical domain. On the VietMed test set, XLSR-53-Viet achieved a word error rate (WER) of 29.6%, outperforming the base XLSR-53 model's WER of 51.8% - a relative reduction of over 40%.
Critical Analysis
The researchers have done an impressive job in creating the VietMed dataset and releasing high-quality pre-trained and fine-tuned speech recognition models. The dataset's breadth and depth are particularly noteworthy, making it a valuable resource for the research community.
However, the paper does not provide much insight into the specific challenges or limitations encountered during the data collection process. For example, it would be helpful to know more about the distribution of speaker demographics, the quality control measures used, or any biases present in the data.
Additionally, while the researchers demonstrate the effectiveness of their models on the VietMed test set, it would be informative to see how the models perform on other medical speech recognition benchmarks, such as those used in comprehensive studies of language models for clinical and biomedical applications. This would give a better sense of the models' generalization capabilities.
Overall, the VietMed dataset and associated models are a significant contribution to the field of medical speech recognition, particularly for the Vietnamese language. With continued research and refinement, these resources have the potential to greatly improve the efficiency and accuracy of medical documentation and patient-provider interactions.
Conclusion
In this work, the researchers have presented VietMed, a large-scale Vietnamese speech recognition dataset focused on the medical domain. VietMed is the world's largest public medical speech dataset, covering a wide range of medical topics, speaker roles, recording conditions, and accents.
The researchers have also released pre-trained and fine-tuned speech recognition models for Vietnamese, including the first public large-scale models for medical ASR. These models demonstrate impressive performance on the VietMed dataset, highlighting the potential of this resource to advance speech recognition technology in the medical field.
Overall, the VietMed dataset and associated models are a significant contribution to the research community, providing a valuable tool for developing more accurate and robust medical speech recognition systems, particularly for the Vietnamese language.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
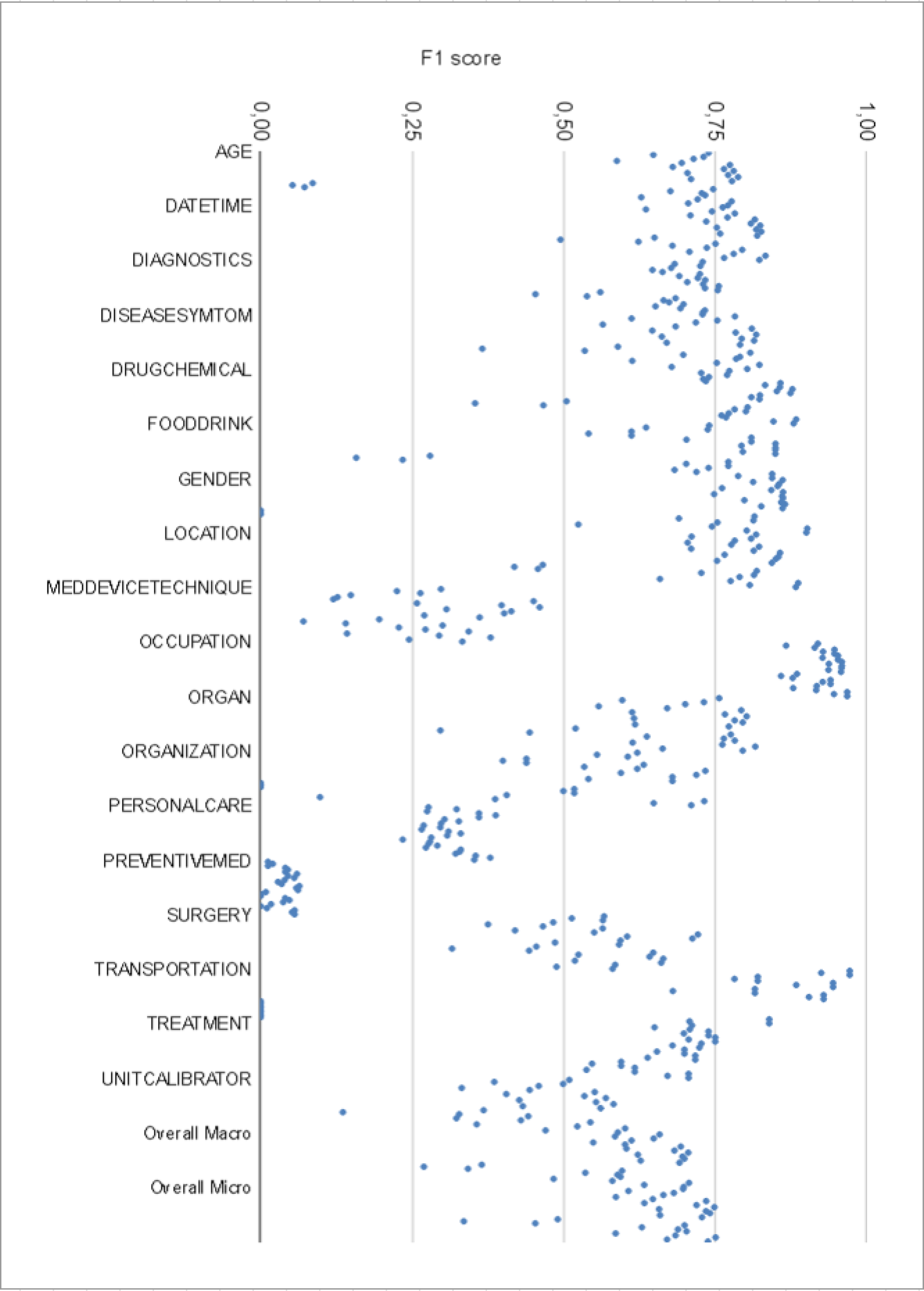
Medical Spoken Named Entity Recognition
Khai Le-Duc
0
0
Spoken Named Entity Recognition (NER) aims to extracting named entities from speech and categorizing them into types like person, location, organization, etc. In this work, we present VietMed-NER - the first spoken NER dataset in the medical domain. To our best knowledge, our real-world dataset is the largest spoken NER dataset in the world in terms of the number of entity types, featuring 18 distinct types. Secondly, we present baseline results using various state-of-the-art pre-trained models: encoder-only and sequence-to-sequence. We found that pre-trained multilingual models XLM-R outperformed all monolingual models on both reference text and ASR output. Also in general, encoders perform better than sequence-to-sequence models for the NER task. By simply translating, the transcript is applicable not just to Vietnamese but to other languages as well. All code, data and models are made publicly available here: https://github.com/leduckhai/MultiMed
