Guided and Fused: Efficient Frozen CLIP-ViT with Feature Guidance and Multi-Stage Feature Fusion for Generalizable Deepfake Detection

0

Sign in to get full access
Overview
- This paper proposes a novel approach for efficient and generalizable deepfake detection using a frozen CLIP-ViT model with feature guidance and multi-stage feature fusion.
- The key contributions are:
- Efficient frozen CLIP-ViT architecture for deepfake detection
- Feature guidance and multi-stage feature fusion to improve performance
- Comprehensive evaluation on multiple datasets to demonstrate generalizability
Plain English Explanation
The paper introduces a new way to detect deepfakes, which are manipulated images or videos that appear real but are artificially created. The researchers developed an efficient deep learning model that uses a pre-trained CLIP-ViT (Contrastive Language-Image Pre-Training Vision Transformer) as its backbone.
To make the model more effective, they added two key innovations:
- Feature Guidance: The model uses information from the pre-trained CLIP-ViT to "guide" the detection of deepfakes. This helps the model focus on the most relevant visual features.
- Multi-Stage Feature Fusion: The model combines features from multiple stages of the CLIP-ViT network. This allows it to capture both low-level details and high-level semantic information, improving its ability to identify deepfakes.
By using this efficient and guided approach, the researchers were able to create a deepfake detection model that performs well across a variety of datasets, demonstrating its generalizability. This is an important capability, as deepfake technologies continue to evolve and become more sophisticated.
Technical Explanation
The paper proposes a Guided and Fused Efficient Frozen CLIP-ViT (GF-CLIP-ViT) model for generalizable deepfake detection. The key innovations are:
- Efficient Frozen CLIP-ViT Architecture: The researchers use a pre-trained CLIP-ViT as the backbone of their model, which they "freeze" to avoid the need for extensive training. This makes the model more efficient and easier to deploy.
- Feature Guidance: The model uses the features from the pre-trained CLIP-ViT to guide the detection process. This helps the model focus on the most relevant visual cues for identifying deepfakes.
- Multi-Stage Feature Fusion: The model combines features from multiple stages of the CLIP-ViT network, allowing it to capture both low-level details and high-level semantic information. This improves the model's ability to distinguish real from fake images.
The researchers evaluate their model on multiple deepfake detection datasets and demonstrate its superior performance and generalizability compared to other state-of-the-art approaches.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed GF-CLIP-ViT model. However, a few potential limitations and areas for future research are worth noting:
- The model relies on a pre-trained CLIP-ViT backbone, which may limit its ability to adapt to rapidly evolving deepfake techniques. Exploring ways to fine-tune or update the model over time could be an important area for future research.
- The paper focuses on image-based deepfake detection, but expanding the approach to video-based deepfakes could further enhance its real-world applicability.
- While the model demonstrates strong generalizability, testing it on even more diverse datasets, including those with potential domain shifts, could provide additional insights into its robustness.
Overall, the paper presents a promising and well-executed approach to efficient and generalizable deepfake detection, which could have important implications for maintaining the integrity of digital media in the face of rapidly evolving deepfake technologies.
Conclusion
This paper introduces a novel approach for efficient and generalizable deepfake detection using a frozen CLIP-ViT model with feature guidance and multi-stage feature fusion. The key innovations, including the efficient architecture, feature guidance, and multi-stage fusion, allow the model to achieve strong performance across multiple deepfake datasets, demonstrating its potential for real-world applications. While the paper highlights several promising directions, continued research on adapting the model to emerging deepfake techniques and expanding its capabilities to video-based detection could further enhance its impact in the fight against the spread of deceptive digital media.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Guided and Fused: Efficient Frozen CLIP-ViT with Feature Guidance and Multi-Stage Feature Fusion for Generalizable Deepfake Detection
Yingjian Chen, Lei Zhang, Yakun Niu, Pei Chen, Lei Tan, Jing Zhou
The rise of generative models has sparked concerns about image authenticity online, highlighting the urgent need for an effective and general detector. Recent methods leveraging the frozen pre-trained CLIP-ViT model have made great progress in deepfake detection. However, these models often rely on visual-general features directly extracted by the frozen network, which contain excessive information irrelevant to the task, resulting in limited detection performance. To address this limitation, in this paper, we propose an efficient Guided and Fused Frozen CLIP-ViT (GFF), which integrates two simple yet effective modules. The Deepfake-Specific Feature Guidance Module (DFGM) guides the frozen pre-trained model in extracting features specifically for deepfake detection, reducing irrelevant information while preserving its generalization capabilities. The Multi-Stage Fusion Module (FuseFormer) captures low-level and high-level information by fusing features extracted from each stage of the ViT. This dual-module approach significantly improves deepfake detection by fully leveraging CLIP-ViT's inherent advantages. Extensive experiments demonstrate the effectiveness and generalization ability of GFF, which achieves state-of-the-art performance with optimal results in only 5 training epochs. Even when trained on only 4 classes of ProGAN, GFF achieves nearly 99% accuracy on unseen GANs and maintains an impressive 97% accuracy on unseen diffusion models.
