MELTing point: Mobile Evaluation of Language Transformers

22
Sign in to get full access
Overview
- Presents a mobile evaluation framework called "MELTing point" for assessing the performance of large language models (LLMs) on mobile devices
- Explores the deployment challenges of LLMs on resource-constrained mobile platforms
- Provides insights into the trade-offs between model size, latency, and accuracy when running LLMs on smartphones
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown impressive capabilities, but running these complex models on mobile devices can be challenging. The paper introduces a framework called "MELTing point" that helps researchers and developers evaluate the performance of LLMs on smartphones and other mobile platforms.
The key idea is to understand the trade-offs between the size of the language model, how quickly it can process input (latency), and how accurate its outputs are. By testing LLMs on real mobile devices, the researchers can provide insights to help optimize these models for deployment on resource-constrained platforms.
This is important because many real-world applications, like virtual assistants or language-based apps, need to run on smartphones and other mobile devices. The paper's findings can guide the development of more efficient and effective LLMs that can be used on the go, without requiring a powerful desktop computer or server.
Technical Explanation
The paper presents the "MELTing point" (Mobile Evaluation of Language Transformers) framework, which allows researchers to assess the performance of LLMs on mobile devices. The framework includes:
- A set of mobile benchmark tasks that capture different aspects of LLM performance, such as text generation, question answering, and natural language inference.
- A mobile device test suite that covers a range of smartphone models and hardware configurations to provide a comprehensive evaluation.
- Detailed performance metrics that go beyond just accuracy, including latency, energy consumption, and memory usage.
The researchers use this framework to evaluate several popular LLMs, including GPT-3, T5, and BERT, on a diverse set of mobile devices. Their findings reveal the trade-offs between model size, latency, and accuracy, and provide guidelines for deploying LLMs on resource-constrained platforms.
Critical Analysis
The paper provides a valuable framework for assessing the mobile deployment of LLMs, an important consideration as these powerful models become more widely used in real-world applications. The researchers acknowledge several limitations of their study, such as the need for a larger and more diverse set of mobile devices and benchmark tasks.
Additionally, the paper does not delve into the potential privacy and security implications of running LLMs on mobile devices, which may store sensitive user data. Further research is needed to address these concerns and ensure the safe and ethical deployment of LLMs on personal computing platforms.
Conclusion
The "MELTing point" framework offers a comprehensive approach to evaluating the performance of LLMs on mobile devices, providing insights that can guide the development of more efficient and effective language models for on-the-go use cases. As LLMs continue to advance and become more ubiquitous, this research helps bridge the gap between powerful AI models and the resource-constrained reality of mobile computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
22
MELTing point: Mobile Evaluation of Language Transformers
