IndicGenBench: A Multilingual Benchmark to Evaluate Generation Capabilities of LLMs on Indic Languages
2404.16816
0
0
🛸
Abstract
As large language models (LLMs) see increasing adoption across the globe, it is imperative for LLMs to be representative of the linguistic diversity of the world. India is a linguistically diverse country of 1.4 Billion people. To facilitate research on multilingual LLM evaluation, we release IndicGenBench - the largest benchmark for evaluating LLMs on user-facing generation tasks across a diverse set 29 of Indic languages covering 13 scripts and 4 language families. IndicGenBench is composed of diverse generation tasks like cross-lingual summarization, machine translation, and cross-lingual question answering. IndicGenBench extends existing benchmarks to many Indic languages through human curation providing multi-way parallel evaluation data for many under-represented Indic languages for the first time. We evaluate a wide range of proprietary and open-source LLMs including GPT-3.5, GPT-4, PaLM-2, mT5, Gemma, BLOOM and LLaMA on IndicGenBench in a variety of settings. The largest PaLM-2 models performs the best on most tasks, however, there is a significant performance gap in all languages compared to English showing that further research is needed for the development of more inclusive multilingual language models. IndicGenBench is released at www.github.com/google-research-datasets/indic-gen-bench
Get summaries of the top AI research delivered straight to your inbox:
Overview
- The paper focuses on the need for large language models (LLMs) to be representative of the linguistic diversity of the world, particularly in the context of India, a country with over 1.4 billion people and a vast array of languages.
- The authors introduce IndicGenBench, the largest benchmark for evaluating LLMs on user-facing generation tasks across 29 Indic languages, covering 13 scripts and 4 language families.
- IndicGenBench includes diverse generation tasks such as cross-lingual summarization, machine translation, and cross-lingual question answering, extending existing benchmarks to many Indic languages through human curation.
- The authors evaluate a range of proprietary and open-source LLMs, including GPT-3.5, GPT-4, PaLM-2, mT5, Gemma, BLOOM, and LLaMA, on IndicGenBench, revealing a significant performance gap in all languages compared to English.
Plain English Explanation
As large language models (LLMs) become more widely used around the world, it's crucial that they can understand and communicate in the diverse languages spoken by people globally. India, with its 1.4 billion people, is a prime example of a linguistically diverse country, with over 29 Indic languages across 13 scripts and 4 language families.
To help researchers better evaluate how well LLMs can handle this linguistic diversity, the authors of this paper have created a new benchmark called IndicGenBench. This benchmark includes a wide range of tasks that LLMs might need to perform, such as summarizing text in different languages, translating between languages, and answering questions in multiple languages.
The researchers tested a variety of popular LLMs, including GPT-3.5, GPT-4, PaLM-2, and others, on IndicGenBench. They found that even the largest and most powerful LLMs still struggle to match their performance on Indic languages compared to English, suggesting that more work is needed to develop LLMs that can truly understand and communicate effectively in the world's many languages.
Technical Explanation
The paper introduces IndicGenBench, a new benchmark for evaluating the performance of large language models (LLMs) on user-facing generation tasks across 29 Indic languages, covering 13 scripts and 4 language families. This benchmark is designed to address the need for more representative and inclusive LLMs that can handle the linguistic diversity of the world, particularly in the context of India.
IndicGenBench extends existing benchmarks by providing multi-way parallel evaluation data for many under-represented Indic languages. The benchmark includes diverse generation tasks such as cross-lingual summarization, machine translation, and cross-lingual question answering, allowing for a comprehensive evaluation of LLM capabilities.
The authors evaluate a wide range of proprietary and open-source LLMs, including GPT-3.5, GPT-4, PaLM-2, mT5, Gemma, BLOOM, and LLaMA, on IndicGenBench. The results show that the largest PaLM-2 models perform the best on most tasks, but there is a significant performance gap in all languages compared to English. This suggests that further research is needed to develop more inclusive multilingual language models that can better handle the diverse languages spoken around the world.
Critical Analysis
The authors' efforts to create a comprehensive benchmark like IndicGenBench are commendable, as they address a critical need for evaluating the linguistic capabilities of LLMs in a diverse set of Indic languages. However, the paper does not provide much insight into the potential causes of the performance gap observed across the tested LLMs.
It would be interesting to explore whether the performance discrepancy is due to factors such as the availability and quality of training data for Indic languages, the inherent complexity of the languages, or limitations in the architecture and training approaches of the current LLMs. Additionally, the paper does not discuss potential biases or representational issues that may be present in the LLMs, which could be further explored using benchmarks such as IndiBias.
Furthermore, the paper focuses on user-facing generation tasks, but it would be valuable to also evaluate the LLMs' performance on other tasks, such as medical question answering or reference-less evaluation, to gain a more comprehensive understanding of their capabilities across different domains.
