MedUnA: Language guided Unsupervised Adaptation of Vision-Language Models for Medical Image Classification

0

Sign in to get full access
Overview
- A new approach called MedUnA for unsupervised adaptation of vision-language models for medical image classification
- Uses language guidance to adapt the model to medical tasks without requiring labeled medical data
- Outperforms existing techniques on several medical image classification benchmarks
Plain English Explanation
MedUnA: Language guided Unsupervised Adaptation of Vision-Language Models for Medical Image Classification is a new method that helps vision-language AI models perform better on medical image classification tasks.
The key idea is to use language information to guide the model's adaptation, rather than requiring labeled medical images. This is important because getting large labeled medical datasets can be very difficult and expensive. Instead, MedUnA can take a general vision-language model trained on more widely available data, and adapt it to medical tasks in an unsupervised way using just the text descriptions associated with the medical images.
This allows the model to leverage the powerful visual and language understanding capabilities it has learned from broader datasets, and fine-tune them for the medical domain without needing large amounts of labeled medical data. The authors show this approach outperforms other techniques on several medical image classification benchmarks.
Technical Explanation
The MedUnA approach works by first pre-training a vision-language model on large general datasets. It then adapts this model to medical tasks through an unsupervised process that aligns the visual and textual representations using the language descriptions associated with medical images.
Specifically, the model is trained to predict the language description given the image, and vice versa. This encourages the visual and textual representations to become more closely aligned for medical content, without requiring any labeled medical image data.
The authors evaluate MedUnA on several medical image classification datasets and show it outperforms other state-of-the-art techniques that either require labeled medical data or use less effective approaches to adaptation.
Critical Analysis
The paper provides a thorough empirical evaluation of MedUnA, demonstrating its effectiveness across multiple medical image classification tasks. However, the authors acknowledge that MedUnA's performance is still not on par with models fine-tuned on large labeled medical datasets.
Additionally, the paper does not address potential concerns around the generalizability of MedUnA to other medical imaging modalities or tasks beyond classification. Further research would be needed to assess the broader applicability of this approach.
It would also be important to investigate any biases or limitations introduced by the language data used to guide the adaptation process, as this could impact the model's fairness and robustness when deployed in real-world medical settings.
Conclusion
MedUnA presents a promising approach for adapting general vision-language models to medical image classification tasks in an unsupervised manner, leveraging language guidance instead of requiring large labeled medical datasets.
This technique has the potential to significantly reduce the burden of data collection and annotation for medical AI applications, allowing the field to benefit from the rapid advances in vision-language modeling. As the authors note, further research is needed to fully realize MedUnA's capabilities and address potential limitations.
Overall, this work demonstrates the value of cross-pollination between general and domain-specific AI models, and highlights the importance of continued innovation in unsupervised and semi-supervised learning methods for medical imaging applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MedUnA: Language guided Unsupervised Adaptation of Vision-Language Models for Medical Image Classification
Umaima Rahman, Raza Imam, Dwarikanath Mahapatra, Boulbaba Ben Amor
In medical image classification, supervised learning is challenging due to the lack of labeled medical images. Contrary to the traditional textit{modus operandi} of pre-training followed by fine-tuning, this work leverages the visual-textual alignment within Vision-Language models (texttt{VLMs}) to facilitate the unsupervised learning. Specifically, we propose underline{Med}ical underline{Un}supervised underline{A}daptation (texttt{MedUnA}), constituting two-stage training: Adapter Pre-training, and Unsupervised Learning. In the first stage, we use descriptions generated by a Large Language Model (texttt{LLM}) corresponding to class labels, which are passed through the text encoder texttt{BioBERT}. The resulting text embeddings are then aligned with the class labels by training a lightweight texttt{adapter}. We choose texttt{texttt{LLMs}} because of their capability to generate detailed, contextually relevant descriptions to obtain enhanced text embeddings. In the second stage, the trained texttt{adapter} is integrated with the visual encoder of texttt{MedCLIP}. This stage employs a contrastive entropy-based loss and prompt tuning to align visual embeddings. We incorporate self-entropy minimization into the overall training objective to ensure more confident embeddings, which are crucial for effective unsupervised learning and alignment. We evaluate the performance of texttt{MedUnA} on three different kinds of data modalities - chest X-rays, eye fundus and skin lesion images. The results demonstrate significant accuracy gain on average compared to the baselines across different datasets, highlighting the efficacy of our approach.
Read more9/5/2024
0
Medical Vision-Language Pre-Training for Brain Abnormalities
Masoud Monajatipoor, Zi-Yi Dou, Aichi Chien, Nanyun Peng, Kai-Wei Chang
Vision-language models have become increasingly powerful for tasks that require an understanding of both visual and linguistic elements, bridging the gap between these modalities. In the context of multimodal clinical AI, there is a growing need for models that possess domain-specific knowledge, as existing models often lack the expertise required for medical applications. In this paper, we take brain abnormalities as an example to demonstrate how to automatically collect medical image-text aligned data for pretraining from public resources such as PubMed. In particular, we present a pipeline that streamlines the pre-training process by initially collecting a large brain image-text dataset from case reports and published journals and subsequently constructing a high-performance vision-language model tailored to specific medical tasks. We also investigate the unique challenge of mapping subfigures to subcaptions in the medical domain. We evaluated the resulting model with quantitative and qualitative intrinsic evaluations. The resulting dataset and our code can be found here https://github.com/masoud-monajati/MedVL_pretraining_pipeline
Read more4/30/2024

