MobileAIBench: Benchmarking LLMs and LMMs for On-Device Use Cases
2406.10290
0
0
Abstract
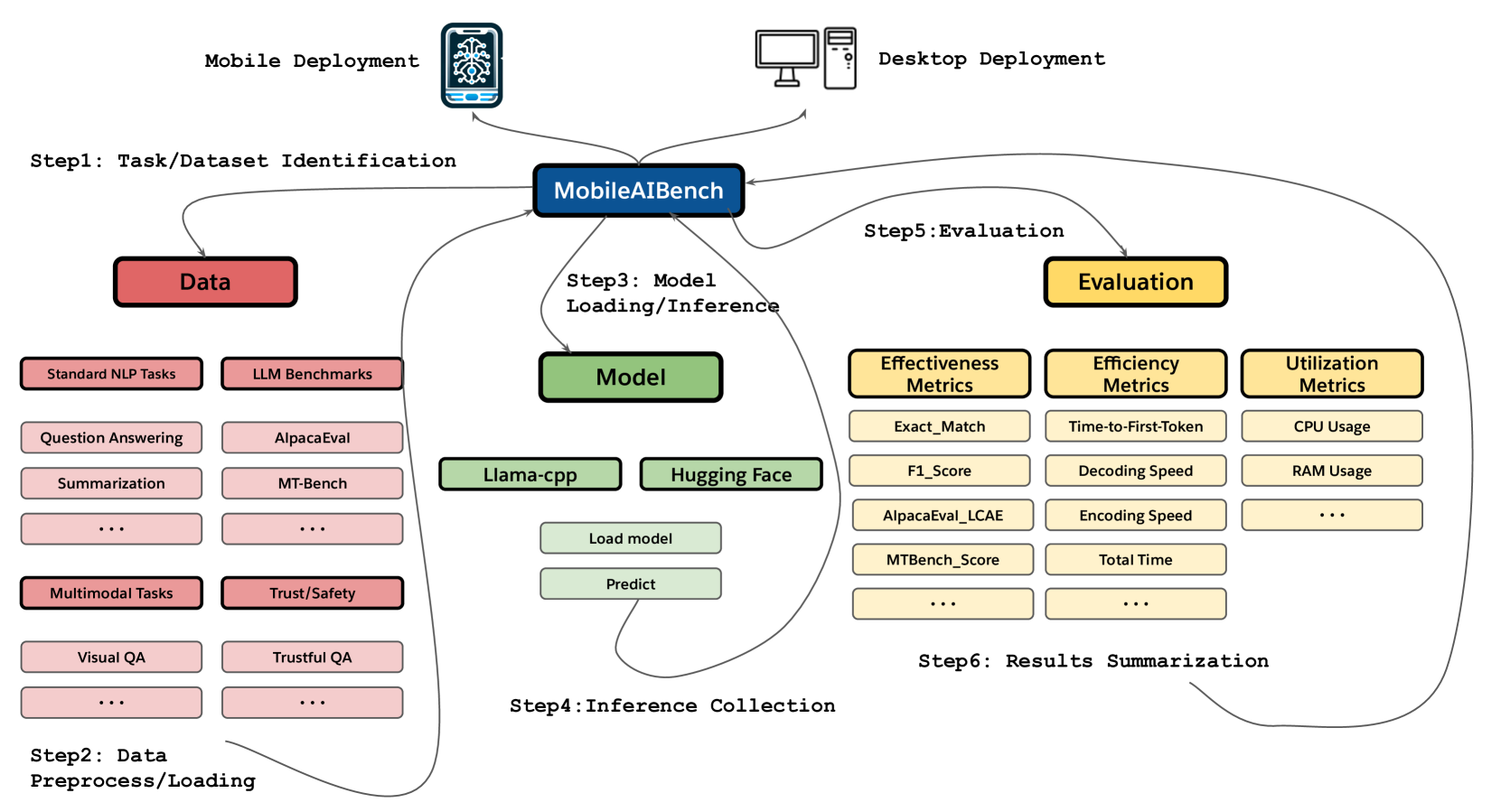
The deployment of Large Language Models (LLMs) and Large Multimodal Models (LMMs) on mobile devices has gained significant attention due to the benefits of enhanced privacy, stability, and personalization. However, the hardware constraints of mobile devices necessitate the use of models with fewer parameters and model compression techniques like quantization. Currently, there is limited understanding of quantization's impact on various task performances, including LLM tasks, LMM tasks, and, critically, trust and safety. There is a lack of adequate tools for systematically testing these models on mobile devices. To address these gaps, we introduce MobileAIBench, a comprehensive benchmarking framework for evaluating mobile-optimized LLMs and LMMs. MobileAIBench assesses models across different sizes, quantization levels, and tasks, measuring latency and resource consumption on real devices. Our two-part open-source framework includes a library for running evaluations on desktops and an iOS app for on-device latency and hardware utilization measurements. Our thorough analysis aims to accelerate mobile AI research and deployment by providing insights into the performance and feasibility of deploying LLMs and LMMs on mobile platforms.
