MISS: A Generative Pretraining and Finetuning Approach for Med-VQA

0
Sign in to get full access
Overview
- This paper introduces MISS, a novel approach for medical visual question answering (Med-VQA) that combines generative pretraining and fine-tuning.
- The model is designed to tackle the challenges of limited annotated data and domain-specific language in the medical field.
- MISS leverages large-scale pretraining on diverse data sources to learn powerful multimodal representations, which are then fine-tuned on the target Med-VQA task.
Plain English Explanation
The paper discusses a new technique called MISS for answering questions about medical images. Medical visual question answering is a complex task because there is often limited data available for training AI models, and the language used in the medical field can be very specialized.
To address these challenges, the MISS approach first pretrains the model on a large, diverse set of data from various sources. This allows the model to learn powerful representations that can capture the relationships between images and language. The pretrained model is then fine-tuned, or further trained, specifically on the medical visual question answering task. This fine-tuning step helps the model adapt to the unique characteristics of the medical domain.
The key idea behind MISS is to leverage the benefits of both broad pretraining and targeted fine-tuning to create an AI system that can excel at answering questions about medical images. By starting with a strong foundation from the pretraining phase and then fine-tuning on the specific task, the model can overcome the limitations of having a small amount of annotated medical data.
Technical Explanation
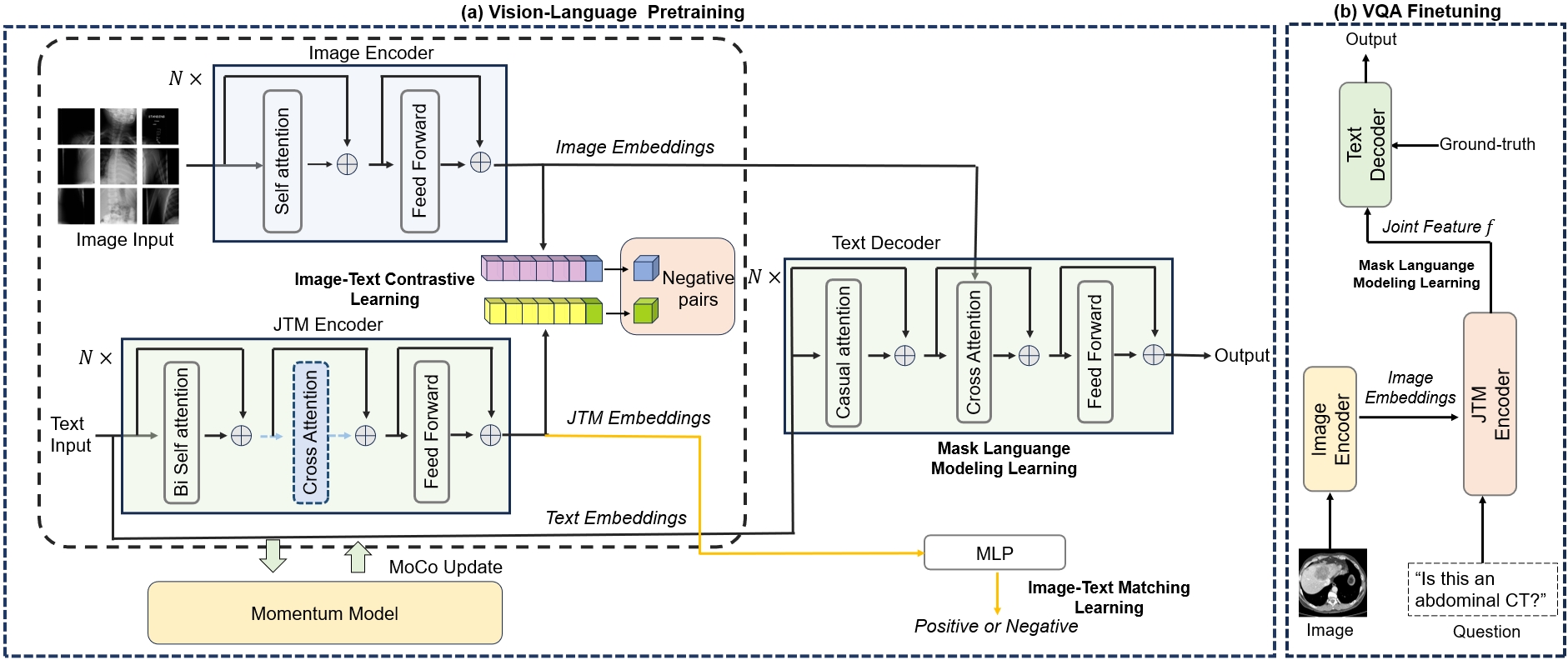
The MISS approach consists of two main components: generative pretraining and fine-tuning.
For the pretraining stage, the authors use a large, diverse dataset that includes images and associated text from various domains, not just the medical field. This allows the model to learn robust multimodal representations that can capture the relationships between visual and textual information. The pretraining objective is a generative task, where the model learns to generate the text conditioned on the image.