Stefanos Laskaridis, Kleomenis Katevas, Lorenzo Minto, Hamed Haddadi
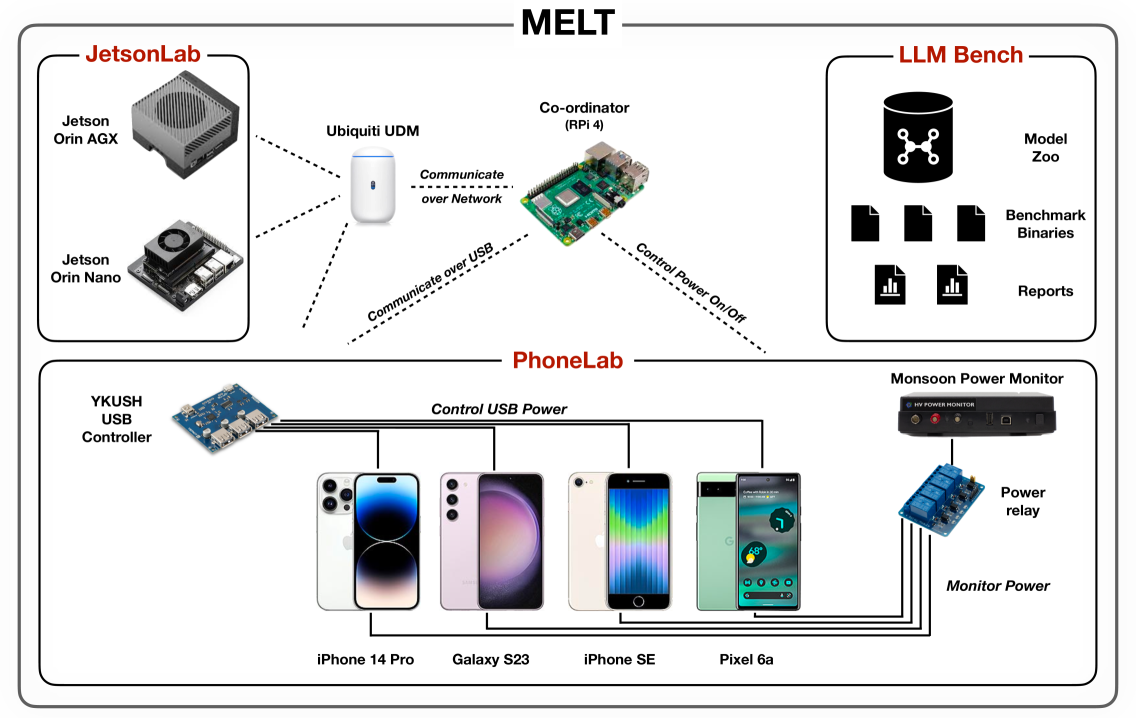
Transformers have revolutionized the machine learning landscape, gradually making their way into everyday tasks and equipping our computers with sparks of intelligence. However, their runtime requirements have prevented them from being broadly deployed on mobile. As personal devices become increasingly powerful and prompt privacy becomes an ever more pressing issue, we explore the current state of mobile execution of Large Language Models (LLMs). To achieve this, we have created our own automation infrastructure, MELT, which supports the headless execution and benchmarking of LLMs on device, supporting different models, devices and frameworks, including Android, iOS and Nvidia Jetson devices. We evaluate popular instruction fine-tuned LLMs and leverage different frameworks to measure their end-to-end and granular performance, tracing their memory and energy requirements along the way. Our analysis is the first systematic study of on-device LLM execution, quantifying performance, energy efficiency and accuracy across various state-of-the-art models and showcases the state of on-device intelligence in the era of hyperscale models. Results highlight the performance heterogeneity across targets and corroborates that LLM inference is largely memory-bound. Quantization drastically reduces memory requirements and renders execution viable, but at a non-negligible accuracy cost. Drawing from its energy footprint and thermal behavior, the continuous execution of LLMs remains elusive, as both factors negatively affect user experience. Last, our experience shows that the ecosystem is still in its infancy, and algorithmic as well as hardware breakthroughs can significantly shift the execution cost. We expect NPU acceleration, and framework-hardware co-design to be the biggest bet towards efficient standalone execution, with the alternative of offloading tailored towards edge deployments.
Read more7/29/2024
💬
0
Transformer-Lite: High-efficiency Deployment of Large Language Models on Mobile Phone GPUs
Luchang Li, Sheng Qian, Jie Lu, Lunxi Yuan, Rui Wang, Qin Xie
The Large Language Model (LLM) is widely employed for tasks such as intelligent assistants, text summarization, translation, and multi-modality on mobile phones. However, the current methods for on-device LLM deployment maintain slow inference speed, which causes poor user experience. To facilitate high-efficiency LLM deployment on device GPUs, we propose four optimization techniques: (a) a symbolic expression-based approach to support dynamic shape model inference; (b) operator optimizations and execution priority setting to enhance inference speed and reduce phone lagging; (c) an FP4 quantization method termed M0E4 to reduce dequantization overhead; (d) a sub-tensor-based technique to eliminate the need for copying KV cache after LLM inference. Furthermore, we implement these methods in our mobile inference engine, Transformer-Lite, which is compatible with both Qualcomm and MTK processors. We evaluated Transformer-Lite's performance using LLMs with varied architectures and parameters ranging from 2B to 14B. Specifically, we achieved prefill and decoding speeds of 121 token/s and 14 token/s for ChatGLM2 6B, and 330 token/s and 30 token/s for smaller Gemma 2B, respectively. Compared with CPU-based FastLLM and GPU-based MLC-LLM, our engine attains over 10x speedup for the prefill speed and 2~3x speedup for the decoding speed.
