Meta-Rewarding Language Models: Self-Improving Alignment with LLM-as-a-Meta-Judge

470

Sign in to get full access
Overview
- The paper explores a novel approach called "meta-rewarding" to improve the alignment of large language models (LLMs) with desired objectives.
- The key idea is to use an LLM as a "meta-judge" to evaluate and provide feedback on the model's own outputs, enabling self-improvement.
- The proposed method aims to address limitations of existing approaches and work towards more capable and aligned AI systems.
Plain English Explanation
The paper introduces a new technique called "meta-rewarding" to help make large language models (LLMs) better aligned with the goals we want them to pursue. The core idea is to use an LLM itself as a kind of "judge" that can evaluate the model's own outputs and provide feedback to help it improve.
Imagine you're training an LLM to write helpful and truthful articles. With meta-rewarding, the model would not only learn from the initial training data, but would also get feedback from an LLM "judge" that assesses whether the articles it generates are actually helpful and truthful. This allows the model to refine and improve its behavior over time, rather than being stuck with whatever it learned from the initial training.
The researchers argue that this approach can address some of the limitations of existing techniques for aligning LLMs, which often rely on predefined reward functions or human oversight. By empowering the model to learn and improve on its own, meta-rewarding aims to create more capable and reliable AI systems that better reflect our values and intentions.
Technical Explanation
The paper proposes a novel "meta-rewarding" framework to improve the alignment of large language models (LLMs) with desired objectives. The key idea is to use an LLM as a "meta-judge" that can evaluate the model's own outputs and provide feedback to enable self-improvement.
The meta-rewarding process works as follows:
- The LLM generates some output, such as a piece of text.
- Another LLM, acting as the "meta-judge," evaluates the quality and alignment of the generated output.
- The meta-judge's evaluation is then used as a reward signal to fine-tune and improve the original LLM.
By iterating this process, the LLM can gradually learn to produce outputs that are more aligned with the meta-judge's preferences, which are intended to reflect the desired objectives.
The researchers argue that this approach has several advantages over existing alignment techniques, such as avoiding the need for predefined reward functions or extensive human oversight. By empowering the LLM to learn and improve on its own, meta-rewarding aims to create more capable and reliable AI systems that better reflect human values and intentions.
Critical Analysis
The meta-rewarding approach proposed in the paper is an interesting and potentially impactful idea for improving the alignment of large language models. By using an LLM as a self-evaluating "meta-judge," the technique aims to address some of the limitations of existing alignment methods, such as the difficulty of specifying comprehensive reward functions or the challenges of extensive human oversight.
However, the paper does not fully explore the potential pitfalls and limitations of this approach. For example, the authors do not discuss how to ensure that the meta-judge itself is properly aligned with the desired objectives, or how to handle potential biases or inconsistencies in the meta-judge's evaluations. Additionally, the proposed framework may be computationally intensive and require significant training resources, which could limit its practical applicability.
Further research is needed to thoroughly investigate the long-term stability and scalability of meta-rewarding, as well as to explore potential failure modes and mitigation strategies. It would also be valuable to see empirical evaluations of the technique on diverse tasks and benchmarks to better understand its strengths, weaknesses, and practical implications.
Conclusion
The paper introduces a novel "meta-rewarding" approach to improving the alignment of large language models with desired objectives. By using an LLM as a self-evaluating "meta-judge," the technique aims to enable models to learn and refine their behavior over time, rather than being limited by their initial training.
While the proposed framework is an interesting and potentially impactful idea, the paper does not fully address the potential challenges and limitations of this approach. Continued research and empirical evaluation will be crucial to understanding the long-term viability and practical applicability of meta-rewarding for creating more capable and aligned AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
470
Meta-Rewarding Language Models: Self-Improving Alignment with LLM-as-a-Meta-Judge
Tianhao Wu, Weizhe Yuan, Olga Golovneva, Jing Xu, Yuandong Tian, Jiantao Jiao, Jason Weston, Sainbayar Sukhbaatar
Large Language Models (LLMs) are rapidly surpassing human knowledge in many domains. While improving these models traditionally relies on costly human data, recent self-rewarding mechanisms (Yuan et al., 2024) have shown that LLMs can improve by judging their own responses instead of relying on human labelers. However, existing methods have primarily focused on improving model responses rather than judgment capabilities, resulting in rapid saturation during iterative training. To address this issue, we introduce a novel Meta-Rewarding step to the self-improvement process, where the model judges its own judgements and uses that feedback to refine its judgment skills. Surprisingly, this unsupervised approach improves the model's ability to judge {em and} follow instructions, as demonstrated by a win rate improvement of Llama-3-8B-Instruct from 22.9% to 39.4% on AlpacaEval 2, and 20.6% to 29.1% on Arena-Hard. These results strongly suggest the potential for self-improving models without human supervision.
Read more7/31/2024

