MeshFeat: Multi-Resolution Features for Neural Fields on Meshes

0

Sign in to get full access
Overview
This paper introduces MeshFeat, a new method for extracting multi-resolution features from 3D mesh data for use in neural network models. The key ideas are:
- Extracting features at multiple scales to capture both local and global information
- Using a graph-based approach to efficiently compute features on irregularly shaped meshes
- Demonstrating the benefits of MeshFeat on several 3D mesh tasks like classification and reconstruction
Plain English Explanation
Imagine you're trying to understand a 3D shape, like a statue or a building. You can look at it up close and see the fine details, like the textures and patterns. But you can also step back and look at the overall shape and structure. Both the fine details and the big picture are important for fully comprehending the object.
Similarly, when working with 3D mesh data in machine learning models, it's valuable to extract features at multiple resolutions. The MeshXL paper showed how to represent 3D shapes as "neural fields", but the MeshFeat method goes further by capturing information at different scales.
By using a graph-based approach, MeshFeat can efficiently compute these multi-resolution features even on irregularly shaped 3D meshes. This allows the model to see both the small-scale details and the large-scale structure, leading to better performance on tasks like classification and reconstruction.
The key insight is that different applications may require focusing on different levels of detail. MeshFeat provides a flexible way to extract relevant features at the appropriate scale, rather than being limited to a single, fixed representation.
Technical Explanation
The MeshFeat method first builds a graph representation of the 3D mesh, where each vertex is a node and edges connect neighboring vertices. This graph structure allows efficient computation of features at multiple resolutions using a cascading approach.
At the coarsest level, MeshFeat computes features that capture the overall shape and structure of the 3D object. As it moves to finer levels, it extracts more detailed features that represent the local shape, texture, and other properties. These multi-scale features are then concatenated and used as input to neural network models.
The authors demonstrate the effectiveness of MeshFeat on several 3D mesh tasks, including classification, reconstruction, and shape correspondence. By incorporating information at multiple scales, MeshFeat outperforms methods that use a single fixed feature representation, such as Implicit ARAP or Refine Recursive Field Networks.
Critical Analysis
The MeshFeat paper provides a promising approach for extracting rich, multi-scale features from 3D mesh data. However, the authors acknowledge that the method may be computationally more expensive than simpler feature extraction techniques, especially for very large or complex meshes.
Additionally, the paper does not explore the impact of the specific feature aggregation and concatenation strategies used in MeshFeat. It would be valuable to understand how different choices for these components might affect the performance and generalization of the method.
Further research could also investigate how MeshFeat's multi-resolution features compare to other neural network approaches for handling 3D data, such as Neural NeRF Compression or the Synergistic Integration of Coordinate Networks and Tensorial Features. Understanding the tradeoffs and complementary strengths of these different techniques could lead to more powerful 3D modeling capabilities.
Conclusion
The MeshFeat method presented in this paper offers a novel approach for extracting multi-resolution features from 3D mesh data. By capturing information at multiple scales, MeshFeat can provide more comprehensive and flexible representations for a variety of 3D mesh tasks, outperforming single-resolution feature extraction techniques.
The graph-based approach used in MeshFeat is a key innovation, allowing efficient computation of these multi-scale features even on irregular mesh structures. While the method may have some computational overhead, the improved performance on tasks like classification and reconstruction suggests that MeshFeat is a valuable addition to the toolbox for working with 3D mesh data in machine learning.
As the field of 3D deep learning continues to evolve, techniques like MeshFeat that can effectively leverage the rich information in mesh data will become increasingly important for advancing the state of the art in areas such as 3D shape analysis, content generation, and geometric understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MeshFeat: Multi-Resolution Features for Neural Fields on Meshes
Mihir Mahajan, Florian Hofherr, Daniel Cremers
