MedNeXt: Transformer-driven Scaling of ConvNets for Medical Image Segmentation
2303.09975
0
0
🖼️
Abstract
There has been exploding interest in embracing Transformer-based architectures for medical image segmentation. However, the lack of large-scale annotated medical datasets make achieving performances equivalent to those in natural images challenging. Convolutional networks, in contrast, have higher inductive biases and consequently, are easily trainable to high performance. Recently, the ConvNeXt architecture attempted to modernize the standard ConvNet by mirroring Transformer blocks. In this work, we improve upon this to design a modernized and scalable convolutional architecture customized to challenges of data-scarce medical settings. We introduce MedNeXt, a Transformer-inspired large kernel segmentation network which introduces - 1) A fully ConvNeXt 3D Encoder-Decoder Network for medical image segmentation, 2) Residual ConvNeXt up and downsampling blocks to preserve semantic richness across scales, 3) A novel technique to iteratively increase kernel sizes by upsampling small kernel networks, to prevent performance saturation on limited medical data, 4) Compound scaling at multiple levels (depth, width, kernel size) of MedNeXt. This leads to state-of-the-art performance on 4 tasks on CT and MRI modalities and varying dataset sizes, representing a modernized deep architecture for medical image segmentation. Our code is made publicly available at: https://github.com/MIC-DKFZ/MedNeXt.
Create account to get full access
Overview
- The paper discusses the challenges of achieving high-performance medical image segmentation using Transformer-based architectures due to the lack of large-annotated datasets.
- It introduces MedNeXt, a modernized and scalable convolutional architecture inspired by Transformers, designed to address the data scarcity challenges in medical settings.
- MedNeXt incorporates several key innovations, including a 3D Encoder-Decoder Network, Residual ConvNeXt blocks, and a novel technique to iteratively increase kernel sizes.
Plain English Explanation
Medical image segmentation is the process of dividing an image, such as an MRI or CT scan, into meaningful parts or regions. This is an important task in healthcare, as it can help doctors and researchers better understand and diagnose medical conditions.
Recently, there has been a lot of interest in using Transformer-based models for medical image segmentation. Transformers are a type of deep learning architecture that have been very successful in natural language processing. However, the lack of large, well-annotated medical datasets makes it challenging to achieve the same high performance with Transformers in the medical domain as in natural images.
In contrast, convolutional neural networks (ConvNets) have been more easily trainable to high performance on medical data, thanks to their strong inductive biases. The ConvNeXt architecture attempted to modernize the standard ConvNet by incorporating Transformer-like blocks.
Building on this, the researchers introduced MedNeXt, a Transformer-inspired convolutional architecture designed specifically for medical image segmentation in data-scarce settings. MedNeXt includes several key innovations:
- A fully ConvNeXt 3D Encoder-Decoder Network for medical image segmentation.
- Residual ConvNeXt up and downsampling blocks to preserve semantic richness across scales.
- A novel technique to iteratively increase kernel sizes by upsampling small kernel networks, to prevent performance saturation on limited medical data.
- Compound scaling at multiple levels (depth, width, kernel size) of MedNeXt.
These innovations allow MedNeXt to achieve state-of-the-art performance on a variety of medical image segmentation tasks, including CT and MRI scans across different dataset sizes. MedNeXt represents a modernized deep learning architecture well-suited for the challenges of medical image segmentation.
Technical Explanation
The paper presents MedNeXt, a Transformer-inspired convolutional architecture designed for medical image segmentation in data-scarce settings. Unlike Transformer-based models, which have struggled to match the performance of convolutional networks on medical data due to the lack of large-scale annotated datasets, MedNeXt leverages the strong inductive biases of ConvNets while incorporating Transformer-like innovations.
At the core of MedNeXt is a fully ConvNeXt 3D Encoder-Decoder Network, which builds on the ConvNeXt architecture. To preserve semantic richness across scales, the model uses Residual ConvNeXt up and downsampling blocks.
The key innovation in MedNeXt is a novel technique to iteratively increase kernel sizes by upsampling small kernel networks. This helps prevent performance saturation on limited medical data, as larger kernels can capture more contextual information. Additionally, the model employs compound scaling at multiple levels (depth, width, kernel size) to further boost performance.
The researchers evaluate MedNeXt on four medical image segmentation tasks across CT and MRI modalities, demonstrating state-of-the-art results. These tasks cover a range of dataset sizes, showcasing the model's ability to perform well in data-scarce settings.
The authors make their code publicly available at https://github.com/MIC-DKFZ/MedNeXt, allowing others to build upon their work.
Critical Analysis
The paper presents a well-designed and innovative approach to addressing the challenges of medical image segmentation in the face of limited data. By leveraging the strengths of convolutional networks and incorporating Transformer-inspired elements, the researchers have created a highly effective and scalable architecture in MedNeXt.
One potential limitation mentioned in the paper is the reliance on hand-crafted upsampling techniques, which could be less flexible than learnable upsampling methods used in some other Transformer-based models for medical image segmentation. Additionally, the paper does not explore the potential trade-offs between model complexity and performance, which could be an area for further investigation.
