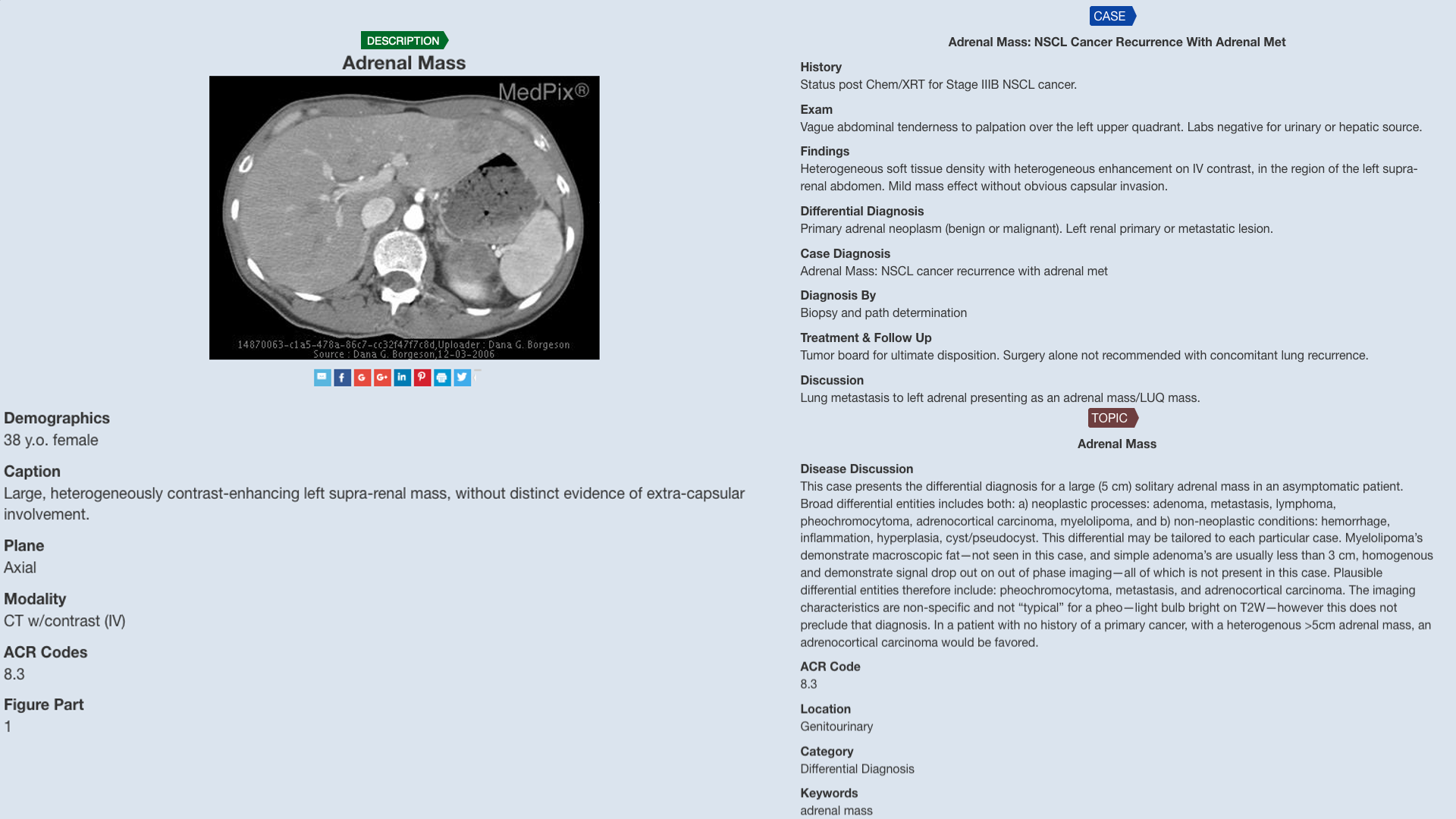
MedPix 2.0: A Comprehensive Multimodal Biomedical Dataset for Advanced AI Applications

0
Sign in to get full access
Overview
- Introduces a new biomedical dataset called MedPix 2.0 that contains a diverse collection of multimodal medical data, including images, reports, and patient metadata
- Designed to enable the development of advanced AI models for a variety of medical applications, such as diagnostic support systems, multimodal medical image and report integration, and high-resolution vision-language models for biomedicine
- Aims to advance the state-of-the-art in medical AI by providing a large-scale, high-quality dataset that can be used to train and evaluate cutting-edge models
Plain English Explanation
The researchers have created a new dataset called MedPix 2.0 that contains a wide variety of medical data, including images, reports, and patient information. This dataset is designed to help develop advanced artificial intelligence (AI) models that can be used for various medical applications, such as helping doctors diagnose patients, integrating medical images and reports, and creating high-resolution AI models that can understand both medical images and text.
