MESEN: Exploit Multimodal Data to Design Unimodal Human Activity Recognition with Few Labels
2404.01958
0
0
Abstract
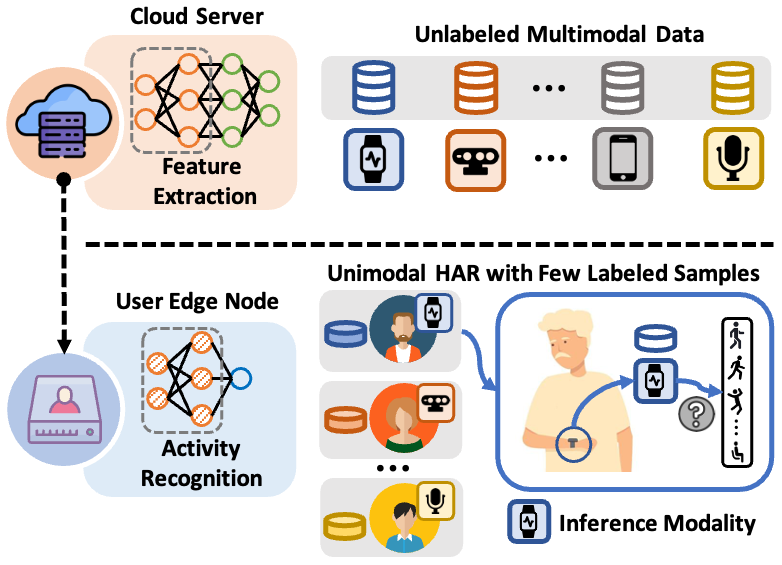
Human activity recognition (HAR) will be an essential function of various emerging applications. However, HAR typically encounters challenges related to modality limitations and label scarcity, leading to an application gap between current solutions and real-world requirements. In this work, we propose MESEN, a multimodal-empowered unimodal sensing framework, to utilize unlabeled multimodal data available during the HAR model design phase for unimodal HAR enhancement during the deployment phase. From a study on the impact of supervised multimodal fusion on unimodal feature extraction, MESEN is designed to feature a multi-task mechanism during the multimodal-aided pre-training stage. With the proposed mechanism integrating cross-modal feature contrastive learning and multimodal pseudo-classification aligning, MESEN exploits unlabeled multimodal data to extract effective unimodal features for each modality. Subsequently, MESEN can adapt to downstream unimodal HAR with only a few labeled samples. Extensive experiments on eight public multimodal datasets demonstrate that MESEN achieves significant performance improvements over state-of-the-art baselines in enhancing unimodal HAR by exploiting multimodal data.
Create account to get full access
Overview
- This paper proposes a new approach called MESEN for human activity recognition using limited labeled data.
- MESEN exploits multimodal sensor data to learn a unimodal model that can accurately recognize human activities with few labeled examples.
- The researchers use self-supervised contrastive learning to leverage the rich information in multimodal sensor data and improve performance on unimodal activity recognition.
Plain English Explanation
The paper focuses on the challenge of human activity recognition - using sensors to automatically detect and classify the physical activities people are doing, like walking, sitting, or exercising. This is an important task with applications in healthcare, fitness tracking, and smart home automation.
Traditionally, training activity recognition models requires a large amount of labeled sensor data, where human annotators have carefully categorized the activities in the data. However, collecting and labeling this data is time-consuming and expensive.
The researchers behind MESEN propose a clever solution to this problem. Rather than relying solely on the limited labeled data, they leverage additional "multimodal" sensor data that captures the activity from multiple perspectives, like video, audio, and motion sensors. By learning to find patterns across this richer multimodal data in a self-supervised way, the model can extract useful features that improve its performance on the final unimodal activity recognition task, even with very few labeled examples.
The key idea is that the multimodal data contains a lot of inherent structure and redundancy that can be exploited to learn powerful representations, without needing extensive manual labeling. The self-supervised contrastive learning approach allows the model to discover these useful patterns on its own, by learning to differentiate between genuine sensor data samples and artificially created "negative" examples.
Overall, this work demonstrates an effective way to get high-performing activity recognition models using limited labeled data, by cleverly harnessing the information encoded in multimodal sensor streams. This could significantly reduce the data collection and annotation burden for real-world activity recognition applications.
Technical Explanation
The MESEN approach consists of two main steps:
-
Multimodal self-supervised pretraining: The researchers first train a multimodal encoder network in a self-supervised contrastive learning setup. This allows the model to learn useful feature representations by distinguishing real multimodal sensor samples from artificially generated "negative" examples.
-
Unimodal fine-tuning: After pretraining on the multimodal data, the model is then fine-tuned on the limited labeled unimodal data for the final activity recognition task. This allows the model to leverage the rich representations learned during pretraining to perform well even with few labeled examples.
The key innovation is this two-stage training process that decouples the learning of general multimodal representations from the final unimodal task. Experiments on public datasets show that MESEN outperforms alternative approaches that directly train on the limited labeled unimodal data.
The researchers also analyze the learned representations and find that MESEN discovers meaningful cross-modal associations, like linking video and motion patterns to specific activities. This multimodal understanding is then effectively transferred to boost unimodal recognition performance.