Read more8/27/2024
0
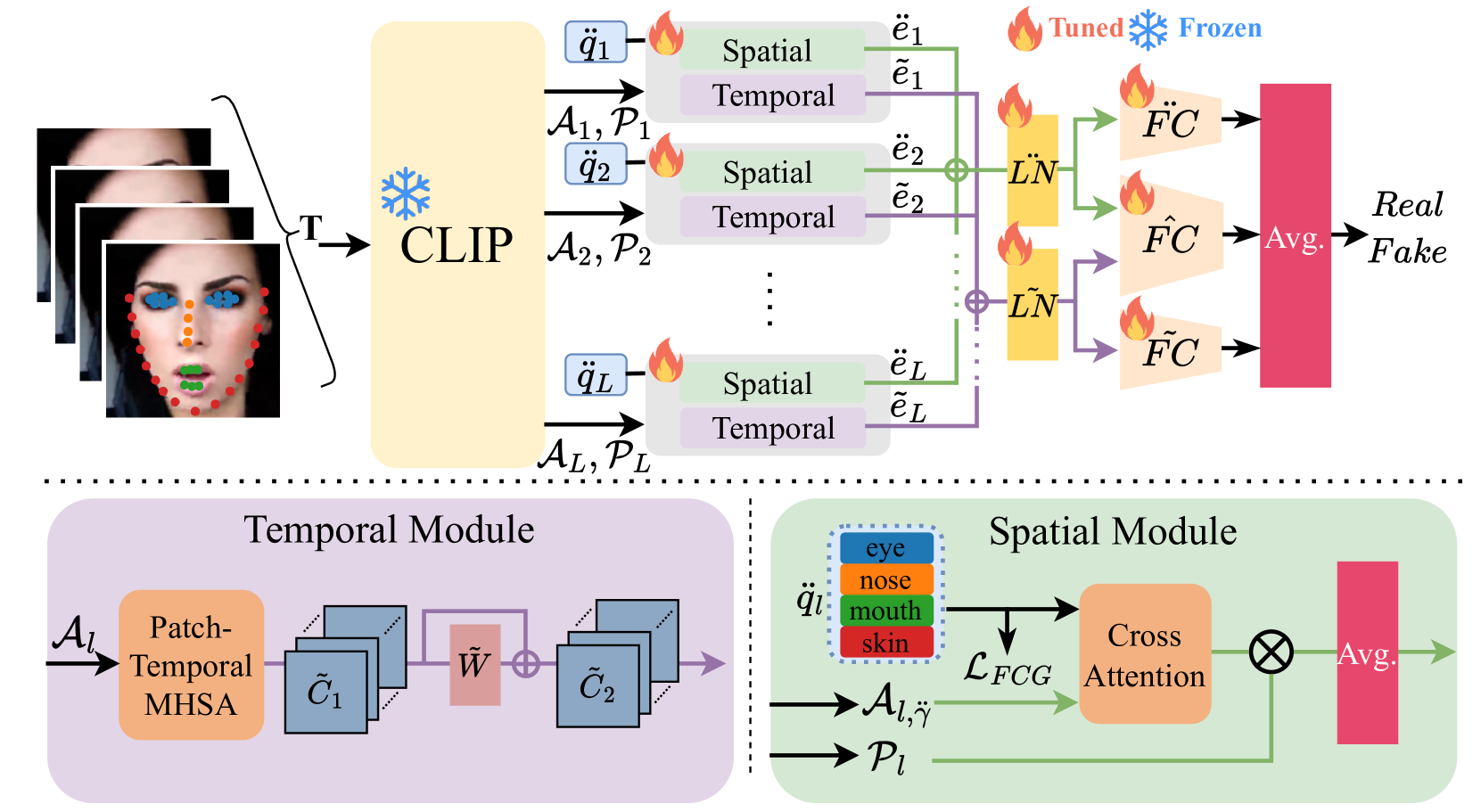
Towards More General Video-based Deepfake Detection through Facial Feature Guided Adaptation for Foundation Model
Yue-Hua Han, Tai-Ming Huang, Shu-Tzu Lo, Po-Han Huang, Kai-Lung Hua, Jun-Cheng Chen
With the rise of deep learning, generative models have enabled the creation of highly realistic synthetic images, presenting challenges due to their potential misuse. While research in Deepfake detection has grown rapidly in response, many detection methods struggle with unseen Deepfakes generated by new synthesis techniques. To address this generalisation challenge, we propose a novel Deepfake detection approach by adapting the Foundation Models with rich information encoded inside, specifically using the image encoder from CLIP which has demonstrated strong zero-shot capability for downstream tasks. Inspired by the recent advances of parameter efficient fine-tuning, we propose a novel side-network-based decoder to extract spatial and temporal cues from the given video clip, with the promotion of the Facial Component Guidance (FCG) to encourage the spatial feature to include features of key facial parts for more robust and general Deepfake detection. Through extensive cross-dataset evaluations, our approach exhibits superior effectiveness in identifying unseen Deepfake samples, achieving notable performance improvement even with limited training samples and manipulation types. Our model secures an average performance enhancement of 0.9% AUROC in cross-dataset assessments comparing with state-of-the-art methods, especially a significant lead of achieving 4.4% improvement on the challenging DFDC dataset.
