MuJo: Multimodal Joint Feature Space Learning for Human Activity Recognition
2406.03857
0
0
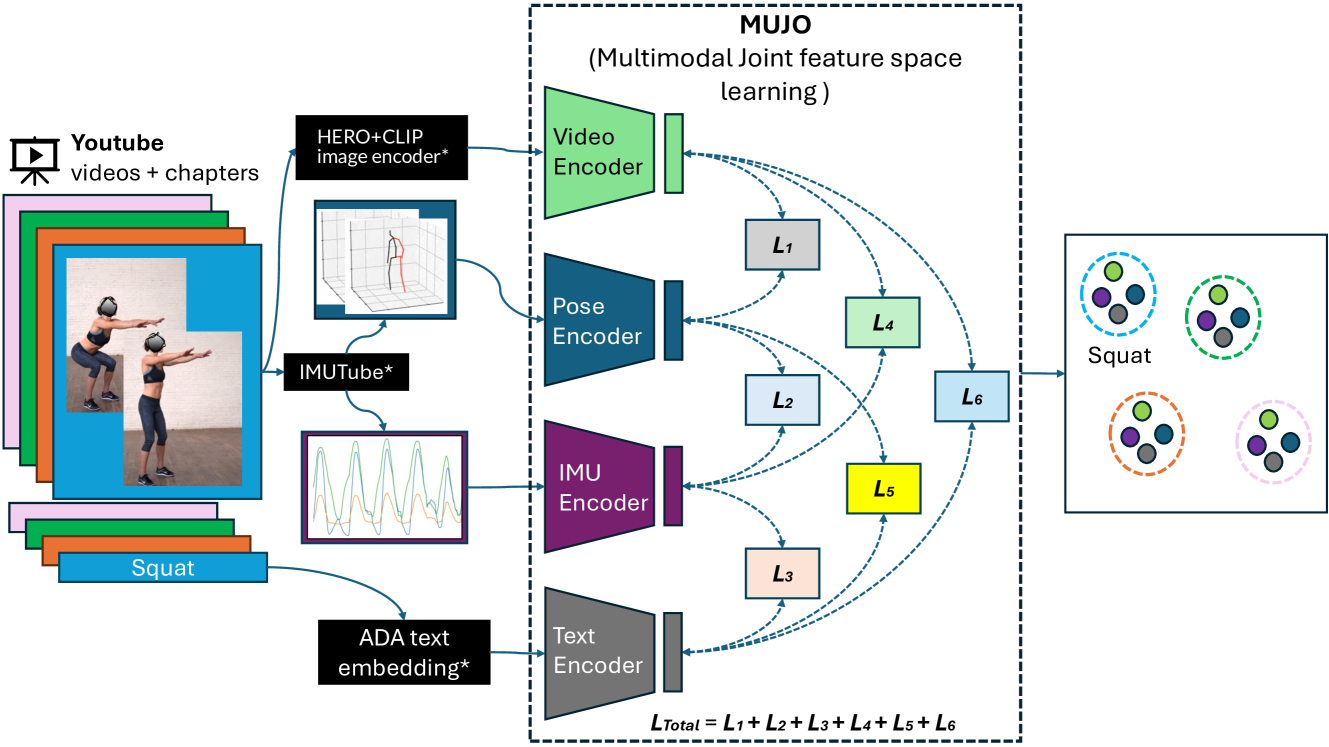
Abstract
Human Activity Recognition is a longstanding problem in AI with applications in a broad range of areas: from healthcare, sports and fitness, security, and human computer interaction to robotics. The performance of HAR in real-world settings is strongly dependent on the type and quality of the input signal that can be acquired. Given an unobstructed, high-quality camera view of a scene, computer vision systems, in particular in conjunction with foundational models (e.g., CLIP), can today fairly reliably distinguish complex activities. On the other hand, recognition using modalities such as wearable sensors (which are often more broadly available, e.g, in mobile phones and smartwatches) is a more difficult problem, as the signals often contain less information and labeled training data is more difficult to acquire. In this work, we show how we can improve HAR performance across different modalities using multimodal contrastive pretraining. Our approach MuJo (Multimodal Joint Feature Space Learning), learns a multimodal joint feature space with video, language, pose, and IMU sensor data. The proposed approach combines contrastive and multitask learning methods and analyzes different multitasking strategies for learning a compact shared representation. A large dataset with parallel video, language, pose, and sensor data points is also introduced to support the research, along with an analysis of the robustness of the multimodal joint space for modal-incomplete and low-resource data. On the MM-Fit dataset, our model achieves an impressive Macro F1-Score of up to 0.992 with only 2% of the train data and 0.999 when using all available training data for classification tasks. Moreover, in the scenario where the MM-Fit dataset is unseen, we demonstrate a generalization performance of up to 0.638.