Read more7/8/2024
0
MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases
Rithesh Murthy, Liangwei Yang, Juntao Tan, Tulika Manoj Awalgaonkar, Yilun Zhou, Shelby Heinecke, Sachin Desai, Jason Wu, Ran Xu, Sarah Tan, Jianguo Zhang, Zhiwei Liu, Shirley Kokane, Zuxin Liu, Ming Zhu, Huan Wang, Caiming Xiong, Silvio Savarese
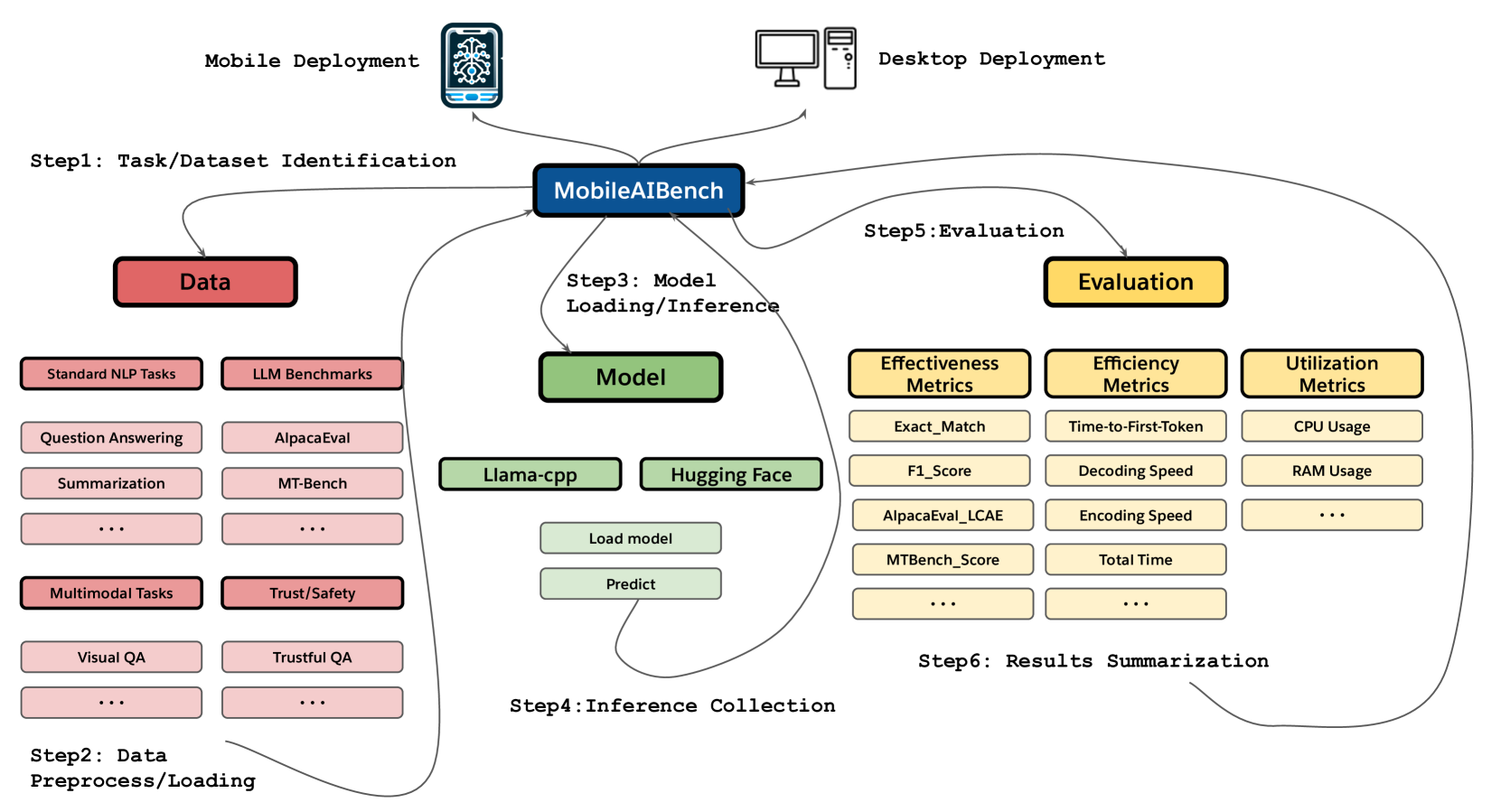
The deployment of Large Language Models (LLMs) and Large Multimodal Models (LMMs) on mobile devices has gained significant attention due to the benefits of enhanced privacy, stability, and personalization. However, the hardware constraints of mobile devices necessitate the use of models with fewer parameters and model compression techniques like quantization. Currently, there is limited understanding of quantization's impact on various task performances, including LLM tasks, LMM tasks, and, critically, trust and safety. There is a lack of adequate tools for systematically testing these models on mobile devices. To address these gaps, we introduce MobileAIBench, a comprehensive benchmarking framework for evaluating mobile-optimized LLMs and LMMs. MobileAIBench assesses models across different sizes, quantization levels, and tasks, measuring latency and resource consumption on real devices. Our two-part open-source framework includes a library for running evaluations on desktops and an iOS app for on-device latency and hardware utilization measurements. Our thorough analysis aims to accelerate mobile AI research and deployment by providing insights into the performance and feasibility of deploying LLMs and LMMs on mobile platforms.
Read more6/18/2024

0
On-Device Language Models: A Comprehensive Review
Jiajun Xu, Zhiyuan Li, Wei Chen, Qun Wang, Xin Gao, Qi Cai, Ziyuan Ling
The advent of large language models (LLMs) revolutionized natural language processing applications, and running LLMs on edge devices has become increasingly attractive for reasons including reduced latency, data localization, and personalized user experiences. This comprehensive review examines the challenges of deploying computationally expensive LLMs on resource-constrained devices and explores innovative solutions across multiple domains. The paper investigates the development of on-device language models, their efficient architectures, including parameter sharing and modular designs, as well as state-of-the-art compression techniques like quantization, pruning, and knowledge distillation. Hardware acceleration strategies and collaborative edge-cloud deployment approaches are analyzed, highlighting the intricate balance between performance and resource utilization. Case studies of on-device language models from major mobile manufacturers demonstrate real-world applications and potential benefits. The review also addresses critical aspects such as adaptive learning, multi-modal capabilities, and personalization. By identifying key research directions and open challenges, this paper provides a roadmap for future advancements in on-device language models, emphasizing the need for interdisciplinary efforts to realize the full potential of ubiquitous, intelligent computing while ensuring responsible and ethical deployment. For a comprehensive review of research work and educational resources on on-device large language models (LLMs), please visit https://github.com/NexaAI/Awesome-LLMs-on-device. To download and run on-device LLMs, visit https://www.nexaai.com/models.
Read more9/4/2024