MegActor: Harness the Power of Raw Video for Vivid Portrait Animation
2405.20851
0
0
🔮
Abstract
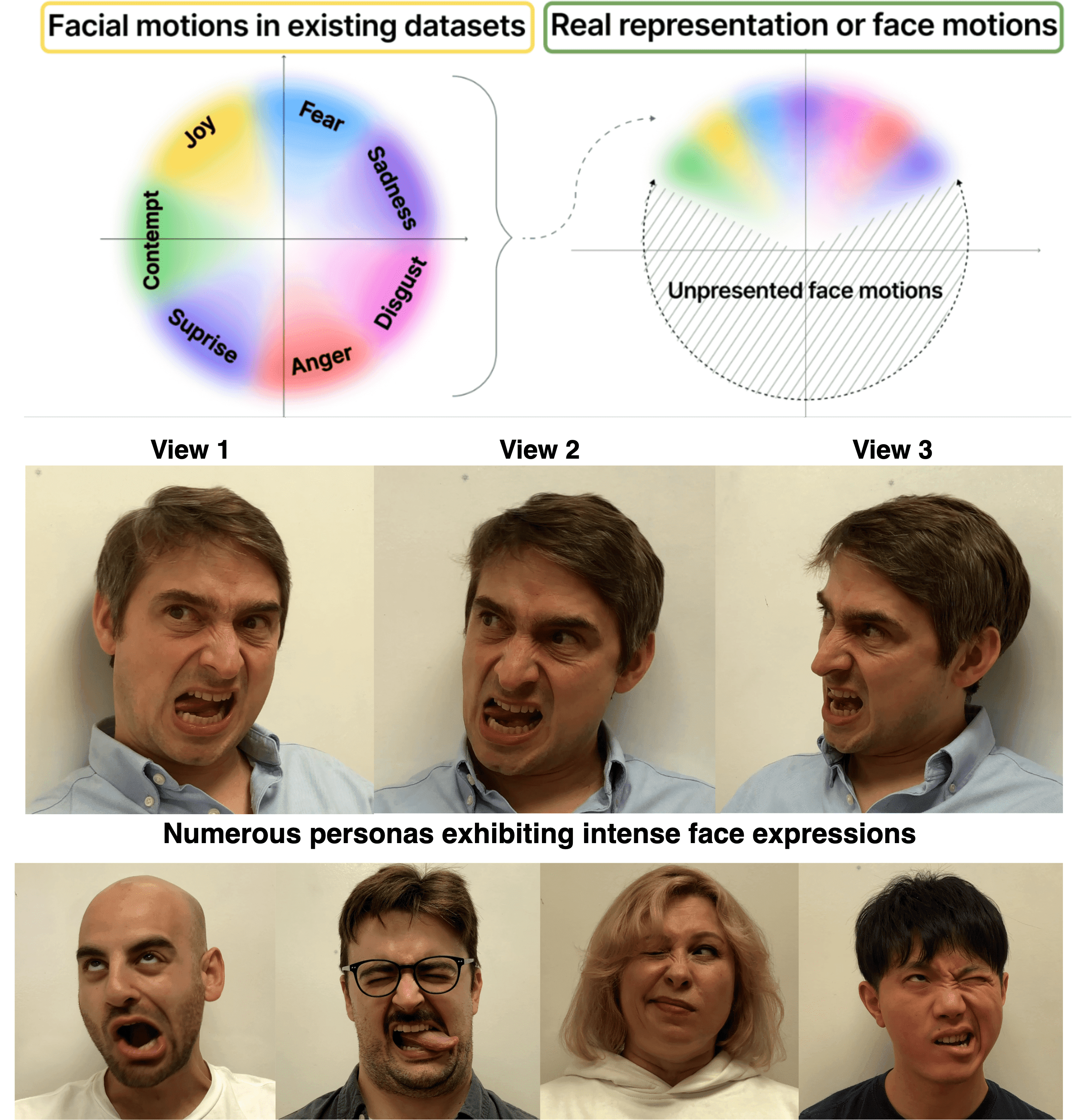
Despite raw driving videos contain richer information on facial expressions than intermediate representations such as landmarks in the field of portrait animation, they are seldom the subject of research. This is due to two challenges inherent in portrait animation driven with raw videos: 1) significant identity leakage; 2) Irrelevant background and facial details such as wrinkles degrade performance. To harnesses the power of the raw videos for vivid portrait animation, we proposed a pioneering conditional diffusion model named as MegActor. First, we introduced a synthetic data generation framework for creating videos with consistent motion and expressions but inconsistent IDs to mitigate the issue of ID leakage. Second, we segmented the foreground and background of the reference image and employed CLIP to encode the background details. This encoded information is then integrated into the network via a text embedding module, thereby ensuring the stability of the background. Finally, we further style transfer the appearance of the reference image to the driving video to eliminate the influence of facial details in the driving videos. Our final model was trained solely on public datasets, achieving results comparable to commercial models. We hope this will help the open-source community.The code is available at https://github.com/megvii-research/MegFaceAnimate.
