MFCLIP: Multi-modal Fine-grained CLIP for Generalizable Diffusion Face Forgery Detection

0

Sign in to get full access
Overview
- A new approach called MFCLIP for detecting diffusion-based face forgeries
- Uses a multi-modal fine-grained CLIP architecture and image-noise fusion to improve generalization
- Introduces a sample pair attention mechanism to capture fine-grained differences between real and fake faces
- Achieves state-of-the-art performance on commonly used face forgery detection benchmarks
Plain English Explanation
MFCLIP: Multi-modal Fine-grained CLIP for Generalizable Diffusion Face Forgery Detection presents a novel method for detecting AI-generated fake faces, known as "deepfakes." The researchers developed a system called MFCLIP that uses a specialized form of a popular AI model called CLIP to identify subtle differences between real and fake faces.
One of the key challenges in detecting deepfakes is that the generated faces are often highly realistic and can fool even human observers. MFCLIP addresses this by fusing information from both the image itself and the "noise" or subtle distortions introduced by the generative AI model. This multi-modal approach helps the system pick up on fine-grained details that distinguish real from fake.
The researchers also introduced a "sample pair attention" mechanism that allows MFCLIP to directly compare real and fake face samples, capturing the nuanced differences between them. This helps the system generalize better to new types of deepfakes it hasn't seen before.
Overall, MFCLIP demonstrates strong performance in detecting diffusion-based face forgeries, outperforming previous state-of-the-art methods on standard benchmarks. This research represents an important step forward in the ongoing battle against the rise of highly convincing AI-generated media.
Technical Explanation
MFCLIP builds on the success of the CLIP model, a powerful multimodal AI system that can recognize and reason about visual and textual information. The researchers adapt CLIP to the specific task of detecting diffusion-based face forgeries, introducing several key innovations.
First, they leverage a "fine-grained" version of CLIP that can capture subtle differences between real and fake faces. This is achieved by training the model on a diverse dataset of real and AI-generated faces, enabling it to learn the nuanced visual cues that distinguish them.
Second, MFCLIP fuses information from the image itself and the "noise" introduced by the diffusion generative process. This multi-modal approach helps the model pick up on telltale signs of forgery that may not be apparent from the image alone.
Finally, the researchers incorporate a "sample pair attention" mechanism that allows MFCLIP to directly compare real and fake face samples, focusing on the fine-grained differences between them. This helps the model generalize better to new types of deepfakes it hasn't encountered during training.
Through extensive experiments, the authors demonstrate that MFCLIP outperforms previous state-of-the-art methods on a range of face forgery detection benchmarks. This suggests that their approach offers a promising pathway for building more robust and generalizable deepfake detection systems.
Critical Analysis
The MFCLIP paper presents a compelling and well-designed approach to the important problem of diffusion-based face forgery detection. The researchers have clearly put significant thought and effort into developing a system that can reliably identify AI-generated faces, even as the underlying generative models continue to improve.
That said, the authors do acknowledge some potential limitations of their work. For example, they note that MFCLIP may be less effective at detecting deepfakes generated by methods other than diffusion, such as those based on generative adversarial networks (GANs). Additionally, the model's performance could be sensitive to the specific training data and preprocessing steps used, which may limit its generalization to real-world scenarios.
Furthermore, the paper does not delve deeply into the potential societal implications of this technology. While improving deepfake detection is important for combating misinformation and preserving digital media integrity, it's crucial to consider the broader ethical considerations and potential for misuse of such systems.
Overall, the MFCLIP paper represents a significant technical advancement in the field of face forgery detection. However, continued research and open dialogue around the broader implications of this technology will be essential as it continues to evolve.
Conclusion
MFCLIP: Multi-modal Fine-grained CLIP for Generalizable Diffusion Face Forgery Detection introduces a novel approach to detecting AI-generated fake faces, or "deepfakes." By leveraging a fine-grained version of the CLIP model and incorporating multi-modal information, the researchers have developed a system that can reliably identify subtle differences between real and fake faces.
The key innovations of MFCLIP, including its image-noise fusion and sample pair attention mechanisms, demonstrate the potential for specialized AI architectures to outperform previous state-of-the-art methods in this critical domain. As deepfake technology continues to advance, tools like MFCLIP will become increasingly important for preserving the integrity of digital media and combating the spread of misinformation.