The goal is to push the boundaries of what's possible with medical AI by providing a large and diverse dataset that researchers and developers can use to train and test their latest models. This could lead to significant improvements in the accuracy and capabilities of AI-powered medical tools, ultimately benefiting patients and healthcare providers.
Technical Explanation
The MedPix 2.0 dataset is a comprehensive multimodal biomedical dataset that contains a wide range of medical data, including medical images, clinical reports, and patient metadata. The dataset is designed to enable the development of advanced AI models for a variety of medical applications, such as diagnostic support systems, multimodal medical image and report integration, and high-resolution vision-language models for biomedicine.
The dataset was constructed by aggregating data from various sources, including clinical repositories and open-access medical databases. The data was then carefully curated and annotated by medical experts to ensure high quality and reliability. The resulting dataset contains a diverse collection of medical data, including images from a wide range of modalities (e.g., X-ray, CT, MRI), corresponding clinical reports, and patient metadata (e.g., demographics, diagnoses, treatments).
Critical Analysis
The MedPix 2.0 dataset represents a significant advancement in the field of medical AI, as it provides a large-scale, high-quality dataset that can be used to train and evaluate cutting-edge models. However, the paper acknowledges several caveats and limitations of the dataset. For example, the dataset is primarily focused on certain geographic regions and may not be representative of the global patient population. Additionally, the data may be subject to biases and inconsistencies due to the heterogeneous nature of the sources.
Further research is needed to address these limitations and explore the full potential of the MedPix 2.0 dataset. Researchers may need to investigate techniques for addressing data biases, improving data curation processes, and expanding the geographic and demographic coverage of the dataset. Additionally, more work is needed to explore the practical applications of the dataset, such as its impact on clinical decision-making and patient outcomes.
Conclusion
The MedPix 2.0 dataset represents a significant step forward in the field of medical AI, providing a comprehensive multimodal dataset that can be used to train and evaluate advanced models for a variety of medical applications. By making this dataset available to the research community, the authors hope to spur the development of innovative AI-powered tools that can improve patient care and advance the state of the art in medical diagnostics and decision support. While the dataset has some limitations, it provides a valuable resource for researchers and developers working to create the next generation of medical AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MedPix 2.0: A Comprehensive Multimodal Biomedical Dataset for Advanced AI Applications
Irene Siragusa, Salvatore Contino, Massimo La Ciura, Rosario Alicata, Roberto Pirrone
The increasing interest in developing Artificial Intelligence applications in the medical domain, suffers from the lack of high-quality dataset, mainly due to privacy-related issues. Moreover, the recent rising of Multimodal Large Language Models (MLLM) leads to a need for multimodal medical datasets, where clinical reports and findings are attached to the corresponding CT or MR scans. This paper illustrates the entire workflow for building the data set MedPix 2.0. Starting from the well-known multimodal dataset MedPixtextsuperscript{textregistered}, mainly used by physicians, nurses and healthcare students for Continuing Medical Education purposes, a semi-automatic pipeline was developed to extract visual and textual data followed by a manual curing procedure where noisy samples were removed, thus creating a MongoDB database. Along with the dataset, we developed a GUI aimed at navigating efficiently the MongoDB instance, and obtaining the raw data that can be easily used for training and/or fine-tuning MLLMs. To enforce this point, we also propose a CLIP-based model trained on MedPix 2.0 for scan classification tasks.
Read more7/4/2024

0
MultiMed: Massively Multimodal and Multitask Medical Understanding
Shentong Mo, Paul Pu Liang
Biomedical data is inherently multimodal, consisting of electronic health records, medical imaging, digital pathology, genome sequencing, wearable sensors, and more. The application of artificial intelligence tools to these multifaceted sensing technologies has the potential to revolutionize the prognosis, diagnosis, and management of human health and disease. However, current approaches to biomedical AI typically only train and evaluate with one or a small set of medical modalities and tasks. This limitation hampers the development of comprehensive tools that can leverage the rich interconnected information across many heterogeneous biomedical sensors. To address this challenge, we present MultiMed, a benchmark designed to evaluate and enable large-scale learning across a wide spectrum of medical modalities and tasks. MultiMed consists of 2.56 million samples across ten medical modalities such as medical reports, pathology, genomics, and protein data, and is structured into eleven challenging tasks, including disease prognosis, protein structure prediction, and medical question answering. Using MultiMed, we conduct comprehensive experiments benchmarking state-of-the-art unimodal, multimodal, and multitask models. Our analysis highlights the advantages of training large-scale medical models across many related modalities and tasks. Moreover, MultiMed enables studies of generalization across related medical concepts, robustness to real-world noisy data and distribution shifts, and novel modality combinations to improve prediction performance. MultiMed will be publicly available and regularly updated and welcomes inputs from the community.