After pretraining, the model is fine-tuned on the target Med-VQA task. The authors fine-tune the model using a combination of classification and generation objectives, where the model learns to both classify the correct answer and generate the answer text.
The experiments demonstrate that the MISS approach outperforms previous state-of-the-art methods on several medical visual question answering benchmarks. The authors attribute this success to the powerful multimodal representations learned during pretraining, which are then effectively adapted to the medical domain through the fine-tuning process.
Critical Analysis
The MISS approach addresses an important challenge in the field of medical visual question answering, namely the limited availability of annotated data in the medical domain. By leveraging large-scale pretraining on diverse data sources, the model is able to overcome this data scarcity issue and achieve strong performance on the target task.
However, the paper does not provide a detailed analysis of the model's performance on different types of medical questions or images. It would be valuable to understand if the MISS approach is equally effective for different medical specialties or question types, or if there are any biases or limitations in its performance.
Additionally, the paper does not discuss potential ethical considerations or societal implications of deploying a medical visual question answering system. As these models are intended to be used in a healthcare context, it is important to carefully examine their robustness, fairness, and potential for misuse or unintended consequences.
Conclusion
The MISS approach represents a promising step forward in the field of medical visual question answering. By combining powerful generative pretraining with targeted fine-tuning, the model is able to effectively leverage diverse data sources and adapt to the unique characteristics of the medical domain.
The success of MISS highlights the potential of transfer learning and multimodal representations to address challenges in specialized domains with limited data. As the field of medical AI continues to evolve, techniques like MISS will play an important role in developing reliable and effective systems to support healthcare professionals and improve patient outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MISS: A Generative Pretraining and Finetuning Approach for Med-VQA
Jiawei Chen, Dingkang Yang, Yue Jiang, Yuxuan Lei, Lihua Zhang
Medical visual question answering (VQA) is a challenging multimodal task, where Vision-Language Pre-training (VLP) models can effectively improve the generalization performance. However, most methods in the medical field treat VQA as an answer classification task which is difficult to transfer to practical application scenarios. Additionally, due to the privacy of medical images and the expensive annotation process, large-scale medical image-text pairs datasets for pretraining are severely lacking. In this paper, we propose a large-scale MultI-task Self-Supervised learning based framework (MISS) for medical VQA tasks. Unlike existing methods, we treat medical VQA as a generative task. We unify the text encoder and multimodal encoder and align image-text features through multi-task learning. Furthermore, we propose a Transfer-and-Caption method that extends the feature space of single-modal image datasets using Large Language Models (LLMs), enabling those traditional medical vision field task data to be applied to VLP. Experiments show that our method achieves excellent results with fewer multimodal datasets and demonstrates the advantages of generative VQA models.
Read more6/21/2024
0
Design as Desired: Utilizing Visual Question Answering for Multimodal Pre-training
Tongkun Su, Jun Li, Xi Zhang, Haibo Jin, Hao Chen, Qiong Wang, Faqin Lv, Baoliang Zhao, Yin Hu
Multimodal pre-training demonstrates its potential in the medical domain, which learns medical visual representations from paired medical reports. However, many pre-training tasks require extra annotations from clinicians, and most of them fail to explicitly guide the model to learn the desired features of different pathologies. To the best of our knowledge, we are the first to utilize Visual Question Answering (VQA) for multimodal pre-training to guide the framework focusing on targeted pathological features. In this work, we leverage descriptions in medical reports to design multi-granular question-answer pairs associated with different diseases, which assist the framework in pre-training without requiring extra annotations from experts. We also propose a novel pre-training framework with a quasi-textual feature transformer, a module designed to transform visual features into a quasi-textual space closer to the textual domain via a contrastive learning strategy. This narrows the vision-language gap and facilitates modality alignment. Our framework is applied to four downstream tasks: report generation, classification, segmentation, and detection across five datasets. Extensive experiments demonstrate the superiority of our framework compared to other state-of-the-art methods. Our code will be released upon acceptance.
Read more4/9/2024
0
Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
Iryna Hartsock, Ghulam Rasool
Medical vision-language models (VLMs) combine computer vision (CV) and natural language processing (NLP) to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering (VQA). We provide background on NLP and CV, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and VQA. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
Read more4/16/2024
👀
0
Fusion of Domain-Adapted Vision and Language Models for Medical Visual Question Answering
Cuong Nhat Ha, Shima Asaadi, Sanjeev Kumar Karn, Oladimeji Farri, Tobias Heimann, Thomas Runkler
Vision-language models, while effective in general domains and showing strong performance in diverse multi-modal applications like visual question-answering (VQA), struggle to maintain the same level of effectiveness in more specialized domains, e.g., medical. We propose a medical vision-language model that integrates large vision and language models adapted for the medical domain. This model goes through three stages of parameter-efficient training using three separate biomedical and radiology multi-modal visual and text datasets. The proposed model achieves state-of-the-art performance on the SLAKE 1.0 medical VQA (MedVQA) dataset with an overall accuracy of 87.5% and demonstrates strong performance on another MedVQA dataset, VQA-RAD, achieving an overall accuracy of 73.2%.
Read more4/26/2024