While this research represents an important step forward, ongoing work will be needed to address the broader societal implications and potential misuse of deepfake detection systems. Nonetheless, the MFCLIP paper offers a promising blueprint for building more robust and generalizable solutions to the growing challenge of face forgery detection.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!MFCLIP: Multi-modal Fine-grained CLIP for Generalizable Diffusion Face Forgery Detection
Yaning Zhang, Tianyi Wang, Zitong Yu, Zan Gao, Linlin Shen, Shengyong Chen
The rapid development of photo-realistic face generation methods has raised significant concerns in society and academia, highlighting the urgent need for robust and generalizable face forgery detection (FFD) techniques. Although existing approaches mainly capture face forgery patterns using image modality, other modalities like fine-grained noises and texts are not fully explored, which limits the generalization capability of the model. In addition, most FFD methods tend to identify facial images generated by GAN, but struggle to detect unseen diffusion-synthesized ones. To address the limitations, we aim to leverage the cutting-edge foundation model, contrastive language-image pre-training (CLIP), to achieve generalizable diffusion face forgery detection (DFFD). In this paper, we propose a novel multi-modal fine-grained CLIP (MFCLIP) model, which mines comprehensive and fine-grained forgery traces across image-noise modalities via language-guided face forgery representation learning, to facilitate the advancement of DFFD. Specifically, we devise a fine-grained language encoder (FLE) that extracts fine global language features from hierarchical text prompts. We design a multi-modal vision encoder (MVE) to capture global image forgery embeddings as well as fine-grained noise forgery patterns extracted from the richest patch, and integrate them to mine general visual forgery traces. Moreover, we build an innovative plug-and-play sample pair attention (SPA) method to emphasize relevant negative pairs and suppress irrelevant ones, allowing cross-modality sample pairs to conduct more flexible alignment. Extensive experiments and visualizations show that our model outperforms the state of the arts on different settings like cross-generator, cross-forgery, and cross-dataset evaluations.
Read more9/17/2024

0
FineCLIPER: Multi-modal Fine-grained CLIP for Dynamic Facial Expression Recognition with AdaptERs
Haodong Chen, Haojian Huang, Junhao Dong, Mingzhe Zheng, Dian Shao
Dynamic Facial Expression Recognition (DFER) is crucial for understanding human behavior. However, current methods exhibit limited performance mainly due to the scarcity of high-quality data, the insufficient utilization of facial dynamics, and the ambiguity of expression semantics, etc. To this end, we propose a novel framework, named Multi-modal Fine-grained CLIP for Dynamic Facial Expression Recognition with AdaptERs (FineCLIPER), incorporating the following novel designs: 1) To better distinguish between similar facial expressions, we extend the class labels to textual descriptions from both positive and negative aspects, and obtain supervision by calculating the cross-modal similarity based on the CLIP model; 2) Our FineCLIPER adopts a hierarchical manner to effectively mine useful cues from DFE videos. Specifically, besides directly embedding video frames as input (low semantic level), we propose to extract the face segmentation masks and landmarks based on each frame (middle semantic level) and utilize the Multi-modal Large Language Model (MLLM) to further generate detailed descriptions of facial changes across frames with designed prompts (high semantic level). Additionally, we also adopt Parameter-Efficient Fine-Tuning (PEFT) to enable efficient adaptation of large pre-trained models (i.e., CLIP) for this task. Our FineCLIPER achieves SOTA performance on the DFEW, FERV39k, and MAFW datasets in both supervised and zero-shot settings with few tunable parameters. Project Page: https://haroldchen19.github.io/FineCLIPER-Page/
Read more7/24/2024

0
Guided and Fused: Efficient Frozen CLIP-ViT with Feature Guidance and Multi-Stage Feature Fusion for Generalizable Deepfake Detection
Yingjian Chen, Lei Zhang, Yakun Niu, Pei Chen, Lei Tan, Jing Zhou
The rise of generative models has sparked concerns about image authenticity online, highlighting the urgent need for an effective and general detector. Recent methods leveraging the frozen pre-trained CLIP-ViT model have made great progress in deepfake detection. However, these models often rely on visual-general features directly extracted by the frozen network, which contain excessive information irrelevant to the task, resulting in limited detection performance. To address this limitation, in this paper, we propose an efficient Guided and Fused Frozen CLIP-ViT (GFF), which integrates two simple yet effective modules. The Deepfake-Specific Feature Guidance Module (DFGM) guides the frozen pre-trained model in extracting features specifically for deepfake detection, reducing irrelevant information while preserving its generalization capabilities. The Multi-Stage Fusion Module (FuseFormer) captures low-level and high-level information by fusing features extracted from each stage of the ViT. This dual-module approach significantly improves deepfake detection by fully leveraging CLIP-ViT's inherent advantages. Extensive experiments demonstrate the effectiveness and generalization ability of GFF, which achieves state-of-the-art performance with optimal results in only 5 training epochs. Even when trained on only 4 classes of ProGAN, GFF achieves nearly 99% accuracy on unseen GANs and maintains an impressive 97% accuracy on unseen diffusion models.
