MERT: Acoustic Music Understanding Model with Large-Scale Self-supervised Training
2306.00107
0
0
🤔
Abstract
Self-supervised learning (SSL) has recently emerged as a promising paradigm for training generalisable models on large-scale data in the fields of vision, text, and speech. Although SSL has been proven effective in speech and audio, its application to music audio has yet to be thoroughly explored. This is partially due to the distinctive challenges associated with modelling musical knowledge, particularly tonal and pitched characteristics of music. To address this research gap, we propose an acoustic Music undERstanding model with large-scale self-supervised Training (MERT), which incorporates teacher models to provide pseudo labels in the masked language modelling (MLM) style acoustic pre-training. In our exploration, we identified an effective combination of teacher models, which outperforms conventional speech and audio approaches in terms of performance. This combination includes an acoustic teacher based on Residual Vector Quantisation - Variational AutoEncoder (RVQ-VAE) and a musical teacher based on the Constant-Q Transform (CQT). Furthermore, we explore a wide range of settings to overcome the instability in acoustic language model pre-training, which allows our designed paradigm to scale from 95M to 330M parameters. Experimental results indicate that our model can generalise and perform well on 14 music understanding tasks and attain state-of-the-art (SOTA) overall scores.
Create account to get full access
Overview
- Self-supervised learning (SSL) has emerged as a promising approach for training generalisable models on large-scale data in fields like vision, text, and speech.
- While SSL has been effective in speech and audio, its application to music audio is still largely unexplored.
- This is partly due to the unique challenges in modeling musical knowledge, particularly tonal and pitched characteristics.
- To address this research gap, the authors propose an acoustic Music undERstanding model with large-scale self-supervised Training (MERT), which incorporates teacher models to provide pseudo labels for masked language modeling (MLM) style pre-training.
Plain English Explanation
The paper explores a new way of training AI models to understand and work with music data. Traditionally, machine learning models have been trained on large datasets of images, text, or speech. This "self-supervised" approach has led to major breakthroughs, allowing models to learn general patterns and perform well on a variety of tasks.
However, applying this same approach to music data has proven challenging. Music has unique properties, like tone and pitch, that are difficult for AI systems to grasp. The authors of this paper propose a new model, called MERT, that tries to overcome these challenges.
The key idea behind MERT is to use "teacher" models to provide guidance during the training process. These teacher models are trained on specific aspects of music, like harmonic structure or rhythmic patterns. By incorporating the knowledge from these teachers, the main MERT model is able to learn a more comprehensive understanding of music.
Through extensive experiments, the authors show that MERT can perform well on a wide range of music understanding tasks, outperforming previous approaches. This suggests that their approach of combining self-supervised learning with specialized music knowledge could be a promising direction for advancing the state of the art in AI-powered music analysis and generation.
Technical Explanation
The paper introduces an acoustic Music undERstanding model with large-scale self-supervised Training (MERT), which aims to address the challenges of applying self-supervised learning (SSL) to music audio data.
MERT incorporates two specialized "teacher" models to provide pseudo-labels during the masked language modeling (MLM) style pre-training:
- An acoustic teacher based on Residual Vector Quantisation - Variational AutoEncoder (RVQ-VAE) [https://aimodels.fyi/papers/arxiv/experimental-comparison-multi-view-self-supervised-methods], which captures general acoustic features.
- A musical teacher based on the Constant-Q Transform (CQT) [https://aimodels.fyi/papers/arxiv/mart-learning-hierarchical-music-audio-representations-part], which focuses on the tonal and pitched characteristics of music.
The authors explore a wide range of settings to overcome the instability often encountered in acoustic language model pre-training, allowing the MERT model to scale from 95M to 330M parameters.
Experimental results show that MERT can generalize and achieve state-of-the-art performance on 14 diverse music understanding tasks, including [https://aimodels.fyi/papers/arxiv/content-based-controls-music-large-language-modeling], [https://aimodels.fyi/papers/arxiv/mupt-generative-symbolic-music-pretrained-transformer], and [https://aimodels.fyi/papers/arxiv/bert-like-pre-training-symbolic-piano-music].
