MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning

0

Sign in to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning
Xiangyu Zhao, Xiangtai Li, Haodong Duan, Haian Huang, Yining Li, Kai Chen, Hua Yang
Multi-modal large language models (MLLMs) have made significant strides in various visual understanding tasks. However, the majority of these models are constrained to process low-resolution images, which limits their effectiveness in perception tasks that necessitate detailed visual information. In our study, we present MG-LLaVA, an innovative MLLM that enhances the model's visual processing capabilities by incorporating a multi-granularity vision flow, which includes low-resolution, high-resolution, and object-centric features. We propose the integration of an additional high-resolution visual encoder to capture fine-grained details, which are then fused with base visual features through a Conv-Gate fusion network. To further refine the model's object recognition abilities, we incorporate object-level features derived from bounding boxes identified by offline detectors. Being trained solely on publicly available multimodal data through instruction tuning, MG-LLaVA demonstrates exceptional perception skills. We instantiate MG-LLaVA with a wide variety of language encoders, ranging from 3.8B to 34B, to evaluate the model's performance comprehensively. Extensive evaluations across multiple benchmarks demonstrate that MG-LLaVA outperforms existing MLLMs of comparable parameter sizes, showcasing its remarkable efficacy. The code will be available at https://github.com/PhoenixZ810/MG-LLaVA.
Read more6/28/2024
💬
0
u-LLaVA: Unifying Multi-Modal Tasks via Large Language Model
Jinjin Xu, Liwu Xu, Yuzhe Yang, Xiang Li, Fanyi Wang, Yanchun Xie, Yi-Jie Huang, Yaqian Li
Recent advancements in multi-modal large language models (MLLMs) have led to substantial improvements in visual understanding, primarily driven by sophisticated modality alignment strategies. However, predominant approaches prioritize global or regional comprehension, with less focus on fine-grained, pixel-level tasks. To address this gap, we introduce u-LLaVA, an innovative unifying multi-task framework that integrates pixel, regional, and global features to refine the perceptual faculties of MLLMs. We commence by leveraging an efficient modality alignment approach, harnessing both image and video datasets to bolster the model's foundational understanding across diverse visual contexts. Subsequently, a joint instruction tuning method with task-specific projectors and decoders for end-to-end downstream training is presented. Furthermore, this work contributes a novel mask-based multi-task dataset comprising 277K samples, crafted to challenge and assess the fine-grained perception capabilities of MLLMs. The overall framework is simple, effective, and achieves state-of-the-art performance across multiple benchmarks. We also make our model, data, and code publicly accessible at https://github.com/OPPOMKLab/u-LLaVA.
Read more8/29/2024