Create account to get full access
Overview
- This paper presents several novel AI models for enhancing human visual and expressive capabilities, including EmotionPortraits, DisentangleFM, VividPose, IDAnimator, and FSRT.
- These models leverage advances in areas like emotion recognition, motion disentanglement, pose estimation, and facial reenactment to create more lifelike and expressive human avatars and animations.
- The research demonstrates how AI can be used to enhance human capabilities, with potential applications in areas like entertainment, communication, and creative expression.
Plain English Explanation
The researchers have developed several innovative AI models that can make human-like characters and animations more lifelike and emotionally expressive. For example, the EmotionPortraits model can capture a person's facial expressions and emotions and apply them to a digital character, allowing the character to mimic the person's emotional state.
Similarly, the DisentangleFM model can separate the movement of a person's body and face, allowing for more natural and realistic-looking animations. The VividPose model takes this a step further, generating realistic human poses and motions that can be used to create lifelike animations.
The IDAnimator model is designed to preserve a person's unique identity when creating digital avatars, ensuring that the avatar still looks and feels like the original person. Finally, the FSRT model can transfer facial expressions and movements from one person to another, enabling new forms of visual communication and collaboration.
Overall, these AI models represent significant advancements in the field of human-like digital characters and animations, with potential applications in areas like entertainment, gaming, and even remote communication and collaboration.
Technical Explanation
The EmotionPortraits model uses a multimodal one-shot learning approach to capture a person's facial expressions and emotions and apply them to a digital character. The model consists of a facial landmark detector, an emotion recognition module, and a character animation module that blends the detected emotions and expressions onto the character.
The DisentangleFM model uses a novel disentanglement technique to separate the motion of a person's body and face, allowing for more natural-looking animations. The model consists of a motion encoder, a foreground-background motion disentanglement module, and a motion decoder that generates the final animation.
The VividPose model uses a stable diffusion-based approach to generate realistic human poses and motions, which can then be used to create lifelike animations. The model consists of a pose encoder, a diffusion-based pose generation module, and a motion synthesis module that generates the final animation.
The IDAnimator model uses a zero-shot learning approach to preserve a person's unique identity when creating digital avatars. The model consists of a facial feature encoder, an identity-preserving animation module, and a rendering module that generates the final avatar.
Finally, the FSRT model uses a facial scene representation transformer to transfer facial expressions and movements from one person to another. The model consists of a facial feature encoder, a facial scene representation transformer, and a rendering module that generates the final reenactment.
Critical Analysis
The research presented in this paper demonstrates significant advances in the field of human-like digital characters and animations. The models developed by the researchers show the potential of AI to enhance human visual and expressive capabilities, with applications in areas like entertainment, communication, and creative expression.
However, it's important to note that these models have some limitations. For example, the EmotionPortraits model may struggle to accurately capture and reproduce complex or nuanced emotional expressions, and the DisentangleFM model may not be able to handle more complex or irregular motion patterns.
Additionally, there are concerns about the ethical implications of these technologies, such as the potential for misuse in areas like deepfakes or the creation of deceptive or manipulative content. The researchers acknowledge these concerns and suggest that further research is needed to address them.
Overall, the research presented in this paper represents an exciting and promising step forward in the field of human-like digital characters and animations. While there are some limitations and ethical considerations to be addressed, the potential of these technologies to enhance human capabilities and expand the possibilities of creative expression is significant.
Conclusion
This paper presents several novel AI models that can enhance the realism and expressiveness of human-like digital characters and animations. The models leverage advances in areas like emotion recognition, motion disentanglement, pose estimation, and facial reenactment to create more lifelike and engaging digital avatars and animations.
The research demonstrates the potential of AI to augment and expand human visual and expressive capabilities, with applications in entertainment, communication, and creative expression. While there are some limitations and ethical considerations to be addressed, the advances presented in this paper represent an exciting and promising step forward in the field of human-like digital characters and animations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
EMOPortraits: Emotion-enhanced Multimodal One-shot Head Avatars
Nikita Drobyshev, Antoni Bigata Casademunt, Konstantinos Vougioukas, Zoe Landgraf, Stavros Petridis, Maja Pantic
0
0
Head avatars animated by visual signals have gained popularity, particularly in cross-driving synthesis where the driver differs from the animated character, a challenging but highly practical approach. The recently presented MegaPortraits model has demonstrated state-of-the-art results in this domain. We conduct a deep examination and evaluation of this model, with a particular focus on its latent space for facial expression descriptors, and uncover several limitations with its ability to express intense face motions. To address these limitations, we propose substantial changes in both training pipeline and model architecture, to introduce our EMOPortraits model, where we: Enhance the model's capability to faithfully support intense, asymmetric face expressions, setting a new state-of-the-art result in the emotion transfer task, surpassing previous methods in both metrics and quality. Incorporate speech-driven mode to our model, achieving top-tier performance in audio-driven facial animation, making it possible to drive source identity through diverse modalities, including visual signal, audio, or a blend of both. We propose a novel multi-view video dataset featuring a wide range of intense and asymmetric facial expressions, filling the gap with absence of such data in existing datasets.
