ConvLLaVA: Hierarchical Backbones as Visual Encoder for Large Multimodal Models

0
Sign in to get full access
Overview
- The paper presents ConvLLaVA, a new visual encoder architecture for large multimodal models.
- ConvLLaVA uses a hierarchical backbone design to capture visual information at multiple scales.
- The authors claim this approach leads to improved performance on various visual tasks compared to existing models.
Plain English Explanation
The paper introduces a new way to process visual information for large AI models that handle both images and text. Traditional models often use a single neural network to encode visual data, but the authors of this paper argue that a more hierarchical approach can be more effective.
ConvLLaVA: Hierarchical Backbones as Visual Encoder for Large Multimodal Models uses a series of interconnected neural networks to capture visual information at different levels of detail. This allows the model to understand both the overall structure of an image as well as smaller, more granular details.
The authors claim this hierarchical visual encoder leads to better performance on a variety of visual tasks compared to existing models. This could be useful for applications like visual instruction tuning, where an AI system needs to understand detailed visual information to follow instructions.
Technical Explanation
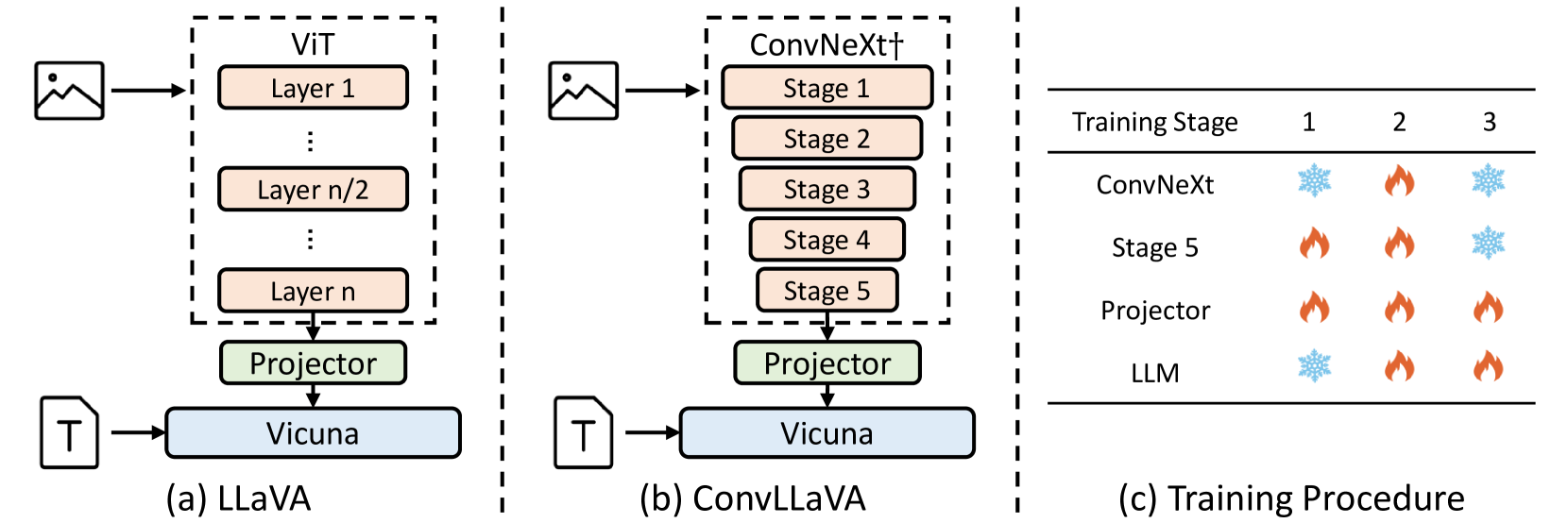
The key innovation in ConvLLaVA is its hierarchical visual encoder backbone. Rather than using a single convolutional neural network to process the entire image, ConvLLaVA employs a series of interconnected sub-networks, each capturing information at a different scale.
The first layer of the backbone is a traditional convolutional network that extracts low-level visual features. These features are then passed to a series of "connector" modules that fuse information across multiple scales. This allows the model to build a rich, multi-resolution representation of the input image.
The authors demonstrate the effectiveness of this approach through experiments on several benchmark datasets, including COCO and ImageNet. ConvLLaVA outperforms a range of existing visual encoders, including LLaVA, on a variety of visual tasks.
Critical Analysis
The authors provide a thorough evaluation of ConvLLaVA, but there are a few potential limitations to consider:
- The hierarchical backbone adds complexity to the model, which could make it more difficult to train and deploy in real-world applications.
- The paper does not explore the trade-offs between model size, inference speed, and performance in depth. This information would be valuable for understanding the practical implications of using ConvLLaVA.
- While the results on benchmark datasets are promising, it's unclear how well the model would generalize to more diverse or challenging visual domains. Further testing would be needed to assess its broader applicability.
Overall, the ConvLLaVA approach is an interesting contribution to the field of large multimodal models. However, additional research and development may be needed to fully realize its potential benefits in practical applications.
Conclusion
The ConvLLaVA paper presents a novel visual encoder architecture that uses a hierarchical backbone to capture visual information at multiple scales. The authors demonstrate that this approach can lead to improved performance on a range of visual tasks compared to existing models.
While the technical details of the architecture are complex, the core idea of using a multi-scale representation to better understand images is relatively straightforward. This could have important implications for applications that require detailed visual understanding, such as visual instruction tuning and multimodal reasoning.
As with any new research, there are still questions and limitations that need to be addressed. But the ConvLLaVA paper represents an exciting step forward in the development of more powerful and versatile multimodal AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ConvLLaVA: Hierarchical Backbones as Visual Encoder for Large Multimodal Models
Chunjiang Ge, Sijie Cheng, Ziming Wang, Jiale Yuan, Yuan Gao, Jun Song, Shiji Song, Gao Huang, Bo Zheng
High-resolution Large Multimodal Models (LMMs) encounter the challenges of excessive visual tokens and quadratic visual complexity. Current high-resolution LMMs address the quadratic complexity while still generating excessive visual tokens. However, the redundancy in visual tokens is the key problem as it leads to more substantial compute. To mitigate this issue, we propose ConvLLaVA, which employs ConvNeXt, a hierarchical backbone, as the visual encoder of LMM to replace Vision Transformer (ViT). ConvLLaVA compresses high-resolution images into information-rich visual features, effectively preventing the generation of excessive visual tokens. To enhance the capabilities of ConvLLaVA, we propose two critical optimizations. Since the low-resolution pretrained ConvNeXt underperforms when directly applied on high resolution, we update it to bridge the gap. Moreover, since ConvNeXt's original compression ratio is inadequate for much higher resolution inputs, we train a successive stage to further compress the visual tokens, thereby reducing redundancy. These optimizations enable ConvLLaVA to support inputs of 1536x1536 resolution generating only 576 visual tokens, capable of handling images of arbitrary aspect ratios. Experimental results demonstrate that our method achieves competitive performance with state-of-the-art models on mainstream benchmarks. The ConvLLaVA model series are publicly available at https://github.com/alibaba/conv-llava.
Read more5/27/2024