Critical Analysis
The paper provides a compelling approach to address the data scarcity challenge in human activity recognition. By exploiting multimodal data in a self-supervised manner, MESEN is able to learn powerful representations that improve performance on the target unimodal task.
However, the researchers acknowledge that the effectiveness of MESEN may depend on the availability and quality of the multimodal sensor data. In real-world scenarios, the sensor modalities and their coverage may be more limited, which could impact the performance gains.
Additionally, the paper does not extensively explore the generalization of MESEN to new datasets or activity types. Further research is needed to understand the broader applicability and limitations of the approach.
Nevertheless, this work represents an important step forward in addressing the data challenges in human activity recognition. The insights on leveraging multimodal self-supervised learning could inspire further innovations in this domain and beyond.
Conclusion
This paper introduces MESEN, a novel approach for human activity recognition that efficiently utilizes multimodal sensor data to improve performance on unimodal tasks with limited labeled data. By decoupling the learning of general multimodal representations from the final activity recognition objective, MESEN demonstrates significant advantages over traditional supervised learning methods.
The key contribution is the effective use of self-supervised contrastive learning to extract rich feature representations from the multimodal sensor data, which can then be effectively transferred to boost the accuracy of the unimodal activity recognition model. This could greatly reduce the data collection and annotation burden for real-world deployment of activity recognition systems.
While the approach has some limitations in terms of the dependence on available multimodal data, the insights from this work open up new directions for further research in leveraging multimodal sensing and self-supervised learning for efficient human activity recognition and other related tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
MuJo: Multimodal Joint Feature Space Learning for Human Activity Recognition
Stefan Gerd Fritsch, Cennet Oguz, Vitor Fortes Rey, Lala Ray, Maximilian Kiefer-Emmanouilidis, Paul Lukowicz
0
0
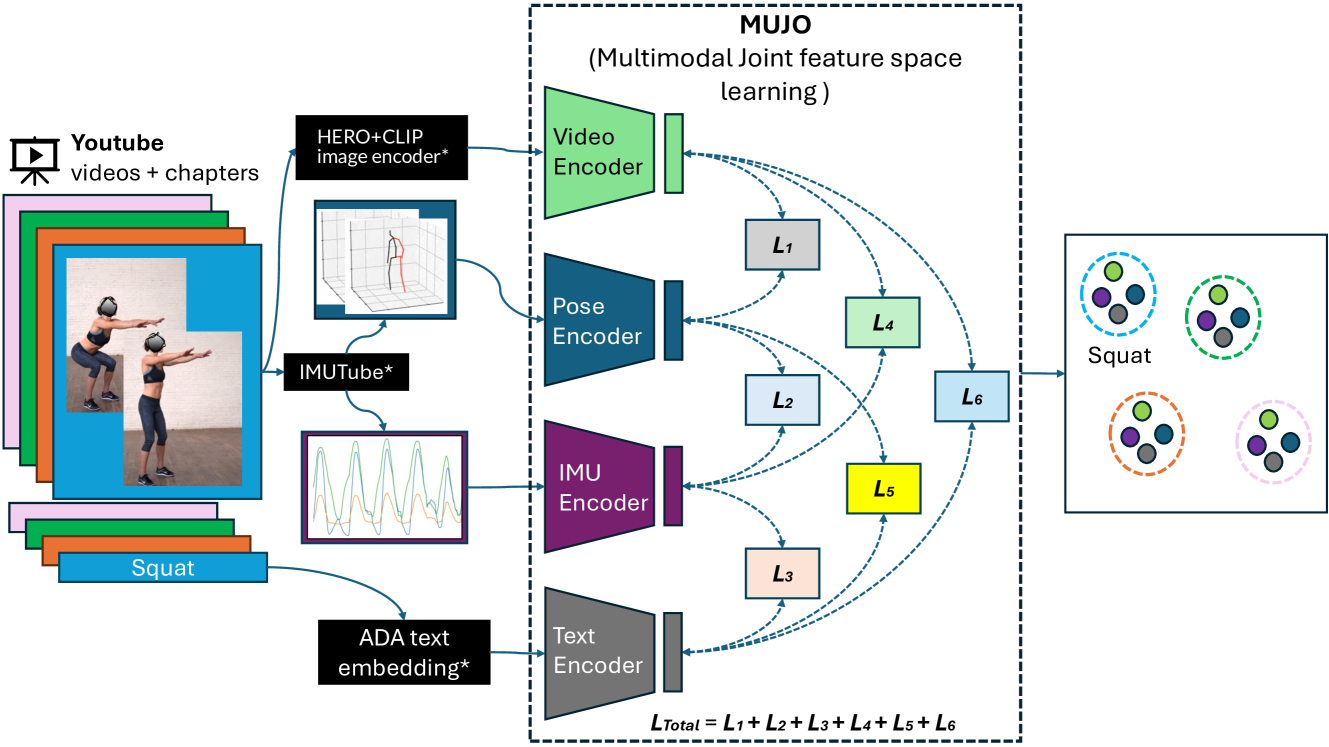
Human Activity Recognition is a longstanding problem in AI with applications in a broad range of areas: from healthcare, sports and fitness, security, and human computer interaction to robotics. The performance of HAR in real-world settings is strongly dependent on the type and quality of the input signal that can be acquired. Given an unobstructed, high-quality camera view of a scene, computer vision systems, in particular in conjunction with foundational models (e.g., CLIP), can today fairly reliably distinguish complex activities. On the other hand, recognition using modalities such as wearable sensors (which are often more broadly available, e.g, in mobile phones and smartwatches) is a more difficult problem, as the signals often contain less information and labeled training data is more difficult to acquire. In this work, we show how we can improve HAR performance across different modalities using multimodal contrastive pretraining. Our approach MuJo (Multimodal Joint Feature Space Learning), learns a multimodal joint feature space with video, language, pose, and IMU sensor data. The proposed approach combines contrastive and multitask learning methods and analyzes different multitasking strategies for learning a compact shared representation. A large dataset with parallel video, language, pose, and sensor data points is also introduced to support the research, along with an analysis of the robustness of the multimodal joint space for modal-incomplete and low-resource data. On the MM-Fit dataset, our model achieves an impressive Macro F1-Score of up to 0.992 with only 2% of the train data and 0.999 when using all available training data for classification tasks. Moreover, in the scenario where the MM-Fit dataset is unseen, we demonstrate a generalization performance of up to 0.638.