Conclusion
The IndicGenBench benchmark introduced in this paper is a significant contribution to the field of multilingual language model evaluation, particularly in the context of the linguistically diverse Indian subcontinent. The findings highlight the need for continued research and development to create LLMs that can truly represent the global linguistic landscape and provide equitable access to language-based technologies for all people.
As large language models become increasingly ubiquitous, it is crucial that they are designed and evaluated with a focus on inclusivity and representation. The IndicGenBench dataset and the insights gained from the authors' evaluation of various LLMs on this benchmark provide a valuable foundation for future work in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
MEGAVERSE: Benchmarking Large Language Models Across Languages, Modalities, Models and Tasks
Sanchit Ahuja, Divyanshu Aggarwal, Varun Gumma, Ishaan Watts, Ashutosh Sathe, Millicent Ochieng, Rishav Hada, Prachi Jain, Maxamed Axmed, Kalika Bali, Sunayana Sitaram
0
0
There has been a surge in LLM evaluation research to understand LLM capabilities and limitations. However, much of this research has been confined to English, leaving LLM building and evaluation for non-English languages relatively unexplored. Several new LLMs have been introduced recently, necessitating their evaluation on non-English languages. This study aims to perform a thorough evaluation of the non-English capabilities of SoTA LLMs (GPT-3.5-Turbo, GPT-4, PaLM2, Gemini-Pro, Mistral, Llama2, and Gemma) by comparing them on the same set of multilingual datasets. Our benchmark comprises 22 datasets covering 83 languages, including low-resource African languages. We also include two multimodal datasets in the benchmark and compare the performance of LLaVA models, GPT-4-Vision and Gemini-Pro-Vision. Our experiments show that larger models such as GPT-4, Gemini-Pro and PaLM2 outperform smaller models on various tasks, notably on low-resource languages, with GPT-4 outperforming PaLM2 and Gemini-Pro on more datasets. We also perform a study on data contamination and find that several models are likely to be contaminated with multilingual evaluation benchmarks, necessitating approaches to detect and handle contamination while assessing the multilingual performance of LLMs.
4/4/2024

GenTranslate: Large Language Models are Generative Multilingual Speech and Machine Translators
Yuchen Hu, Chen Chen, Chao-Han Huck Yang, Ruizhe Li, Dong Zhang, Zhehuai Chen, Eng Siong Chng
0
0
Recent advances in large language models (LLMs) have stepped forward the development of multilingual speech and machine translation by its reduced representation errors and incorporated external knowledge. However, both translation tasks typically utilize beam search decoding and top-1 hypothesis selection for inference. These techniques struggle to fully exploit the rich information in the diverse N-best hypotheses, making them less optimal for translation tasks that require a single, high-quality output sequence. In this paper, we propose a new generative paradigm for translation tasks, namely GenTranslate, which builds upon LLMs to generate better results from the diverse translation versions in N-best list. Leveraging the rich linguistic knowledge and strong reasoning abilities of LLMs, our new paradigm can integrate the rich information in N-best candidates to generate a higher-quality translation result. Furthermore, to support LLM finetuning, we build and release a HypoTranslate dataset that contains over 592K hypotheses-translation pairs in 11 languages. Experiments on various speech and machine translation benchmarks (e.g., FLEURS, CoVoST-2, WMT) demonstrate that our GenTranslate significantly outperforms the state-of-the-art model.
5/17/2024

IndiBias: A Benchmark Dataset to Measure Social Biases in Language Models for Indian Context
Nihar Ranjan Sahoo, Pranamya Prashant Kulkarni, Narjis Asad, Arif Ahmad, Tanu Goyal, Aparna Garimella, Pushpak Bhattacharyya
0
0
The pervasive influence of social biases in language data has sparked the need for benchmark datasets that capture and evaluate these biases in Large Language Models (LLMs). Existing efforts predominantly focus on English language and the Western context, leaving a void for a reliable dataset that encapsulates India's unique socio-cultural nuances. To bridge this gap, we introduce IndiBias, a comprehensive benchmarking dataset designed specifically for evaluating social biases in the Indian context. We filter and translate the existing CrowS-Pairs dataset to create a benchmark dataset suited to the Indian context in Hindi language. Additionally, we leverage LLMs including ChatGPT and InstructGPT to augment our dataset with diverse societal biases and stereotypes prevalent in India. The included bias dimensions encompass gender, religion, caste, age, region, physical appearance, and occupation. We also build a resource to address intersectional biases along three intersectional dimensions. Our dataset contains 800 sentence pairs and 300 tuples for bias measurement across different demographics. The dataset is available in English and Hindi, providing a size comparable to existing benchmark datasets. Furthermore, using IndiBias we compare ten different language models on multiple bias measurement metrics. We observed that the language models exhibit more bias across a majority of the intersectional groups.