Create account to get full access
Overview
- Introduces a novel multimodal approach called MuJo for human activity recognition (HAR) using sensor data
- Combines visual and inertial sensor data to learn a joint feature space that captures the complementary information from different modalities
- Demonstrates improved performance over unimodal and other multimodal approaches on multiple HAR datasets
Plain English Explanation
The paper presents a new method called MuJo for recognizing human activities using sensor data from various sources, such as cameras and motion sensors. Current methods often rely on a single type of sensor data, which can be limiting. MuJo combines visual data, like images or videos, with inertial data, like measurements from accelerometers and gyroscopes, to learn a joint feature space that captures the complementary information from these different modalities.
By learning this joint feature space, MuJo is able to achieve better performance on human activity recognition tasks compared to using just one type of sensor data or other multimodal approaches. The key idea is that the combination of visual and inertial information provides a richer and more comprehensive representation of human activities, allowing the model to better distinguish between different activities.
The researchers explored this approach on several human activity recognition datasets and found that MuJo outperformed other methods, including those that use only a single modality or simpler ways of combining multimodal data. This suggests that the joint feature space learning technique is a promising direction for advancing the state-of-the-art in human activity recognition.
Technical Explanation
The MuJo method learns a shared latent representation that captures the complementary information from visual and inertial sensor data. It consists of two main components:
-
Multimodal Encoder: This module takes in the visual and inertial data and learns a joint feature space representation through a series of convolutional and fully-connected layers.
-
Multimodal Classifier: The joint feature space is then used as input to a classification module, which predicts the human activity performed.
The key innovation is the joint feature space learning, which allows the model to discover the underlying connections between the visual and inertial modalities. This is in contrast to simpler multimodal approaches that concatenate or fuse the features from each modality separately.
The authors evaluate MuJo on several public HAR datasets, including OPPORTUNITY and PAMAP2. They demonstrate that MuJo outperforms unimodal baselines as well as other multimodal techniques, such as early fusion and late fusion. This highlights the benefits of the joint feature space learning approach for effectively leveraging the complementary information in multimodal sensor data.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the MuJo method, considering various baselines and datasets. However, there are a few potential limitations and areas for further research:
-
Dataset Diversity: The experiments are primarily conducted on two common HAR datasets, OPPORTUNITY and PAMAP2. It would be valuable to test MuJo on a wider range of datasets, potentially with more diverse sensor modalities or activity types.
-
Model Complexity: The MuJo architecture consists of multiple encoders and a classifier, which may introduce additional training complexity and computational requirements compared to simpler multimodal fusion approaches. The authors could explore ways to simplify the model while maintaining the performance gains.
-
Real-world Deployment: The paper focuses on evaluating MuJo in controlled, lab-based settings. Further research is needed to assess the method's performance and practical feasibility in real-world scenarios, where sensor data may be noisier or have missing modalities.
Overall, the MuJo approach demonstrates the value of learning a joint feature space for multimodal HAR, and the paper provides a strong technical foundation for future research in this area.
Conclusion
The MuJo method presented in this paper offers a novel and effective approach for human activity recognition using multimodal sensor data. By learning a joint feature space that captures the complementary information from visual and inertial modalities, MuJo outperforms unimodal and other multimodal techniques on several benchmark HAR datasets.