Create account to get full access
Overview
- This paper introduces MobileAIBench, a new benchmark for evaluating large language models (LLMs) and language model mixtures (LMMs) for on-device use cases.
- It covers related work in mobile AI benchmarking and quantization techniques for deploying large models on edge devices.
- The authors design a diverse set of tasks and metrics to assess the performance, efficiency, and latency of different model configurations on mobile hardware.
- They evaluate a range of LLMs and LMMs, providing insights on the tradeoffs between model size, accuracy, and inference time on mobile platforms.
Plain English Explanation
The paper presents a new benchmark called MobileAIBench that is designed to test how well large AI language models perform when running on mobile devices like smartphones. Large language models (LLMs) are powerful AI systems that can understand and generate human-like text, but they are often very large and computationally intensive, making them challenging to run on small, resource-constrained devices.
The researchers created MobileAIBench to evaluate the performance, efficiency, and latency of different LLMs and mixtures of language models (LMMs) when deployed on mobile hardware. They designed a variety of tasks and metrics to assess how well these models can handle real-world on-device use cases, like text generation, question answering, and sentiment analysis.
By testing a range of different model configurations, the authors were able to uncover important tradeoffs between model size, accuracy, and inference speed on mobile platforms. This information can help AI researchers and developers make more informed decisions about which language models to use for mobile applications and how to optimize their performance.
The paper also reviews related work in mobile AI benchmarking and techniques like model quantization, which can help compress large models to run more efficiently on edge devices. Overall, MobileAIBench provides a valuable new tool for evaluating the suitability of advanced language models for on-device use cases.
Technical Explanation
The paper introduces MobileAIBench, a benchmark designed to evaluate the performance of large language models (LLMs) and language model mixtures (LMMs) for on-device use cases. The authors review related work in mobile AI benchmarking, such as TinyBenchmarks and model quantization techniques like CompressAILity and ComprehensiveEval.
The core of MobileAIBench is a diverse set of tasks and metrics that assess different aspects of model performance on mobile hardware, including text generation, question answering, and sentiment analysis. The authors evaluate a range of LLM and LMM configurations, measuring inference latency, energy consumption, and other key metrics. Their results provide insights on the tradeoffs between model size, accuracy, and efficiency for on-device deployment.
For example, the authors find that some LMMs can achieve comparable accuracy to larger LLMs while being more efficient and performant on mobile platforms. They also identify key factors, such as model architecture and quantization strategies, that influence a model's suitability for mobile use cases.
Critical Analysis
The paper provides a thorough and well-designed benchmark for evaluating LLMs and LMMs on mobile devices. The diverse set of tasks and metrics used in MobileAIBench represents a significant advancement over prior mobile AI benchmarks, which tended to focus on narrow or synthetic workloads.
However, the authors acknowledge several limitations in their work. First, the benchmark is primarily focused on natural language processing tasks, whereas many real-world mobile applications may require multimodal or cross-domain capabilities. Additionally, the paper does not explore the impact of hardware heterogeneity, as the experiments were conducted on a single mobile device.