While the results are impressive, it would be valuable to see how MedNeXt compares to other prominent architectures, such as D-TrattUNet, MaxViT-UNet, or even the original ConvNeXt model, in terms of performance, computational efficiency, and ease of training.
Overall, MedNeXt represents a significant contribution to the field of medical image segmentation, particularly in data-scarce settings. The innovations introduced in this paper could inspire further research and development of robust and scalable deep learning architectures for healthcare applications.
Conclusion
The paper introduces MedNeXt, a modernized and scalable convolutional architecture inspired by Transformers, designed to address the challenges of medical image segmentation in data-scarce settings. By incorporating a 3D Encoder-Decoder Network, Residual ConvNeXt blocks, and a novel technique to iteratively increase kernel sizes, MedNeXt achieves state-of-the-art performance on a variety of medical imaging tasks.
The innovations presented in MedNeXt could have significant implications for the field of medical image analysis, enabling more effective and robust segmentation models even when large, annotated datasets are not available. This work represents an important step towards developing deep learning architectures that can truly benefit healthcare and improve patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
LiteNeXt: A Novel Lightweight ConvMixer-based Model with Self-embedding Representation Parallel for Medical Image Segmentation
Ngoc-Du Tran, Thi-Thao Tran, Quang-Huy Nguyen, Manh-Hung Vu, Van-Truong Pham
0
0
The emergence of deep learning techniques has advanced the image segmentation task, especially for medical images. Many neural network models have been introduced in the last decade bringing the automated segmentation accuracy close to manual segmentation. However, cutting-edge models like Transformer-based architectures rely on large scale annotated training data, and are generally designed with densely consecutive layers in the encoder, decoder, and skip connections resulting in large number of parameters. Additionally, for better performance, they often be pretrained on a larger data, thus requiring large memory size and increasing resource expenses. In this study, we propose a new lightweight but efficient model, namely LiteNeXt, based on convolutions and mixing modules with simplified decoder, for medical image segmentation. The model is trained from scratch with small amount of parameters (0.71M) and Giga Floating Point Operations Per Second (0.42). To handle boundary fuzzy as well as occlusion or clutter in objects especially in medical image regions, we propose the Marginal Weight Loss that can help effectively determine the marginal boundary between object and background. Furthermore, we propose the Self-embedding Representation Parallel technique, that can help augment the data in a self-learning manner. Experiments on public datasets including Data Science Bowls, GlaS, ISIC2018, PH2, and Sunnybrook data show promising results compared to other state-of-the-art CNN-based and Transformer-based architectures. Our code will be published at: https://github.com/tranngocduvnvp/LiteNeXt.
5/28/2024
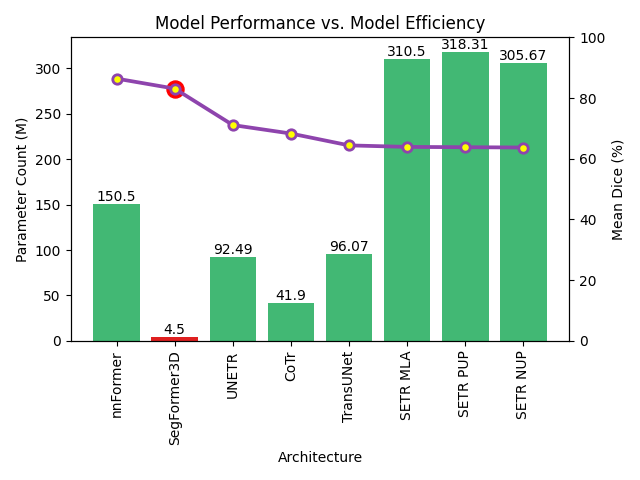
SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation
Shehan Perera, Pouyan Navard, Alper Yilmaz
0
0
The adoption of Vision Transformers (ViTs) based architectures represents a significant advancement in 3D Medical Image (MI) segmentation, surpassing traditional Convolutional Neural Network (CNN) models by enhancing global contextual understanding. While this paradigm shift has significantly enhanced 3D segmentation performance, state-of-the-art architectures require extremely large and complex architectures with large scale computing resources for training and deployment. Furthermore, in the context of limited datasets, often encountered in medical imaging, larger models can present hurdles in both model generalization and convergence. In response to these challenges and to demonstrate that lightweight models are a valuable area of research in 3D medical imaging, we present SegFormer3D, a hierarchical Transformer that calculates attention across multiscale volumetric