This work highlights the importance of developing advanced multimodal learning methods to fully leverage the rich and diverse sensor data available for human activity recognition. As wearable and ubiquitous computing continue to advance, techniques like MuJo will become increasingly valuable for powering robust and accurate activity recognition systems with real-world applications in areas such as healthcare, smart homes, and human-computer interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
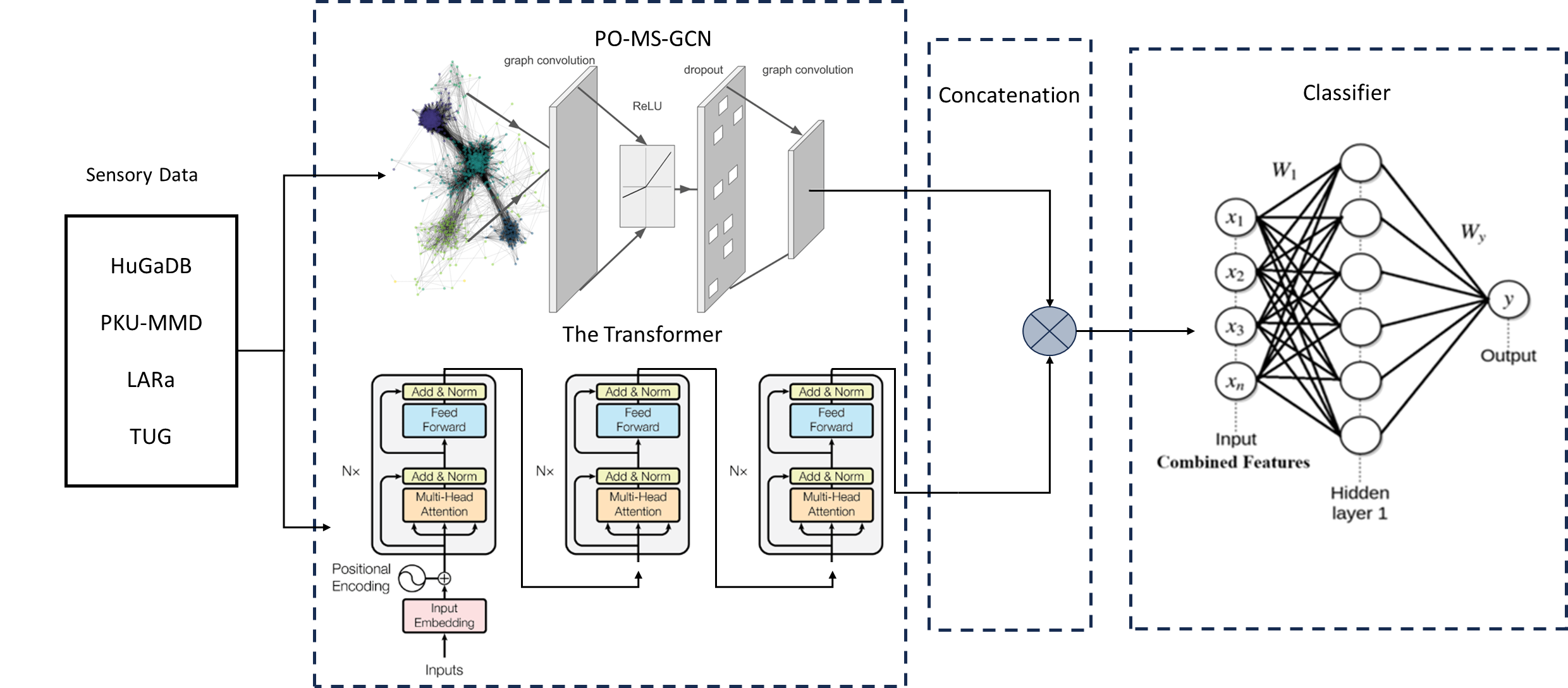
Feature Fusion for Human Activity Recognition using Parameter-Optimized Multi-Stage Graph Convolutional Network and Transformer Models
Mohammad Belal (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Taimur Hassan (Abu Dhabi University, Abu Dhabi, United Arab Emirates), Abdelfatah Ahmed (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Ahmad Aljarah (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Nael Alsheikh (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates), Irfan Hussain (Khalifa University of Science and Technology, Abu Dhabi, United Arab Emirates)
0
0
Human activity recognition (HAR) is a crucial area of research that involves understanding human movements using computer and machine vision technology. Deep learning has emerged as a powerful tool for this task, with models such as Convolutional Neural Networks (CNNs) and Transformers being employed to capture various aspects of human motion. One of the key contributions of this work is the demonstration of the effectiveness of feature fusion in improving HAR accuracy by capturing spatial and temporal features, which has important implications for the development of more accurate and robust activity recognition systems. The study uses sensory data from HuGaDB, PKU-MMD, LARa, and TUG datasets. Two model, the PO-MS-GCN and a Transformer were trained and evaluated, with PO-MS-GCN outperforming state-of-the-art models. HuGaDB and TUG achieved high accuracies and f1-scores, while LARa and PKU-MMD had lower scores. Feature fusion improved results across datasets.