Another potential issue is that the benchmark may not fully capture the user experience and practical constraints of on-device deployment, such as model startup time, memory footprint, and the overhead of model updates. Further research is needed to understand how these factors affect the usability and deployment of LLMs and LMMs on mobile platforms.
Finally, while the paper provides valuable insights, it would be helpful to see the authors' reflections on the broader implications of their work. For instance, how might the lessons learned from MobileAIBench inform the design of future mobile AI systems or the development of more efficient language models in general?
Conclusion
The MobileAIBench paper presents a comprehensive new benchmark for evaluating large language models and language model mixtures on mobile devices. By designing a diverse set of tasks and metrics, the authors were able to uncover important tradeoffs between model size, accuracy, and efficiency when deploying these advanced AI systems on resource-constrained platforms.
The insights gained from this work can help guide the development of more powerful and practical mobile AI applications. As the use of large language models continues to proliferate, having a robust benchmark like MobileAIBench will be invaluable for ensuring these models can be effectively and efficiently deployed on a wide range of mobile and edge devices.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
MobileLLM: Optimizing Sub-billion Parameter Language Models for On-Device Use Cases
Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra
0
0
This paper addresses the growing need for efficient large language models (LLMs) on mobile devices, driven by increasing cloud costs and latency concerns. We focus on designing top-quality LLMs with fewer than a billion parameters, a practical choice for mobile deployment. Contrary to prevailing belief emphasizing the pivotal role of data and parameter quantity in determining model quality, our investigation underscores the significance of model architecture for sub-billion scale LLMs. Leveraging deep and thin architectures, coupled with embedding sharing and grouped-query attention mechanisms, we establish a strong baseline network denoted as