Read more8/26/2024
0
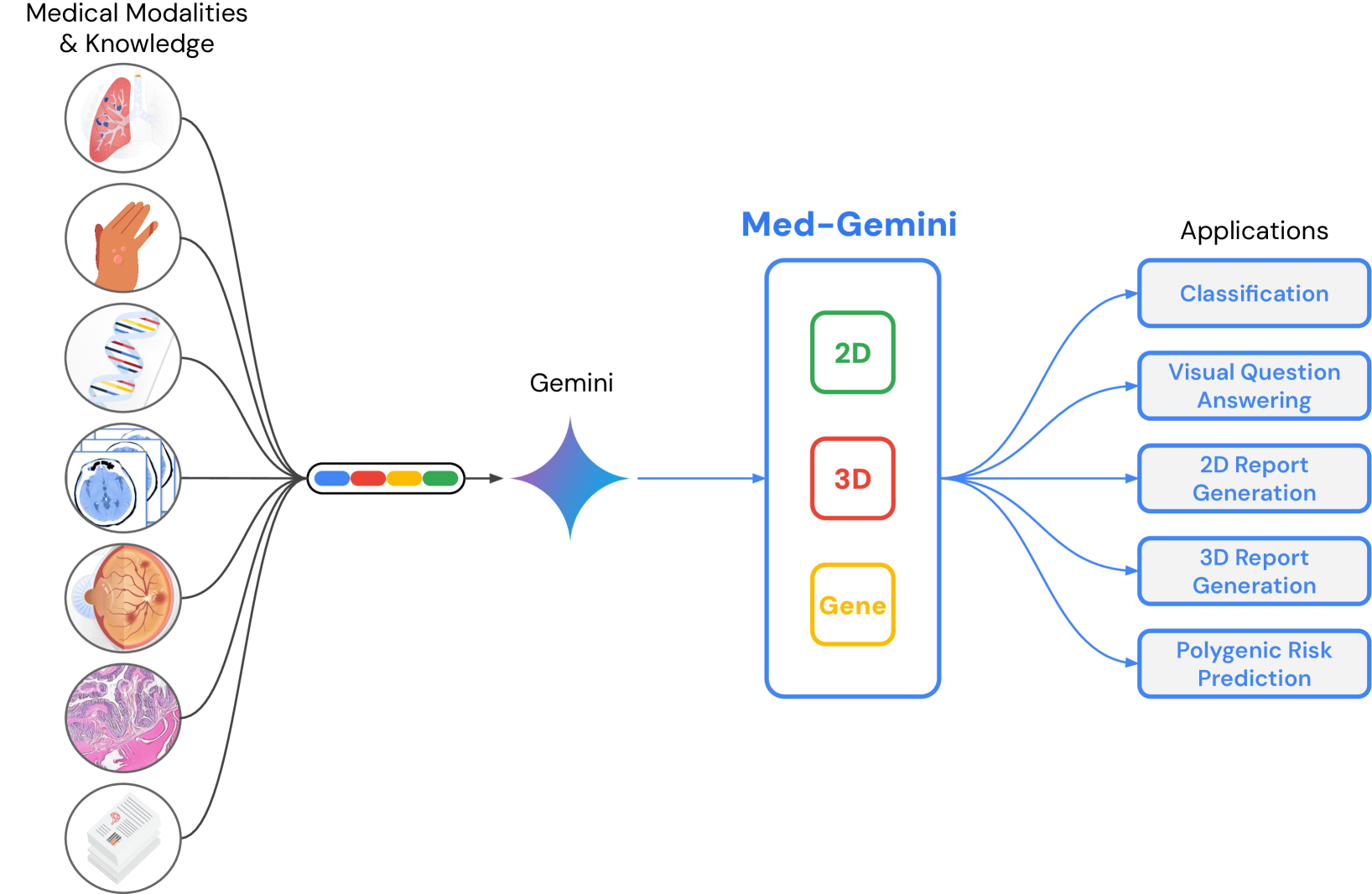
Advancing Multimodal Medical Capabilities of Gemini
Lin Yang, Shawn Xu, Andrew Sellergren, Timo Kohlberger, Yuchen Zhou, Ira Ktena, Atilla Kiraly, Faruk Ahmed, Farhad Hormozdiari, Tiam Jaroensri, Eric Wang, Ellery Wulczyn, Fayaz Jamil, Theo Guidroz, Chuck Lau, Siyuan Qiao, Yun Liu, Akshay Goel, Kendall Park, Arnav Agharwal, Nick George, Yang Wang, Ryutaro Tanno, David G. T. Barrett, Wei-Hung Weng, S. Sara Mahdavi, Khaled Saab, Tao Tu, Sreenivasa Raju Kalidindi, Mozziyar Etemadi, Jorge Cuadros, Gregory Sorensen, Yossi Matias, Katherine Chou, Greg Corrado, Joelle Barral, Shravya Shetty, David Fleet, S. M. Ali Eslami, Daniel Tse, Shruthi Prabhakara, Cory McLean, Dave Steiner, Rory Pilgrim, Christopher Kelly, Shekoofeh Azizi, Daniel Golden
Many clinical tasks require an understanding of specialized data, such as medical images and genomics, which is not typically found in general-purpose large multimodal models. Building upon Gemini's multimodal models, we develop several models within the new Med-Gemini family that inherit core capabilities of Gemini and are optimized for medical use via fine-tuning with 2D and 3D radiology, histopathology, ophthalmology, dermatology and genomic data. Med-Gemini-2D sets a new standard for AI-based chest X-ray (CXR) report generation based on expert evaluation, exceeding previous best results across two separate datasets by an absolute margin of 1% and 12%, where 57% and 96% of AI reports on normal cases, and 43% and 65% on abnormal cases, are evaluated as equivalent or better than the original radiologists' reports. We demonstrate the first ever large multimodal model-based report generation for 3D computed tomography (CT) volumes using Med-Gemini-3D, with 53% of AI reports considered clinically acceptable, although additional research is needed to meet expert radiologist reporting quality. Beyond report generation, Med-Gemini-2D surpasses the previous best performance in CXR visual question answering (VQA) and performs well in CXR classification and radiology VQA, exceeding SoTA or baselines on 17 of 20 tasks. In histopathology, ophthalmology, and dermatology image classification, Med-Gemini-2D surpasses baselines across 18 out of 20 tasks and approaches task-specific model performance. Beyond imaging, Med-Gemini-Polygenic outperforms the standard linear polygenic risk score-based approach for disease risk prediction and generalizes to genetically correlated diseases for which it has never been trained. Although further development and evaluation are necessary in the safety-critical medical domain, our results highlight the potential of Med-Gemini across a wide range of medical tasks.