4/4/2024
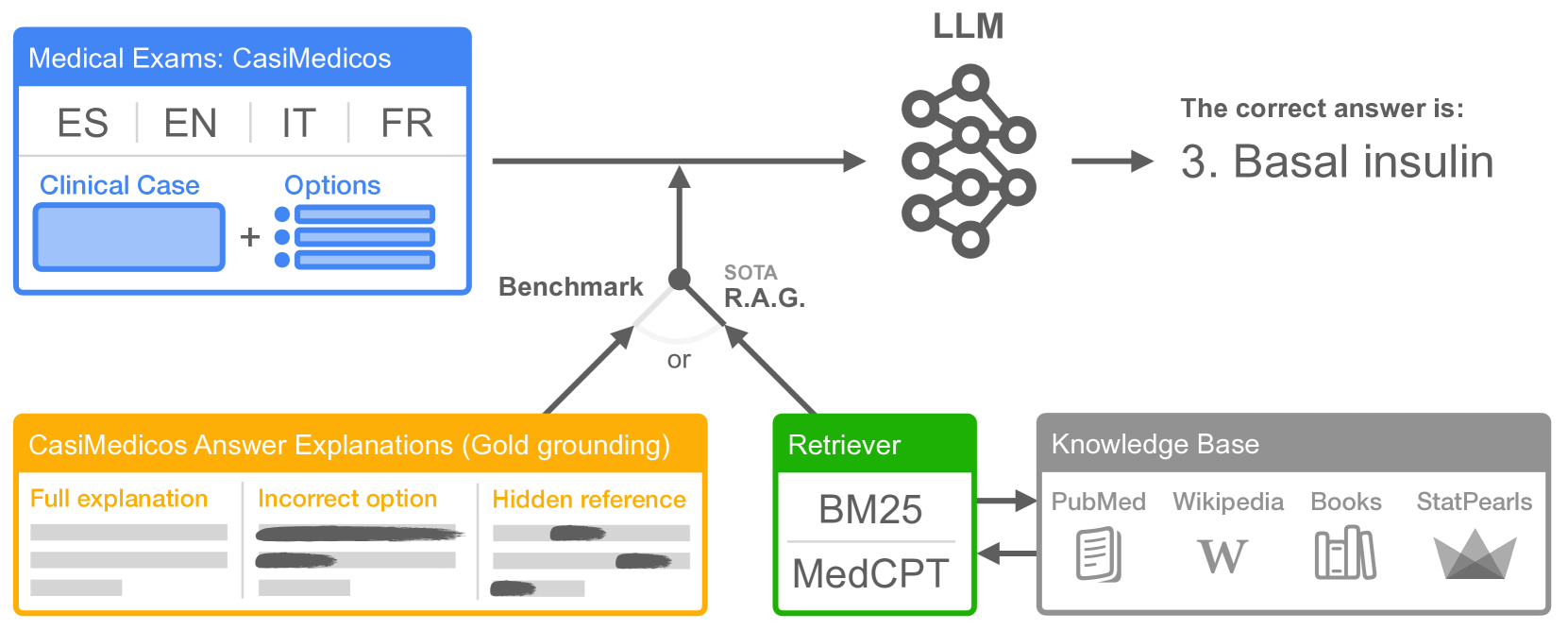
MedExpQA: Multilingual Benchmarking of Large Language Models for Medical Question Answering
I~nigo Alonso, Maite Oronoz, Rodrigo Agerri
0
0
Large Language Models (LLMs) have the potential of facilitating the development of Artificial Intelligence technology to assist medical experts for interactive decision support, which has been demonstrated by their competitive performances in Medical QA. However, while impressive, the required quality bar for medical applications remains far from being achieved. Currently, LLMs remain challenged by outdated knowledge and by their tendency to generate hallucinated content. Furthermore, most benchmarks to assess medical knowledge lack reference gold explanations which means that it is not possible to evaluate the reasoning of LLMs predictions. Finally, the situation is particularly grim if we consider benchmarking LLMs for languages other than English which remains, as far as we know, a totally neglected topic. In order to address these shortcomings, in this paper we present MedExpQA, the first multilingual benchmark based on medical exams to evaluate LLMs in Medical Question Answering. To the best of our knowledge, MedExpQA includes for the first time reference gold explanations written by medical doctors which can be leveraged to establish various gold-based upper-bounds for comparison with LLMs performance. Comprehensive multilingual experimentation using both the gold reference explanations and Retrieval Augmented Generation (RAG) approaches show that performance of LLMs still has large room for improvement, especially for languages other than English. Furthermore, and despite using state-of-the-art RAG methods, our results also demonstrate the difficulty of obtaining and integrating readily available medical knowledge that may positively impact results on downstream evaluations for Medical Question Answering. So far the benchmark is available in four languages, but we hope that this work may encourage further development to other languages.
4/9/2024