Read more6/6/2024

0
New!MFCLIP: Multi-modal Fine-grained CLIP for Generalizable Diffusion Face Forgery Detection
Yaning Zhang, Tianyi Wang, Zitong Yu, Zan Gao, Linlin Shen, Shengyong Chen
The rapid development of photo-realistic face generation methods has raised significant concerns in society and academia, highlighting the urgent need for robust and generalizable face forgery detection (FFD) techniques. Although existing approaches mainly capture face forgery patterns using image modality, other modalities like fine-grained noises and texts are not fully explored, which limits the generalization capability of the model. In addition, most FFD methods tend to identify facial images generated by GAN, but struggle to detect unseen diffusion-synthesized ones. To address the limitations, we aim to leverage the cutting-edge foundation model, contrastive language-image pre-training (CLIP), to achieve generalizable diffusion face forgery detection (DFFD). In this paper, we propose a novel multi-modal fine-grained CLIP (MFCLIP) model, which mines comprehensive and fine-grained forgery traces across image-noise modalities via language-guided face forgery representation learning, to facilitate the advancement of DFFD. Specifically, we devise a fine-grained language encoder (FLE) that extracts fine global language features from hierarchical text prompts. We design a multi-modal vision encoder (MVE) to capture global image forgery embeddings as well as fine-grained noise forgery patterns extracted from the richest patch, and integrate them to mine general visual forgery traces. Moreover, we build an innovative plug-and-play sample pair attention (SPA) method to emphasize relevant negative pairs and suppress irrelevant ones, allowing cross-modality sample pairs to conduct more flexible alignment. Extensive experiments and visualizations show that our model outperforms the state of the arts on different settings like cross-generator, cross-forgery, and cross-dataset evaluations.
Read more9/17/2024

0
Mixture of Low-rank Experts for Transferable AI-Generated Image Detection
Zihan Liu, Hanyi Wang, Yaoyu Kang, Shilin Wang
Generative models have shown a giant leap in synthesizing photo-realistic images with minimal expertise, sparking concerns about the authenticity of online information. This study aims to develop a universal AI-generated image detector capable of identifying images from diverse sources. Existing methods struggle to generalize across unseen generative models when provided with limited sample sources. Inspired by the zero-shot transferability of pre-trained vision-language models, we seek to harness the nontrivial visual-world knowledge and descriptive proficiency of CLIP-ViT to generalize over unknown domains. This paper presents a novel parameter-efficient fine-tuning approach, mixture of low-rank experts, to fully exploit CLIP-ViT's potential while preserving knowledge and expanding capacity for transferable detection. We adapt only the MLP layers of deeper ViT blocks via an integration of shared and separate LoRAs within an MoE-based structure. Extensive experiments on public benchmarks show that our method achieves superiority over state-of-the-art approaches in cross-generator generalization and robustness to perturbations. Remarkably, our best-performing ViT-L/14 variant requires training only 0.08% of its parameters to surpass the leading baseline by +3.64% mAP and +12.72% avg.Acc across unseen diffusion and autoregressive models. This even outperforms the baseline with just 0.28% of the training data. Our code and pre-trained models will be available at https://github.com/zhliuworks/CLIPMoLE.
Read more4/9/2024