Read more5/7/2024

0
MedTrinity-25M: A Large-scale Multimodal Dataset with Multigranular Annotations for Medicine
Yunfei Xie, Ce Zhou, Lang Gao, Juncheng Wu, Xianhang Li, Hong-Yu Zhou, Sheng Liu, Lei Xing, James Zou, Cihang Xie, Yuyin Zhou
This paper introduces MedTrinity-25M, a comprehensive, large-scale multimodal dataset for medicine, covering over 25 million images across 10 modalities, with multigranular annotations for more than 65 diseases. These enriched annotations encompass both global textual information, such as disease/lesion type, modality, region-specific descriptions, and inter-regional relationships, as well as detailed local annotations for regions of interest (ROIs), including bounding boxes, segmentation masks. Unlike existing approach which is limited by the availability of image-text pairs, we have developed the first automated pipeline that scales up multimodal data by generating multigranular visual and texual annotations (in the form of image-ROI-description triplets) without the need for any paired text descriptions. Specifically, data from over 90 different sources have been collected, preprocessed, and grounded using domain-specific expert models to identify ROIs related to abnormal regions. We then build a comprehensive knowledge base and prompt multimodal large language models to perform retrieval-augmented generation with the identified ROIs as guidance, resulting in multigranular texual descriptions. Compared to existing datasets, MedTrinity-25M provides the most enriched annotations, supporting a comprehensive range of multimodal tasks such as captioning and report generation, as well as vision-centric tasks like classification and segmentation. Pretraining on MedTrinity-25M, our model achieves state-of-the-art performance on VQA-RAD and PathVQA, surpassing both multimodal large language models and other representative SoTA approaches. This dataset can also be utilized to support large-scale pre-training of multimodal medical AI models, contributing to the development of future foundation models in the medical domain.
Read more8/7/2024