Critical Analysis
The paper presents a well-designed and thorough investigation into applying self-supervised learning to the domain of music audio. The authors' approach of leveraging specialized teacher models to provide guidance during pre-training is a clever and potentially impactful idea.
However, the paper does not delve into the potential limitations or caveats of the MERT model. For example, it would be interesting to understand how the performance of MERT might scale with the size and diversity of the pre-training data, or how it might handle less common or more complex musical genres and styles.
Additionally, the paper could have discussed the computational and resource requirements of the MERT model, as well as any potential challenges in deploying such a large-scale model in real-world applications.
Overall, the research is a significant contribution to the field of music AI, and the authors have demonstrated the effectiveness of their approach. Further exploration of the model's limitations and potential areas for improvement would help strengthen the work and provide a more comprehensive understanding of its capabilities and constraints.
Conclusion
The paper presents a novel self-supervised learning approach, called MERT, for modeling music audio data. By incorporating specialized teacher models to provide guidance during pre-training, the authors have shown that MERT can outperform previous methods and achieve state-of-the-art performance on a wide range of music understanding tasks.
This research represents an important step forward in applying advanced machine learning techniques to the field of music AI, paving the way for more intelligent and versatile systems that can better understand and engage with musical data. The insights and techniques developed in this work may also have broader implications for other domains where self-supervised learning has been challenging to apply effectively.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
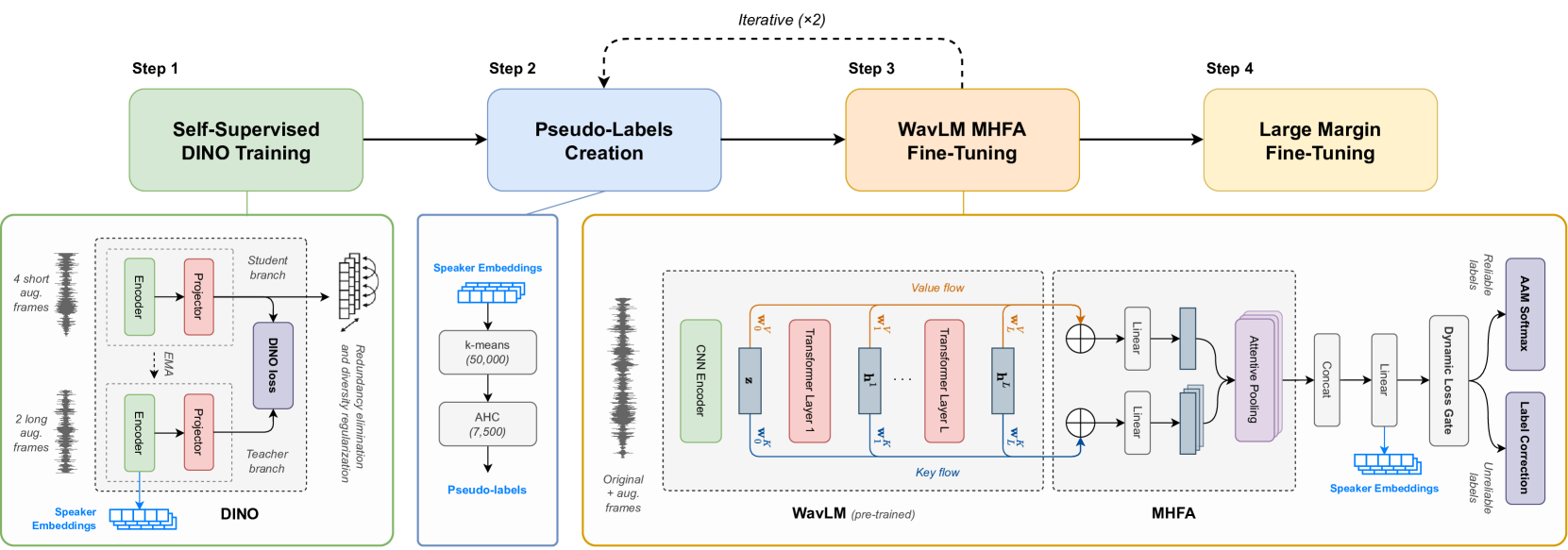
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
0
0
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
6/5/2024

Scaling up masked audio encoder learning for general audio classification
Heinrich Dinkel, Zhiyong Yan, Yongqing Wang, Junbo Zhang, Yujun Wang, Bin Wang
0
0
Despite progress in audio classification, a generalization gap remains between speech and other sound domains, such as environmental sounds and music. Models trained for speech tasks often fail to perform well on environmental or musical audio tasks, and vice versa. While self-supervised (SSL) audio representations offer an alternative, there has been limited exploration of scaling both model and dataset sizes for SSL-based general audio classification. We introduce Dasheng, a simple SSL audio encoder, based on the efficient masked autoencoder framework. Trained with 1.2 billion parameters on 272,356 hours of diverse audio, Dasheng obtains significant performance gains on the HEAR benchmark. It outperforms previous works on CREMA-D, LibriCount, Speech Commands, VoxLingua, and competes well in music and environment classification. Dasheng features inherently contain rich speech, music, and environmental information, as shown in nearest-neighbor classification experiments. Code is available https://github.com/richermans/dasheng/.