MobileLLM, which attains a remarkable 2.7%/4.3% accuracy boost over preceding 125M/350M state-of-the-art models. Additionally, we propose an immediate block-wise weight-sharing approach with no increase in model size and only marginal latency overhead. The resultant models, denoted as MobileLLM-LS, demonstrate a further accuracy enhancement of 0.7%/0.8% than MobileLLM 125M/350M. Moreover, MobileLLM model family shows significant improvements compared to previous sub-billion models on chat benchmarks, and demonstrates close correctness to LLaMA-v2 7B in API calling tasks, highlighting the capability of small models for common on-device use cases.
6/28/2024
LLM-QBench: A Benchmark Towards the Best Practice for Post-training Quantization of Large Language Models
Ruihao Gong, Yang Yong, Shiqiao Gu, Yushi Huang, Yunchen Zhang, Xianglong Liu, Dacheng Tao
0
0
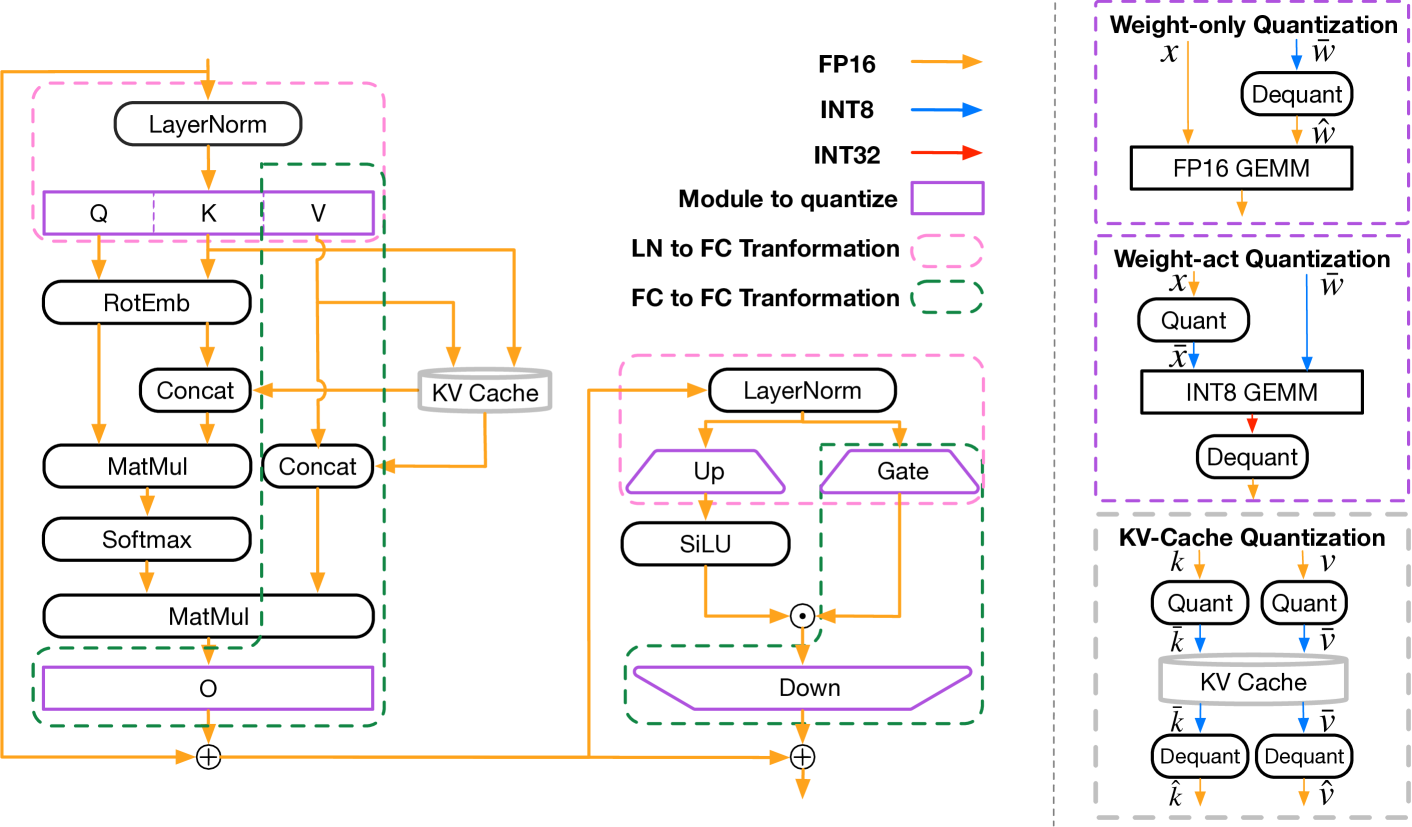
Recent advancements in large language models (LLMs) are propelling us toward artificial general intelligence, thanks to their remarkable emergent abilities and reasoning capabilities. However, the substantial computational and memory requirements of LLMs limit their widespread adoption. Quan- tization, a key compression technique, offers a viable solution to mitigate these demands by compressing and accelerating LLMs, albeit with poten- tial risks to model accuracy. Numerous studies have aimed to minimize the accuracy loss associated with quantization. However, the quantization configurations in these studies vary and may not be optimized for hard- ware compatibility. In this paper, we focus on identifying the most effective practices for quantizing LLMs, with the goal of balancing performance with computational efficiency. For a fair analysis, we develop a quantization toolkit LLMC, and design four crucial principles considering the inference efficiency, quantized accuracy, calibration cost, and modularization. By benchmarking on various models and datasets with over 500 experiments, three takeaways corresponding to calibration data, quantization algorithm, and quantization schemes are derived. Finally, a best practice of LLM PTQ pipeline is constructed. All the benchmark results and the toolkit can be found at https://github.com/ModelTC/llmc.