0
Few-shot Adaptation of Medical Vision-Language Models
Fereshteh Shakeri, Yunshi Huang, Julio Silva-Rodr'iguez, Houda Bahig, An Tang, Jose Dolz, Ismail Ben Ayed
Integrating image and text data through multi-modal learning has emerged as a new approach in medical imaging research, following its successful deployment in computer vision. While considerable efforts have been dedicated to establishing medical foundation models and their zero-shot transfer to downstream tasks, the popular few-shot setting remains relatively unexplored. Following on from the currently strong emergence of this setting in computer vision, we introduce the first structured benchmark for adapting medical vision-language models (VLMs) in a strict few-shot regime and investigate various adaptation strategies commonly used in the context of natural images. Furthermore, we evaluate a simple generalization of the linear-probe adaptation baseline, which seeks an optimal blending of the visual prototypes and text embeddings via learnable class-wise multipliers. Surprisingly, such a text-informed linear probe yields competitive performances in comparison to convoluted prompt-learning and adapter-based strategies, while running considerably faster and accommodating the black-box setting. Our extensive experiments span three different medical modalities and specialized foundation models, nine downstream tasks, and several state-of-the-art few-shot adaptation methods. We made our benchmark and code publicly available to trigger further developments in this emergent subject: url{https://github.com/FereshteShakeri/few-shot-MedVLMs}.
Read more9/9/2024
0
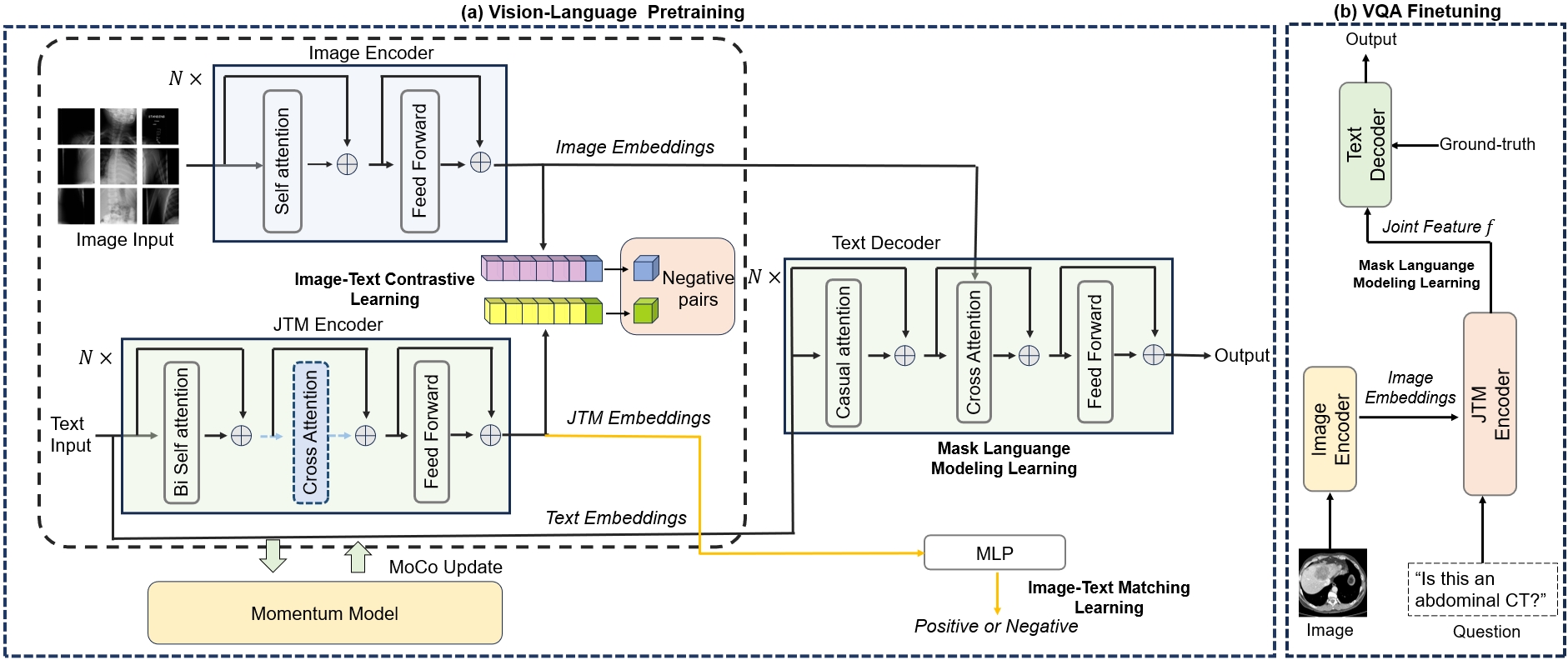
MISS: A Generative Pretraining and Finetuning Approach for Med-VQA
Jiawei Chen, Dingkang Yang, Yue Jiang, Yuxuan Lei, Lihua Zhang
Medical visual question answering (VQA) is a challenging multimodal task, where Vision-Language Pre-training (VLP) models can effectively improve the generalization performance. However, most methods in the medical field treat VQA as an answer classification task which is difficult to transfer to practical application scenarios. Additionally, due to the privacy of medical images and the expensive annotation process, large-scale medical image-text pairs datasets for pretraining are severely lacking. In this paper, we propose a large-scale MultI-task Self-Supervised learning based framework (MISS) for medical VQA tasks. Unlike existing methods, we treat medical VQA as a generative task. We unify the text encoder and multimodal encoder and align image-text features through multi-task learning. Furthermore, we propose a Transfer-and-Caption method that extends the feature space of single-modal image datasets using Large Language Models (LLMs), enabling those traditional medical vision field task data to be applied to VLP. Experiments show that our method achieves excellent results with fewer multimodal datasets and demonstrates the advantages of generative VQA models.
Read more6/21/2024