features. Additionally, SegFormer3D avoids complex decoders and uses an all-MLP decoder to aggregate local and global attention features to produce highly accurate segmentation masks. The proposed memory efficient Transformer preserves the performance characteristics of a significantly larger model in a compact design. SegFormer3D democratizes deep learning for 3D medical image segmentation by offering a model with 33x less parameters and a 13x reduction in GFLOPS compared to the current state-of-the-art (SOTA). We benchmark SegFormer3D against the current SOTA models on three widely used datasets Synapse, BRaTs, and ACDC, achieving competitive results. Code: https://github.com/OSUPCVLab/SegFormer3D.git
4/17/2024
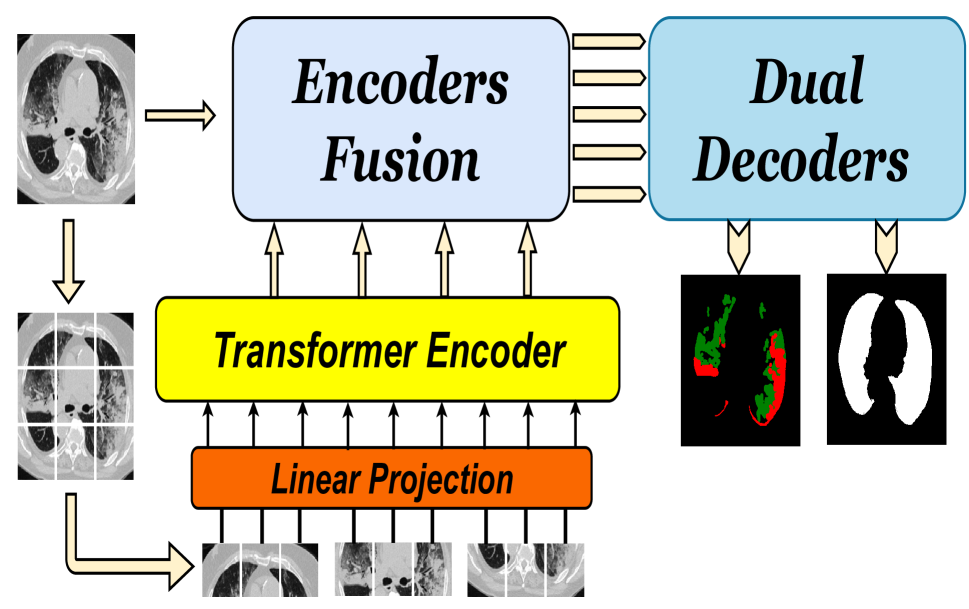
D-TrAttUnet: Toward Hybrid CNN-Transformer Architecture for Generic and Subtle Segmentation in Medical Images
Fares Bougourzi, Fadi Dornaika, Cosimo Distante, Abdelmalik Taleb-Ahmed
0
0
Over the past two decades, machine analysis of medical imaging has advanced rapidly, opening up significant potential for several important medical applications. As complicated diseases increase and the number of cases rises, the role of machine-based imaging analysis has become indispensable. It serves as both a tool and an assistant to medical experts, providing valuable insights and guidance. A particularly challenging task in this area is lesion segmentation, a task that is challenging even for experienced radiologists. The complexity of this task highlights the urgent need for robust machine learning approaches to support medical staff. In response, we present our novel solution: the D-TrAttUnet architecture. This framework is based on the observation that different diseases often target specific organs. Our architecture includes an encoder-decoder structure with a composite Transformer-CNN encoder and dual decoders. The encoder includes two paths: the Transformer path and the Encoders Fusion Module path. The Dual-Decoder configuration uses two identical decoders, each with attention gates. This allows the model to simultaneously segment lesions and organs and integrate their segmentation losses. To validate our approach, we performed evaluations on the Covid-19 and Bone Metastasis segmentation tasks. We also investigated the adaptability of the model by testing it without the second decoder in the segmentation of glands and nuclei. The results confirmed the superiority of our approach, especially in Covid-19 infections and the segmentation of bone metastases. In addition, the hybrid encoder showed exceptional performance in the segmentation of glands and nuclei, solidifying its role in modern medical image analysis.
5/8/2024
👀
Are Vision xLSTM Embedded UNet More Reliable in Medical 3D Image Segmentation?
Pallabi Dutta, Soham Bose, Swalpa Kumar Roy, Sushmita Mitra
0
0
The advancement of developing efficient medical image segmentation has evolved from initial dependence on Convolutional Neural Networks (CNNs) to the present investigation of hybrid models that combine CNNs with Vision Transformers. Furthermore, there is an increasing focus on creating architectures that are both high-performing in medical image segmentation tasks and computationally efficient to be deployed on systems with limited resources. Although transformers have several advantages like capturing global dependencies in the input data, they face challenges such as high computational and memory complexity. This paper investigates the integration of CNNs and Vision Extended Long Short-Term Memory (Vision-xLSTM) models by introducing a novel approach called UVixLSTM. The Vision-xLSTM blocks captures temporal and global relationships within the patches extracted from the CNN feature maps. The convolutional feature reconstruction path upsamples the output volume from the Vision-xLSTM blocks to produce the segmentation output. Our primary objective is to propose that Vision-xLSTM forms a reliable backbone for medical image segmentation tasks, offering excellent segmentation performance and reduced computational complexity. UVixLSTM exhibits superior performance compared to state-of-the-art networks on the publicly-available Synapse dataset. Code is available at: https://github.com/duttapallabi2907/UVixLSTM
6/26/2024