6/21/2024

Real-time Speech Summarization for Medical Conversations
Khai Le-Duc, Khai-Nguyen Nguyen, Long Vo-Dang, Truong-Son Hy
0
0
In doctor-patient conversations, identifying medically relevant information is crucial, posing the need for conversation summarization. In this work, we propose the first deployable real-time speech summarization system for real-world applications in industry, which generates a local summary after every N speech utterances within a conversation and a global summary after the end of a conversation. Our system could enhance user experience from a business standpoint, while also reducing computational costs from a technical perspective. Secondly, we present VietMed-Sum which, to our knowledge, is the first speech summarization dataset for medical conversations. Thirdly, we are the first to utilize LLM and human annotators collaboratively to create gold standard and synthetic summaries for medical conversation summarization. Finally, we present baseline results of state-of-the-art models on VietMed-Sum. All code, data (English-translated and Vietnamese) and models are available online: https://github.com/leduckhai/MultiMed
6/26/2024
🗣️
PhoWhisper: Automatic Speech Recognition for Vietnamese
Thanh-Thien Le, Linh The Nguyen, Dat Quoc Nguyen
0
0
We introduce PhoWhisper in five versions for Vietnamese automatic speech recognition. PhoWhisper's robustness is achieved through fine-tuning the Whisper model on an 844-hour dataset that encompasses diverse Vietnamese accents. Our experimental study demonstrates state-of-the-art performances of PhoWhisper on benchmark Vietnamese ASR datasets. We have open-sourced PhoWhisper at: https://github.com/VinAIResearch/PhoWhisper
6/6/2024

Automatic Speech Recognition for Biomedical Data in Bengali Language
Shariar Kabir, Nazmun Nahar, Shyamasree Saha, Mamunur Rashid
0
0
This paper presents the development of a prototype Automatic Speech Recognition (ASR) system specifically designed for Bengali biomedical data. Recent advancements in Bengali ASR are encouraging, but a lack of domain-specific data limits the creation of practical healthcare ASR models. This project bridges this gap by developing an ASR system tailored for Bengali medical terms like symptoms, severity levels, and diseases, encompassing two major dialects: Bengali and Sylheti. We train and evaluate two popular ASR frameworks on a comprehensive 46-hour Bengali medical corpus. Our core objective is to create deployable health-domain ASR systems for digital health applications, ultimately increasing accessibility for non-technical users in the healthcare sector.
6/21/2024