5/13/2024
💬
On the Compressibility of Quantized Large Language Models
Yu Mao, Weilan Wang, Hongchao Du, Nan Guan, Chun Jason Xue
0
0
Deploying Large Language Models (LLMs) on edge or mobile devices offers significant benefits, such as enhanced data privacy and real-time processing capabilities. However, it also faces critical challenges due to the substantial memory requirement of LLMs. Quantization is an effective way of reducing the model size while maintaining good performance. However, even after quantization, LLMs may still be too big to fit entirely into the limited memory of edge or mobile devices and have to be partially loaded from the storage to complete the inference. In this case, the I/O latency of model loading becomes the bottleneck of the LLM inference latency. In this work, we take a preliminary step of studying applying data compression techniques to reduce data movement and thus speed up the inference of quantized LLM on memory-constrained devices. In particular, we discussed the compressibility of quantized LLMs, the trade-off between the compressibility and performance of quantized LLMs, and opportunities to optimize both of them jointly.
5/7/2024
Evaluating the Generalization Ability of Quantized LLMs: Benchmark, Analysis, and Toolbox
Yijun Liu, Yuan Meng, Fang Wu, Shenhao Peng, Hang Yao, Chaoyu Guan, Chen Tang, Xinzhu Ma, Zhi Wang, Wenwu Zhu
0
0
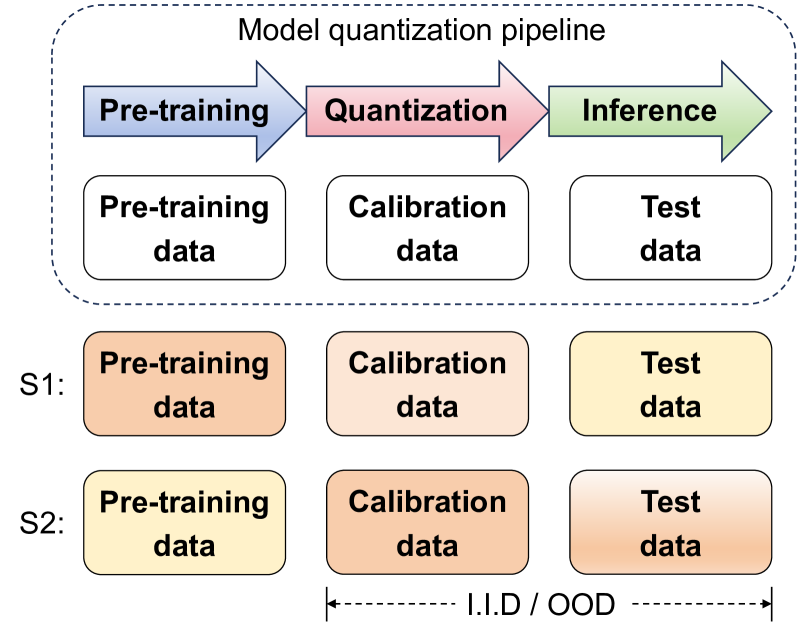
Large language models (LLMs) have exhibited exciting progress in multiple scenarios, while the huge computational demands hinder their deployments in lots of real-world applications. As an effective means to reduce memory footprint and inference cost, quantization also faces challenges in performance degradation at low bit-widths. Understanding the impact of quantization on LLM capabilities, especially the generalization ability, is crucial. However, the community's main focus remains on the algorithms and models of quantization, with insufficient attention given to whether the quantized models can retain the strong generalization abilities of LLMs. In this work, we fill this gap by providing a comprehensive benchmark suite for this research topic, including an evaluation system, detailed analyses, and a general toolbox. Specifically, based on the dominant pipeline in LLM quantization, we primarily explore the impact of calibration data distribution on the generalization of quantized LLMs and conduct the benchmark using more than 40 datasets within two main scenarios. Based on this benchmark, we conduct extensive experiments with two well-known LLMs (English and Chinese) and four quantization algorithms to investigate this topic in-depth, yielding several counter-intuitive and valuable findings, e.g., models quantized using a calibration set with the same distribution as the test data are not necessarily optimal. Besides, to facilitate future research, we also release a modular-designed toolbox, which decouples the overall pipeline into several separate components, e.g., base LLM module, dataset module, quantizer module, etc. and allows subsequent researchers to easily assemble their methods through a simple configuration. Our benchmark suite is publicly available at https://github.com/TsingmaoAI/MI-optimize
6/21/2024