6/26/2024
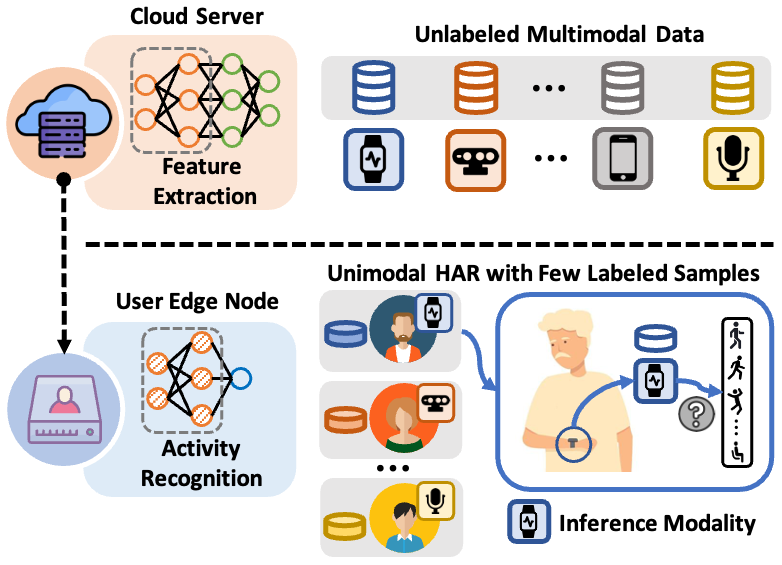
MESEN: Exploit Multimodal Data to Design Unimodal Human Activity Recognition with Few Labels
Lilin Xu, Chaojie Gu, Rui Tan, Shibo He, Jiming Chen
0
0
Human activity recognition (HAR) will be an essential function of various emerging applications. However, HAR typically encounters challenges related to modality limitations and label scarcity, leading to an application gap between current solutions and real-world requirements. In this work, we propose MESEN, a multimodal-empowered unimodal sensing framework, to utilize unlabeled multimodal data available during the HAR model design phase for unimodal HAR enhancement during the deployment phase. From a study on the impact of supervised multimodal fusion on unimodal feature extraction, MESEN is designed to feature a multi-task mechanism during the multimodal-aided pre-training stage. With the proposed mechanism integrating cross-modal feature contrastive learning and multimodal pseudo-classification aligning, MESEN exploits unlabeled multimodal data to extract effective unimodal features for each modality. Subsequently, MESEN can adapt to downstream unimodal HAR with only a few labeled samples. Extensive experiments on eight public multimodal datasets demonstrate that MESEN achieves significant performance improvements over state-of-the-art baselines in enhancing unimodal HAR by exploiting multimodal data.
4/3/2024
👁️
Human Activity Recognition from Wearable Sensor Data Using Self-Attention
Saif Mahmud, M Tanjid Hasan Tonmoy, Kishor Kumar Bhaumik, A K M Mahbubur Rahman, M Ashraful Amin, Mohammad Shoyaib, Muhammad Asif Hossain Khan, Amin Ahsan Ali
0
0
Human Activity Recognition from body-worn sensor data poses an inherent challenge in capturing spatial and temporal dependencies of time-series signals. In this regard, the existing recurrent or convolutional or their hybrid models for activity recognition struggle to capture spatio-temporal context from the feature space of sensor reading sequence. To address this complex problem, we propose a self-attention based neural network model that foregoes recurrent architectures and utilizes different types of attention mechanisms to generate higher dimensional feature representation used for classification. We performed extensive experiments on four popular publicly available HAR datasets: PAMAP2, Opportunity, Skoda and USC-HAD. Our model achieve significant performance improvement over recent state-of-the-art models in both benchmark test subjects and Leave-one-subject-out evaluation. We also observe that the sensor attention maps produced by our model is able capture the importance of the modality and placement of the sensors in predicting the different activity classes.
4/23/2024
🤷
Unsupervised Statistical Feature-Guided Diffusion Model for Sensor-based Human Activity Recognition
Si Zuo, Vitor Fortes Rey, Sungho Suh, Stephan Sigg, Paul Lukowicz
0
0
Human activity recognition (HAR) from on-body sensors is a core functionality in many AI applications: from personal health, through sports and wellness to Industry 4.0. A key problem holding up progress in wearable sensor-based HAR, compared to other ML areas, such as computer vision, is the unavailability of diverse and labeled training data. Particularly, while there are innumerable annotated images available in online repositories, freely available sensor data is sparse and mostly unlabeled. We propose an unsupervised statistical feature-guided diffusion model specifically optimized for wearable sensor-based human activity recognition with devices such as inertial measurement unit (IMU) sensors. The method generates synthetic labeled time-series sensor data without relying on annotated training data. Thereby, it addresses the scarcity and annotation difficulties associated with real-world sensor data. By conditioning the diffusion model on statistical information such as mean, standard deviation, Z-score, and skewness, we generate diverse and representative synthetic sensor data. We conducted experiments on public human activity recognition datasets and compared the method to conventional oversampling and state-of-the-art generative adversarial network methods. Experimental results demonstrate that this can improve the performance of human activity recognition and outperform existing techniques.
5/21/2024