Read more8/27/2024
0
Robust CLIP-Based Detector for Exposing Diffusion Model-Generated Images
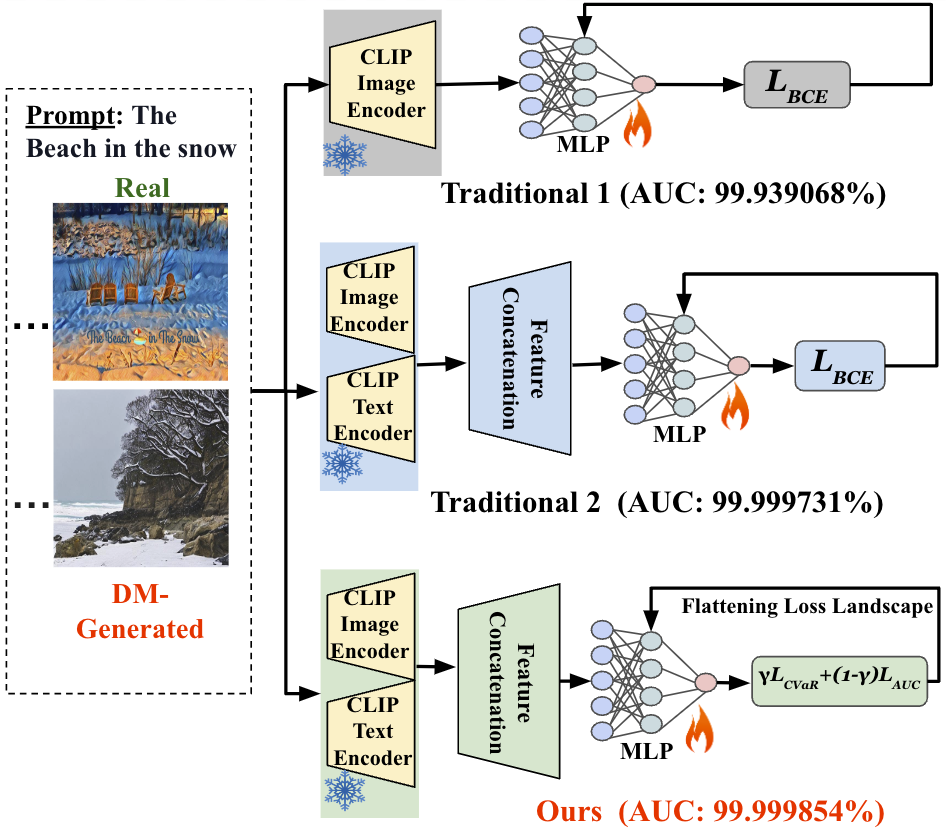
Santosh, Li Lin, Irene Amerini, Xin Wang, Shu Hu
Diffusion models (DMs) have revolutionized image generation, producing high-quality images with applications spanning various fields. However, their ability to create hyper-realistic images poses significant challenges in distinguishing between real and synthetic content, raising concerns about digital authenticity and potential misuse in creating deepfakes. This work introduces a robust detection framework that integrates image and text features extracted by CLIP model with a Multilayer Perceptron (MLP) classifier. We propose a novel loss that can improve the detector's robustness and handle imbalanced datasets. Additionally, we flatten the loss landscape during the model training to improve the detector's generalization capabilities. The effectiveness of our method, which outperforms traditional detection techniques, is demonstrated through extensive experiments, underscoring its potential to set a new state-of-the-art approach in DM-generated image detection. The code is available at https://github.com/Purdue-M2/Robust_DM_Generated_Image_Detection.
Read more9/10/2024