MedTrinity-25M: A Large-scale Multimodal Dataset with Multigranular Annotations for Medicine

0

Sign in to get full access
Overview
- MedTrinity-25M is a large-scale, multimodal dataset for medical applications
- It includes 25 million annotated samples across textual, visual, and tabular modalities
- The annotations cover a range of granularities, from low-level to high-level concepts
Plain English Explanation
MedTrinity-25M is a massive dataset that combines different types of medical data - text, images, and structured information. It has over 25 million annotated samples, meaning each piece of data has been labeled or described in detail. These annotations cover a wide variety of medical concepts, from basic terms to more complex ideas.
This dataset could be extremely useful for training AI models to understand and work with medical information. By having access to such a large and diverse collection of annotated data, researchers and developers can build systems that can better comprehend and reason about medical knowledge. This could lead to advancements in areas like medical diagnosis, drug discovery, and patient care.
Technical Explanation
The MedTrinity-25M dataset contains a wide variety of medical data, including textual information like clinical notes, visual data like medical images, and structured tabular data. This multimodal approach allows the dataset to capture the richness and complexity of the medical domain.
The annotations in MedTrinity-25M cover different levels of granularity, from low-level concepts like anatomical structures to high-level ideas like disease diagnoses. This multigranular annotation scheme enables the development of AI models that can operate at varying levels of abstraction, depending on the task at hand.
The sheer scale of the dataset, with 25 million annotated samples, makes it a valuable resource for training powerful machine learning models. By leveraging the breadth and depth of the data, researchers can develop more robust and capable systems for medical applications.
Critical Analysis
The MedTrinity-25M dataset represents a significant advance in the availability of large-scale, annotated medical data. However, the paper does not discuss potential limitations or biases in the dataset, such as the representativeness of the data sources or the reliability of the annotations.
Additionally, the paper does not provide details on the specific techniques used to collect, process, and curate the dataset. Without this information, it is difficult to assess the quality and consistency of the data.
Further research could explore the performance and generalization of AI models trained on MedTrinity-25M, and compare their capabilities to those of models trained on other medical datasets. This would help establish the relative strengths and weaknesses of the MedTrinity-25M dataset.
Conclusion
The MedTrinity-25M dataset is a substantial contribution to the field of medical AI, providing researchers and developers with a large, multimodal, and multigranularly annotated resource for training advanced models. While the dataset has great potential, more information and analysis are needed to fully understand its capabilities and limitations. As the field of medical AI continues to evolve, datasets like MedTrinity-25M will play a crucial role in driving innovation and improving healthcare outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MedTrinity-25M: A Large-scale Multimodal Dataset with Multigranular Annotations for Medicine
Yunfei Xie, Ce Zhou, Lang Gao, Juncheng Wu, Xianhang Li, Hong-Yu Zhou, Sheng Liu, Lei Xing, James Zou, Cihang Xie, Yuyin Zhou
This paper introduces MedTrinity-25M, a comprehensive, large-scale multimodal dataset for medicine, covering over 25 million images across 10 modalities, with multigranular annotations for more than 65 diseases. These enriched annotations encompass both global textual information, such as disease/lesion type, modality, region-specific descriptions, and inter-regional relationships, as well as detailed local annotations for regions of interest (ROIs), including bounding boxes, segmentation masks. Unlike existing approach which is limited by the availability of image-text pairs, we have developed the first automated pipeline that scales up multimodal data by generating multigranular visual and texual annotations (in the form of image-ROI-description triplets) without the need for any paired text descriptions. Specifically, data from over 90 different sources have been collected, preprocessed, and grounded using domain-specific expert models to identify ROIs related to abnormal regions. We then build a comprehensive knowledge base and prompt multimodal large language models to perform retrieval-augmented generation with the identified ROIs as guidance, resulting in multigranular texual descriptions. Compared to existing datasets, MedTrinity-25M provides the most enriched annotations, supporting a comprehensive range of multimodal tasks such as captioning and report generation, as well as vision-centric tasks like classification and segmentation. Pretraining on MedTrinity-25M, our model achieves state-of-the-art performance on VQA-RAD and PathVQA, surpassing both multimodal large language models and other representative SoTA approaches. This dataset can also be utilized to support large-scale pre-training of multimodal medical AI models, contributing to the development of future foundation models in the medical domain.