0
INF-LLaVA: Dual-perspective Perception for High-Resolution Multimodal Large Language Model
Yiwei Ma, Zhibin Wang, Xiaoshuai Sun, Weihuang Lin, Qiang Zhou, Jiayi Ji, Rongrong Ji
With advancements in data availability and computing resources, Multimodal Large Language Models (MLLMs) have showcased capabilities across various fields. However, the quadratic complexity of the vision encoder in MLLMs constrains the resolution of input images. Most current approaches mitigate this issue by cropping high-resolution images into smaller sub-images, which are then processed independently by the vision encoder. Despite capturing sufficient local details, these sub-images lack global context and fail to interact with one another. To address this limitation, we propose a novel MLLM, INF-LLaVA, designed for effective high-resolution image perception. INF-LLaVA incorporates two innovative components. First, we introduce a Dual-perspective Cropping Module (DCM), which ensures that each sub-image contains continuous details from a local perspective and comprehensive information from a global perspective. Second, we introduce Dual-perspective Enhancement Module (DEM) to enable the mutual enhancement of global and local features, allowing INF-LLaVA to effectively process high-resolution images by simultaneously capturing detailed local information and comprehensive global context. Extensive ablation studies validate the effectiveness of these components, and experiments on a diverse set of benchmarks demonstrate that INF-LLaVA outperforms existing MLLMs. Code and pretrained model are available at https://github.com/WeihuangLin/INF-LLaVA.
Read more7/24/2024
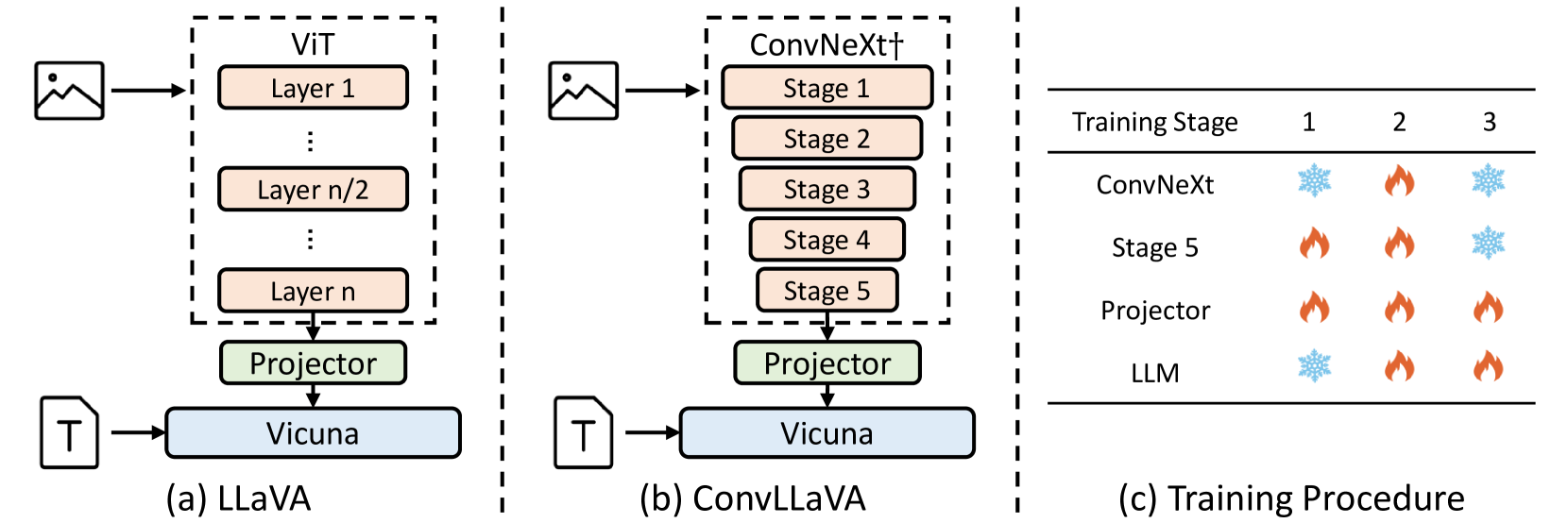
0
ConvLLaVA: Hierarchical Backbones as Visual Encoder for Large Multimodal Models
Chunjiang Ge, Sijie Cheng, Ziming Wang, Jiale Yuan, Yuan Gao, Jun Song, Shiji Song, Gao Huang, Bo Zheng
High-resolution Large Multimodal Models (LMMs) encounter the challenges of excessive visual tokens and quadratic visual complexity. Current high-resolution LMMs address the quadratic complexity while still generating excessive visual tokens. However, the redundancy in visual tokens is the key problem as it leads to more substantial compute. To mitigate this issue, we propose ConvLLaVA, which employs ConvNeXt, a hierarchical backbone, as the visual encoder of LMM to replace Vision Transformer (ViT). ConvLLaVA compresses high-resolution images into information-rich visual features, effectively preventing the generation of excessive visual tokens. To enhance the capabilities of ConvLLaVA, we propose two critical optimizations. Since the low-resolution pretrained ConvNeXt underperforms when directly applied on high resolution, we update it to bridge the gap. Moreover, since ConvNeXt's original compression ratio is inadequate for much higher resolution inputs, we train a successive stage to further compress the visual tokens, thereby reducing redundancy. These optimizations enable ConvLLaVA to support inputs of 1536x1536 resolution generating only 576 visual tokens, capable of handling images of arbitrary aspect ratios. Experimental results demonstrate that our method achieves competitive performance with state-of-the-art models on mainstream benchmarks. The ConvLLaVA model series are publicly available at https://github.com/alibaba/conv-llava.
Read more5/27/2024