6/14/2024

An Experimental Comparison Of Multi-view Self-supervised Methods For Music Tagging
Gabriel Meseguer-Brocal, Dorian Desblancs, Romain Hennequin
0
0
Self-supervised learning has emerged as a powerful way to pre-train generalizable machine learning models on large amounts of unlabeled data. It is particularly compelling in the music domain, where obtaining labeled data is time-consuming, error-prone, and ambiguous. During the self-supervised process, models are trained on pretext tasks, with the primary objective of acquiring robust and informative features that can later be fine-tuned for specific downstream tasks. The choice of the pretext task is critical as it guides the model to shape the feature space with meaningful constraints for information encoding. In the context of music, most works have relied on contrastive learning or masking techniques. In this study, we expand the scope of pretext tasks applied to music by investigating and comparing the performance of new self-supervised methods for music tagging. We open-source a simple ResNet model trained on a diverse catalog of millions of tracks. Our results demonstrate that, although most of these pre-training methods result in similar downstream results, contrastive learning consistently results in better downstream performance compared to other self-supervised pre-training methods. This holds true in a limited-data downstream context.
4/16/2024
🛸
AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining
Haohe Liu, Yi Yuan, Xubo Liu, Xinhao Mei, Qiuqiang Kong, Qiao Tian, Yuping Wang, Wenwu Wang, Yuxuan Wang, Mark D. Plumbley
0
0
Although audio generation shares commonalities across different types of audio, such as speech, music, and sound effects, designing models for each type requires careful consideration of specific objectives and biases that can significantly differ from those of other types. To bring us closer to a unified perspective of audio generation, this paper proposes a framework that utilizes the same learning method for speech, music, and sound effect generation. Our framework introduces a general representation of audio, called language of audio (LOA). Any audio can be translated into LOA based on AudioMAE, a self-supervised pre-trained representation learning model. In the generation process, we translate any modalities into LOA by using a GPT-2 model, and we perform self-supervised audio generation learning with a latent diffusion model conditioned on LOA. The proposed framework naturally brings advantages such as in-context learning abilities and reusable self-supervised pretrained AudioMAE and latent diffusion models. Experiments on the major benchmarks of text-to-audio, text-to-music, and text-to-speech demonstrate state-of-the-art or competitive performance against previous approaches. Our code, pretrained model, and demo are available at https://audioldm.github.io/audioldm2.
5/14/2024