0
Self-Judge: Selective Instruction Following with Alignment Self-Evaluation
Hai Ye, Hwee Tou Ng
Pre-trained large language models (LLMs) can be tailored to adhere to human instructions through instruction tuning. However, due to shifts in the distribution of test-time data, they may not always execute instructions accurately, potentially generating factual errors or misaligned content when acting as chat assistants. To enhance the reliability of LLMs in following instructions, we propose the study of selective instruction following, whereby the system declines to execute instructions if the anticipated response quality is low. We train judge models that can predict numerical quality scores for model responses. To address data scarcity, we introduce Self-J, a novel self-training framework for developing judge models without needing human-annotated quality scores. Our method leverages the model's inherent self-evaluation capability to extract information about response quality from labeled instruction-tuning data. It incorporates a gold reference answer to facilitate self-evaluation and recalibrates by assessing the semantic similarity between the response sample and the gold reference. During the training phase, we implement self-distillation as a regularization technique to enhance the capability of reference-free estimation. To validate alignment evaluation on general instruction-following tasks, we collect large-scale high-quality instructions from Hugging Face for model training and evaluation. Extensive experiments on five open-source models show that our method correlates much more with GPT-4 than strong baselines, e.g., supervised models distilled from GPT-4 and GPT-3.5-turbo. Our analysis shows our model's strong generalization across domains. Additionally, our judge models serve as good reward models, e.g., boosting WizardLM-13B-V1.2 from 89.17 to 92.48 and from 12.03 to 15.90 in version v1 and v2 of AlpacaEval respectively using best-of-32 sampling with our judge models.
Read more9/4/2024
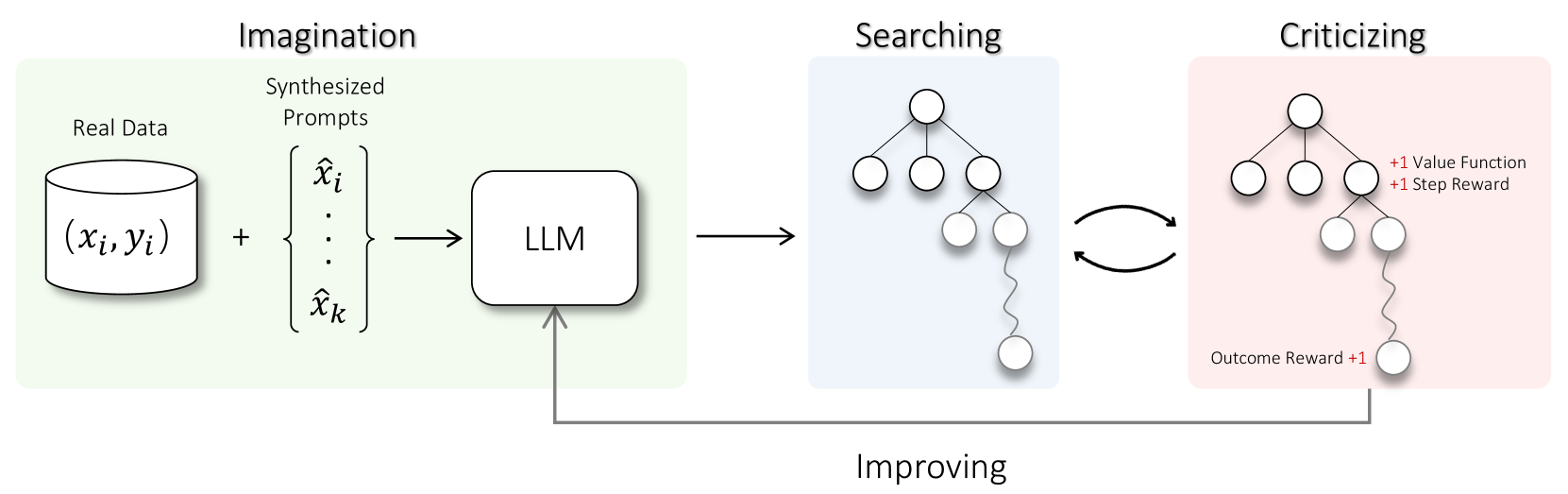
24
Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing
Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi, Dong Yu
Despite the impressive capabilities of Large Language Models (LLMs) on various tasks, they still struggle with scenarios that involves complex reasoning and planning. Recent work proposed advanced prompting techniques and the necessity of fine-tuning with high-quality data to augment LLMs' reasoning abilities. However, these approaches are inherently constrained by data availability and quality. In light of this, self-correction and self-learning emerge as viable solutions, employing strategies that allow LLMs to refine their outputs and learn from self-assessed rewards. Yet, the efficacy of LLMs in self-refining its response, particularly in complex reasoning and planning task, remains dubious. In this paper, we introduce AlphaLLM for the self-improvements of LLMs, which integrates Monte Carlo Tree Search (MCTS) with LLMs to establish a self-improving loop, thereby enhancing the capabilities of LLMs without additional annotations. Drawing inspiration from the success of AlphaGo, AlphaLLM addresses the unique challenges of combining MCTS with LLM for self-improvement, including data scarcity, the vastness search spaces of language tasks, and the subjective nature of feedback in language tasks. AlphaLLM is comprised of prompt synthesis component, an efficient MCTS approach tailored for language tasks, and a trio of critic models for precise feedback. Our experimental results in mathematical reasoning tasks demonstrate that AlphaLLM significantly enhances the performance of LLMs without additional annotations, showing the potential for self-improvement in LLMs.
Read more4/19/2024

0
LLMs Could Autonomously Learn Without External Supervision
Ke Ji, Junying Chen, Anningzhe Gao, Wenya Xie, Xiang Wan, Benyou Wang
In the quest for super-human performance, Large Language Models (LLMs) have traditionally been tethered to human-annotated datasets and predefined training objectives-a process that is both labor-intensive and inherently limited. This paper presents a transformative approach: Autonomous Learning for LLMs, a self-sufficient learning paradigm that frees models from the constraints of human supervision. This method endows LLMs with the ability to self-educate through direct interaction with text, akin to a human reading and comprehending literature. Our approach eliminates the reliance on annotated data, fostering an Autonomous Learning environment where the model independently identifies and reinforces its knowledge gaps. Empirical results from our comprehensive experiments, which utilized a diverse array of learning materials and were evaluated against standard public quizzes, reveal that Autonomous Learning outstrips the performance of both Pre-training and Supervised Fine-Tuning (SFT), as well as retrieval-augmented methods. These findings underscore the potential of Autonomous Learning to not only enhance the efficiency and effectiveness of LLM training but also to pave the way for the development of more advanced, self-reliant AI systems.
Read more6/10/2024