Read more8/7/2024

0
MultiMed: Massively Multimodal and Multitask Medical Understanding
Shentong Mo, Paul Pu Liang
Biomedical data is inherently multimodal, consisting of electronic health records, medical imaging, digital pathology, genome sequencing, wearable sensors, and more. The application of artificial intelligence tools to these multifaceted sensing technologies has the potential to revolutionize the prognosis, diagnosis, and management of human health and disease. However, current approaches to biomedical AI typically only train and evaluate with one or a small set of medical modalities and tasks. This limitation hampers the development of comprehensive tools that can leverage the rich interconnected information across many heterogeneous biomedical sensors. To address this challenge, we present MultiMed, a benchmark designed to evaluate and enable large-scale learning across a wide spectrum of medical modalities and tasks. MultiMed consists of 2.56 million samples across ten medical modalities such as medical reports, pathology, genomics, and protein data, and is structured into eleven challenging tasks, including disease prognosis, protein structure prediction, and medical question answering. Using MultiMed, we conduct comprehensive experiments benchmarking state-of-the-art unimodal, multimodal, and multitask models. Our analysis highlights the advantages of training large-scale medical models across many related modalities and tasks. Moreover, MultiMed enables studies of generalization across related medical concepts, robustness to real-world noisy data and distribution shifts, and novel modality combinations to improve prediction performance. MultiMed will be publicly available and regularly updated and welcomes inputs from the community.
Read more8/26/2024
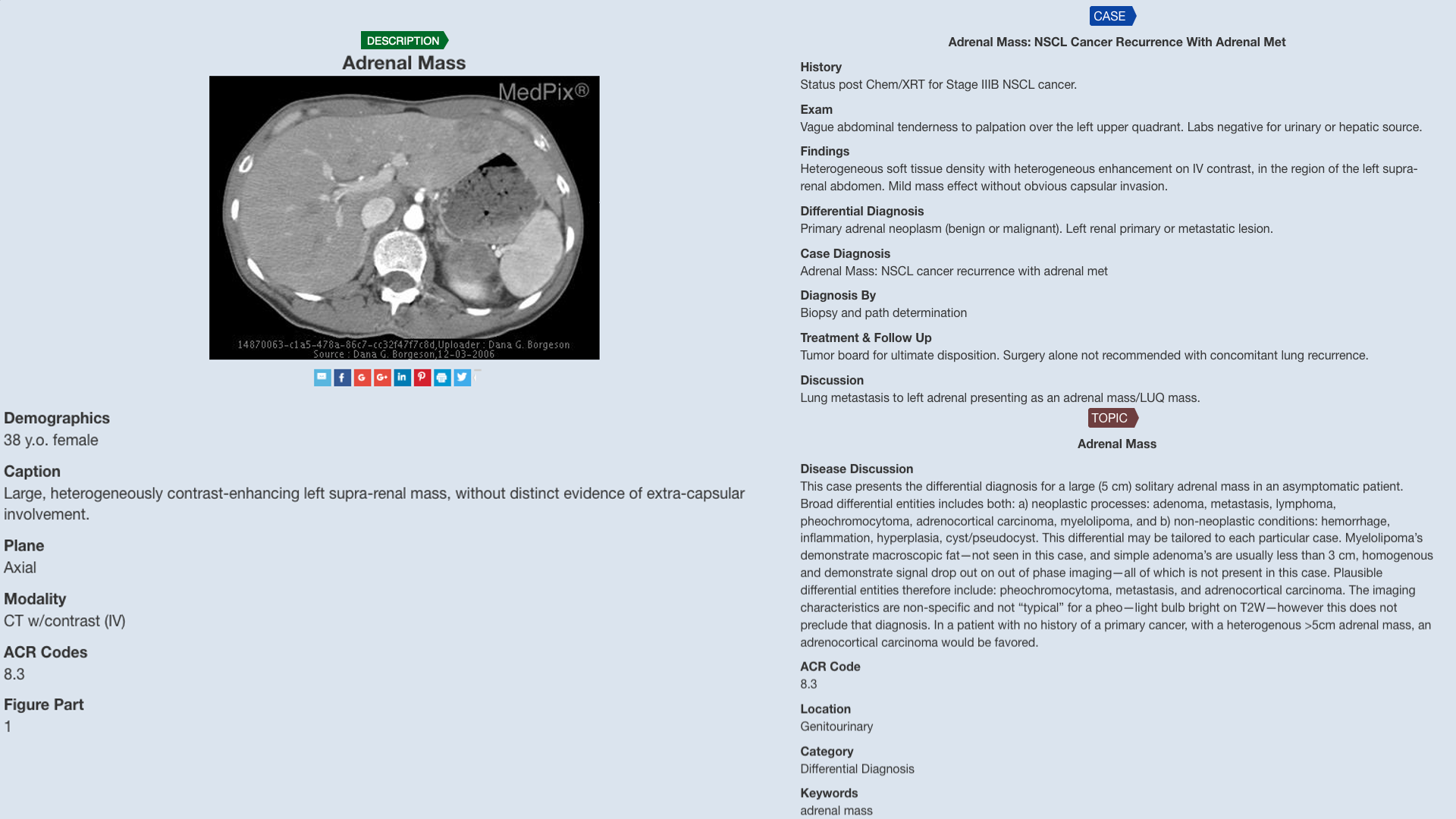
0
MedPix 2.0: A Comprehensive Multimodal Biomedical Dataset for Advanced AI Applications
Irene Siragusa, Salvatore Contino, Massimo La Ciura, Rosario Alicata, Roberto Pirrone