Parametric feature grid encodings have gained significant attention as an encoding approach for neural fields since they allow for much smaller MLPs, which significantly decreases the inference time of the models. In this work, we propose MeshFeat, a parametric feature encoding tailored to meshes, for which we adapt the idea of multi-resolution feature grids from Euclidean space. We start from the structure provided by the given vertex topology and use a mesh simplification algorithm to construct a multi-resolution feature representation directly on the mesh. The approach allows the usage of small MLPs for neural fields on meshes, and we show a significant speed-up compared to previous representations while maintaining comparable reconstruction quality for texture reconstruction and BRDF representation. Given its intrinsic coupling to the vertices, the method is particularly well-suited for representations on deforming meshes, making it a good fit for object animation.
Read more7/19/2024
0
MDNF: Multi-Diffusion-Nets for Neural Fields on Meshes
Avigail Cohen Rimon, Tal Shnitzer, Mirela Ben Chen
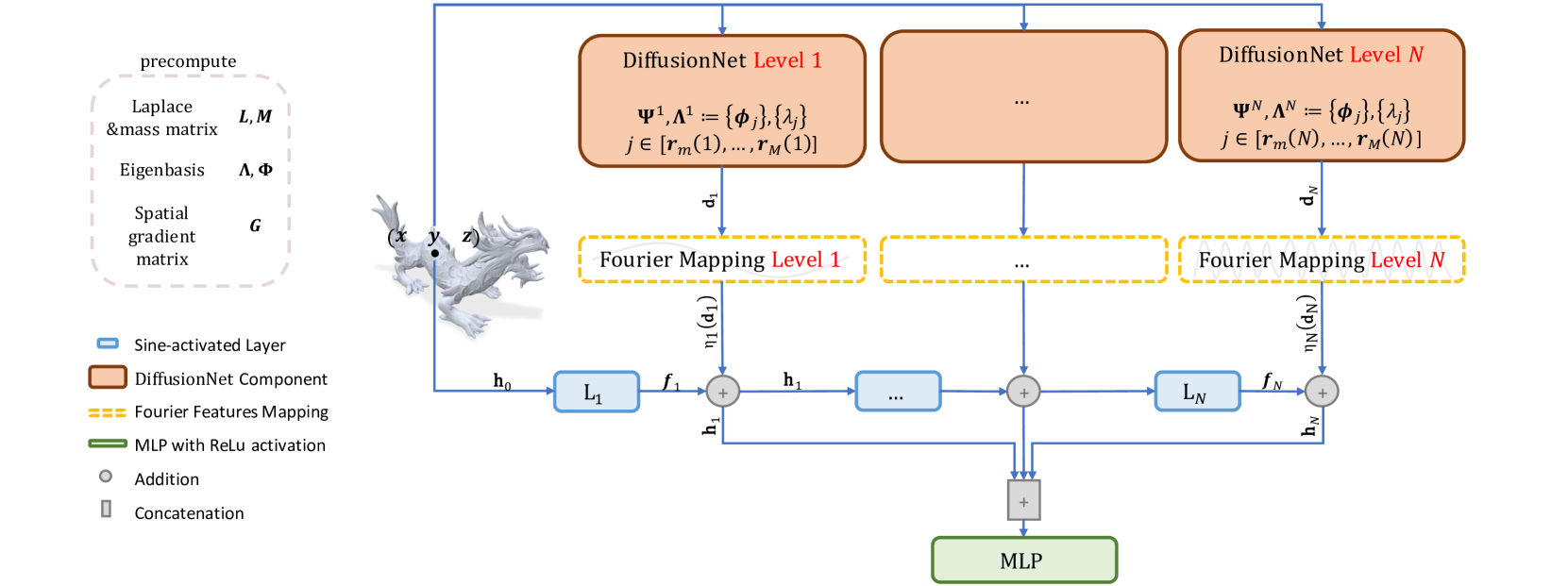
We propose a novel framework for representing neural fields on triangle meshes that is multi-resolution across both spatial and frequency domains. Inspired by the Neural Fourier Filter Bank (NFFB), our architecture decomposes the spatial and frequency domains by associating finer spatial resolution levels with higher frequency bands, while coarser resolutions are mapped to lower frequencies. To achieve geometry-aware spatial decomposition we leverage multiple DiffusionNet components, each associated with a different spatial resolution level. Subsequently, we apply a Fourier feature mapping to encourage finer resolution levels to be associated with higher frequencies. The final signal is composed in a wavelet-inspired manner using a sine-activated MLP, aggregating higher-frequency signals on top of lower-frequency ones. Our architecture attains high accuracy in learning complex neural fields and is robust to discontinuities, exponential scale variations of the target field, and mesh modification. We demonstrate the effectiveness of our approach through its application to diverse neural fields, such as synthetic RGB functions, UV texture coordinates, and vertex normals, illustrating different challenges. To validate our method, we compare its performance against two alternatives, showcasing the advantages of our multi-resolution architecture.
Read more9/6/2024
🧠
0
HYVE: Hybrid Vertex Encoder for Neural Distance Fields
Stefan Rhys Jeske, Jonathan Klein, Dominik L. Michels, Jan Bender
Neural shape representation generally refers to representing 3D geometry using neural networks, e.g., computing a signed distance or occupancy value at a specific spatial position. In this paper we present a neural-network architecture suitable for accurate encoding of 3D shapes in a single forward pass. Our architecture is based on a multi-scale hybrid system incorporating graph-based and voxel-based components, as well as a continuously differentiable decoder. The hybrid system includes a novel way of voxelizing point-based features in neural networks, which we show can be used in combination with oriented point-clouds to obtain smoother and more detailed reconstructions. Furthermore, our network is trained to solve the eikonal equation and only requires knowledge of the zero-level set for training and inference. This means that in contrast to most previous shape encoder architectures, our network is able to output valid signed distance fields without explicit prior knowledge of non-zero distance values or shape occupancy. It also requires only a single forward-pass, instead of the latent-code optimization used in auto-decoder methods. We further propose a modification to the loss function in case that surface normals are not well defined, e.g., in the context of non-watertight surfaces and non-manifold geometry, resulting in an unsigned distance field. Overall, our system can help to reduce the computational overhead of training and evaluating neural distance fields, as well as enabling the application to difficult geometry.
Read more8/22/2024

0
ReFiNe: Recursive Field Networks for Cross-modal Multi-scene Representation
Sergey Zakharov, Katherine Liu, Adrien Gaidon, Rares Ambrus
The common trade-offs of state-of-the-art methods for multi-shape representation (a single model packing multiple objects) involve trading modeling accuracy against memory and storage. We show how to encode multiple shapes represented as continuous neural fields with a higher degree of precision than previously possible and with low memory usage. Key to our approach is a recursive hierarchical formulation that exploits object self-similarity, leading to a highly compressed and efficient shape latent space. Thanks to the recursive formulation, our method supports spatial and global-to-local latent feature fusion without needing to initialize and maintain auxiliary data structures, while still allowing for continuous field queries to enable applications such as raytracing. In experiments on a set of diverse datasets, we provide compelling qualitative results and demonstrate state-of-the-art multi-scene reconstruction and compression results with a single network per dataset.
Read more6/7/2024