6/7/2024

U3M: Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation
Bingyu Li, Da Zhang, Zhiyuan Zhao, Junyu Gao, Xuelong Li
0
0
Multimodal semantic segmentation is a pivotal component of computer vision and typically surpasses unimodal methods by utilizing rich information set from various sources.Current models frequently adopt modality-specific frameworks that inherently biases toward certain modalities. Although these biases might be advantageous in specific situations, they generally limit the adaptability of the models across different multimodal contexts, thereby potentially impairing performance. To address this issue, we leverage the inherent capabilities of the model itself to discover the optimal equilibrium in multimodal fusion and introduce U3M: An Unbiased Multiscale Modal Fusion Model for Multimodal Semantic Segmentation. Specifically, this method involves an unbiased integration of multimodal visual data. Additionally, we employ feature fusion at multiple scales to ensure the effective extraction and integration of both global and local features. Experimental results demonstrate that our approach achieves superior performance across multiple datasets, verifing its efficacy in enhancing the robustness and versatility of semantic segmentation in diverse settings. Our code is available at U3M-multimodal-semantic-segmentation.
5/27/2024
👁️
Wearable-based behaviour interpolation for semi-supervised human activity recognition
Haoran Duan, Shidong Wang, Varun Ojha, Shizheng Wang, Yawen Huang, Yang Long, Rajiv Ranjan, Yefeng Zheng
0
0
While traditional feature engineering for Human Activity Recognition (HAR) involves a trial-anderror process, deep learning has emerged as a preferred method for high-level representations of sensor-based human activities. However, most deep learning-based HAR requires a large amount of labelled data and extracting HAR features from unlabelled data for effective deep learning training remains challenging. We, therefore, introduce a deep semi-supervised HAR approach, MixHAR, which concurrently uses labelled and unlabelled activities. Our MixHAR employs a linear interpolation mechanism to blend labelled and unlabelled activities while addressing both inter- and intra-activity variability. A unique challenge identified is the activityintrusion problem during mixing, for which we propose a mixing calibration mechanism to mitigate it in the feature embedding space. Additionally, we rigorously explored and evaluated the five conventional/popular deep semi-supervised technologies on HAR, acting as the benchmark of deep semi-supervised HAR. Our results demonstrate that MixHAR significantly improves performance, underscoring the potential of deep semi-supervised techniques in HAR.
5/28/2024
🤷
Unsupervised Statistical Feature-Guided Diffusion Model for Sensor-based Human Activity Recognition
Si Zuo, Vitor Fortes Rey, Sungho Suh, Stephan Sigg, Paul Lukowicz
0
0
Human activity recognition (HAR) from on-body sensors is a core functionality in many AI applications: from personal health, through sports and wellness to Industry 4.0. A key problem holding up progress in wearable sensor-based HAR, compared to other ML areas, such as computer vision, is the unavailability of diverse and labeled training data. Particularly, while there are innumerable annotated images available in online repositories, freely available sensor data is sparse and mostly unlabeled. We propose an unsupervised statistical feature-guided diffusion model specifically optimized for wearable sensor-based human activity recognition with devices such as inertial measurement unit (IMU) sensors. The method generates synthetic labeled time-series sensor data without relying on annotated training data. Thereby, it addresses the scarcity and annotation difficulties associated with real-world sensor data. By conditioning the diffusion model on statistical information such as mean, standard deviation, Z-score, and skewness, we generate diverse and representative synthetic sensor data. We conducted experiments on public human activity recognition datasets and compared the method to conventional oversampling and state-of-the-art generative adversarial network methods. Experimental results demonstrate that this can improve the performance of human activity recognition and outperform existing techniques.
5/21/2024