The increasing interest in developing Artificial Intelligence applications in the medical domain, suffers from the lack of high-quality dataset, mainly due to privacy-related issues. Moreover, the recent rising of Multimodal Large Language Models (MLLM) leads to a need for multimodal medical datasets, where clinical reports and findings are attached to the corresponding CT or MR scans. This paper illustrates the entire workflow for building the data set MedPix 2.0. Starting from the well-known multimodal dataset MedPixtextsuperscript{textregistered}, mainly used by physicians, nurses and healthcare students for Continuing Medical Education purposes, a semi-automatic pipeline was developed to extract visual and textual data followed by a manual curing procedure where noisy samples were removed, thus creating a MongoDB database. Along with the dataset, we developed a GUI aimed at navigating efficiently the MongoDB instance, and obtaining the raw data that can be easily used for training and/or fine-tuning MLLMs. To enforce this point, we also propose a CLIP-based model trained on MedPix 2.0 for scan classification tasks.
Read more7/4/2024

0
A Refer-and-Ground Multimodal Large Language Model for Biomedicine
Xiaoshuang Huang, Haifeng Huang, Lingdong Shen, Yehui Yang, Fangxin Shang, Junwei Liu, Jia Liu
With the rapid development of multimodal large language models (MLLMs), especially their capabilities in visual chat through refer and ground functionalities, their significance is increasingly recognized. However, the biomedical field currently exhibits a substantial gap in this area, primarily due to the absence of a dedicated refer and ground dataset for biomedical images. To address this challenge, we devised the Med-GRIT-270k dataset. It comprises 270k question-and-answer pairs and spans eight distinct medical imaging modalities. Most importantly, it is the first dedicated to the biomedical domain and integrating refer and ground conversations. The key idea is to sample large-scale biomedical image-mask pairs from medical segmentation datasets and generate instruction datasets from text using chatGPT. Additionally, we introduce a Refer-and-Ground Multimodal Large Language Model for Biomedicine (BiRD) by using this dataset and multi-task instruction learning. Extensive experiments have corroborated the efficacy of the Med-GRIT-270k dataset and the multi-modal, fine-grained interactive capabilities of the BiRD model. This holds significant reference value for the exploration and development of intelligent biomedical assistants.
Read more7/1/2024