5/1/2024

New!LivePortrait: Efficient Portrait Animation with Stitching and Retargeting Control
Jianzhu Guo, Dingyun Zhang, Xiaoqiang Liu, Zhizhou Zhong, Yuan Zhang, Pengfei Wan, Di Zhang
0
0
Portrait Animation aims to synthesize a lifelike video from a single source image, using it as an appearance reference, with motion (i.e., facial expressions and head pose) derived from a driving video, audio, text, or generation. Instead of following mainstream diffusion-based methods, we explore and extend the potential of the implicit-keypoint-based framework, which effectively balances computational efficiency and controllability. Building upon this, we develop a video-driven portrait animation framework named LivePortrait with a focus on better generalization, controllability, and efficiency for practical usage. To enhance the generation quality and generalization ability, we scale up the training data to about 69 million high-quality frames, adopt a mixed image-video training strategy, upgrade the network architecture, and design better motion transformation and optimization objectives. Additionally, we discover that compact implicit keypoints can effectively represent a kind of blendshapes and meticulously propose a stitching and two retargeting modules, which utilize a small MLP with negligible computational overhead, to enhance the controllability. Experimental results demonstrate the efficacy of our framework even compared to diffusion-based methods. The generation speed remarkably reaches 12.8ms on an RTX 4090 GPU with PyTorch. The inference code and models are available at https://github.com/KwaiVGI/LivePortrait
7/4/2024
🛸
Disentangling Foreground and Background Motion for Enhanced Realism in Human Video Generation
Jinlin Liu, Kai Yu, Mengyang Feng, Xiefan Guo, Miaomiao Cui
0
0
Recent advancements in human video synthesis have enabled the generation of high-quality videos through the application of stable diffusion models. However, existing methods predominantly concentrate on animating solely the human element (the foreground) guided by pose information, while leaving the background entirely static. Contrary to this, in authentic, high-quality videos, backgrounds often dynamically adjust in harmony with foreground movements, eschewing stagnancy. We introduce a technique that concurrently learns both foreground and background dynamics by segregating their movements using distinct motion representations. Human figures are animated leveraging pose-based motion, capturing intricate actions. Conversely, for backgrounds, we employ sparse tracking points to model motion, thereby reflecting the natural interaction between foreground activity and environmental changes. Training on real-world videos enhanced with this innovative motion depiction approach, our model generates videos exhibiting coherent movement in both foreground subjects and their surrounding contexts. To further extend video generation to longer sequences without accumulating errors, we adopt a clip-by-clip generation strategy, introducing global features at each step. To ensure seamless continuity across these segments, we ingeniously link the final frame of a produced clip with input noise to spawn the succeeding one, maintaining narrative flow. Throughout the sequential generation process, we infuse the feature representation of the initial reference image into the network, effectively curtailing any cumulative color inconsistencies that may otherwise arise. Empirical evaluations attest to the superiority of our method in producing videos that exhibit harmonious interplay between foreground actions and responsive background dynamics, surpassing prior methodologies in this regard.
5/29/2024

VividPose: Advancing Stable Video Diffusion for Realistic Human Image Animation
Qilin Wang, Zhengkai Jiang, Chengming Xu, Jiangning Zhang, Yabiao Wang, Xinyi Zhang, Yun Cao, Weijian Cao, Chengjie Wang, Yanwei Fu
0
0
Human image animation involves generating a video from a static image by following a specified pose sequence. Current approaches typically adopt a multi-stage pipeline that separately learns appearance and motion, which often leads to appearance degradation and temporal inconsistencies. To address these issues, we propose VividPose, an innovative end-to-end pipeline based on Stable Video Diffusion (SVD) that ensures superior temporal stability. To enhance the retention of human identity, we propose an identity-aware appearance controller that integrates additional facial information without compromising other appearance details such as clothing texture and background. This approach ensures that the generated videos maintain high fidelity to the identity of human subject, preserving key facial features across various poses. To accommodate diverse human body shapes and hand movements, we introduce a geometry-aware pose controller that utilizes both dense rendering maps from SMPL-X and sparse skeleton maps. This enables accurate alignment of pose and shape in the generated videos, providing a robust framework capable of handling a wide range of body shapes and dynamic hand movements. Extensive qualitative and quantitative experiments on the UBCFashion and TikTok benchmarks demonstrate that our method achieves state-of-the-art performance. Furthermore, VividPose exhibits superior generalization capabilities on our proposed in-the-wild dataset. Codes and models will be available.
5/29/2024