0
MG-LLaVA: Towards Multi-Granularity Visual Instruction Tuning
Xiangyu Zhao, Xiangtai Li, Haodong Duan, Haian Huang, Yining Li, Kai Chen, Hua Yang
Multi-modal large language models (MLLMs) have made significant strides in various visual understanding tasks. However, the majority of these models are constrained to process low-resolution images, which limits their effectiveness in perception tasks that necessitate detailed visual information. In our study, we present MG-LLaVA, an innovative MLLM that enhances the model's visual processing capabilities by incorporating a multi-granularity vision flow, which includes low-resolution, high-resolution, and object-centric features. We propose the integration of an additional high-resolution visual encoder to capture fine-grained details, which are then fused with base visual features through a Conv-Gate fusion network. To further refine the model's object recognition abilities, we incorporate object-level features derived from bounding boxes identified by offline detectors. Being trained solely on publicly available multimodal data through instruction tuning, MG-LLaVA demonstrates exceptional perception skills. We instantiate MG-LLaVA with a wide variety of language encoders, ranging from 3.8B to 34B, to evaluate the model's performance comprehensively. Extensive evaluations across multiple benchmarks demonstrate that MG-LLaVA outperforms existing MLLMs of comparable parameter sizes, showcasing its remarkable efficacy. The code will be available at https://github.com/PhoenixZ810/MG-LLaVA.
Read more6/28/2024

0
LongLLaVA: Scaling Multi-modal LLMs to 1000 Images Efficiently via Hybrid Architecture
Xidong Wang, Dingjie Song, Shunian Chen, Chen Zhang, Benyou Wang
Expanding the long-context capabilities of Multi-modal Large Language Models~(MLLMs) is crucial for video understanding, high-resolution image understanding, and multi-modal agents. This involves a series of systematic optimizations, including model architecture, data construction and training strategy, particularly addressing challenges such as textit{degraded performance with more images} and textit{high computational costs}. In this paper, we adapt the model architecture to a hybrid of Mamba and Transformer blocks, approach data construction with both temporal and spatial dependencies among multiple images and employ a progressive training strategy. The released model textbf{LongLLaVA}~(textbf{Long}-Context textbf{L}arge textbf{L}anguage textbf{a}nd textbf{V}ision textbf{A}ssistant) is the first hybrid MLLM, which achieved a better balance between efficiency and effectiveness. LongLLaVA not only achieves competitive results across various benchmarks, but also maintains high throughput and low memory consumption. Especially, it could process nearly a thousand images on a single A100 80GB GPU, showing promising application prospects for a wide range of tasks.
Read more9/5/2024

0
VoCo-LLaMA: Towards Vision Compression with Large Language Models
Xubing Ye, Yukang Gan, Xiaoke Huang, Yixiao Ge, Ying Shan, Yansong Tang
Vision-Language Models (VLMs) have achieved remarkable success in various multi-modal tasks, but they are often bottlenecked by the limited context window and high computational cost of processing high-resolution image inputs and videos. Vision compression can alleviate this problem by reducing the vision token count. Previous approaches compress vision tokens with external modules and force LLMs to understand the compressed ones, leading to visual information loss. However, the LLMs' understanding paradigm of vision tokens is not fully utilised in the compression learning process. We propose VoCo-LLaMA, the first approach to compress vision tokens using LLMs. By introducing Vision Compression tokens during the vision instruction tuning phase and leveraging attention distillation, our method distill how LLMs comprehend vision tokens into their processing of VoCo tokens. VoCo-LLaMA facilitates effective vision compression and improves the computational efficiency during the inference stage. Specifically, our method achieves minimal performance loss with a compression ratio of 576$times$, resulting in up to 94.8$%$ fewer FLOPs and 69.6$%$ acceleration in inference time. Furthermore, through continuous training using time-series compressed token sequences of video frames, VoCo-LLaMA demonstrates the ability to understand temporal correlations, outperforming previous methods on popular video question-answering benchmarks. Our approach presents a promising way to unlock the full potential of VLMs' contextual window, enabling more scalable multi-modal applications. The project page, along with the associated code, can be accessed via $href{https://yxxxb.github.io/VoCo-LLaMA-page/}{text{this https URL}}$.
Read more6/19/2024