Micro-Expression Recognition by Motion Feature Extraction based on Pre-training

0
Sign in to get full access
Overview
- This paper presents a novel method for micro-expression recognition using motion feature extraction based on pre-training.
- Micro-expressions are brief, subtle facial movements that can reveal true emotions, and their recognition is important in fields like psychology, security, and human-computer interaction.
- The proposed approach aims to improve micro-expression recognition by leveraging pre-trained models to extract discriminative motion features.
Plain English Explanation
Micro-expressions are tiny, fleeting facial movements that can reveal a person's true emotions, even if they're trying to hide them. Recognizing these micro-expressions is important in fields like psychology, security, and human-computer interaction, as they can provide valuable insights into a person's inner thoughts and feelings.
The researchers in this paper have developed a new method to improve the recognition of micro-expressions. Their approach involves using pre-trained models, which are machine learning models that have been trained on large datasets to perform various tasks. The researchers use these pre-trained models to extract specific features from the micro-expressions, such as the patterns and movements of the facial muscles. By using these pre-trained models, the researchers can better identify the unique characteristics of micro-expressions, making it easier to accurately recognize them.
This innovative approach could lead to significant advancements in micro-expression recognition, with potential applications in fields like mental health assessment, lie detection, and human-computer interaction. By being able to more reliably detect these subtle facial cues, researchers and practitioners can gain deeper insights into human behavior and emotion.
Technical Explanation
The paper introduces a micro-expression recognition method that leverages pre-trained models to extract discriminative motion features. The authors propose a framework that first pre-trains a motion feature extractor on a large-scale action recognition dataset, and then fine-tunes the pre-trained model on micro-expression datasets.
The pre-training stage involves transfer learning from a 3D convolutional neural network (CNN) model trained on the Kinetics dataset, a large-scale video action recognition dataset. The fine-tuning stage then adapts the pre-trained model to the specific task of micro-expression recognition using datasets like CASME II and SAMM.
The authors compare their method to other state-of-the-art micro-expression recognition approaches, including those that use hierarchical spatio-temporal attention and adaptive temporal motion-guided graph convolution. The results demonstrate that their pre-training-based method outperforms these alternatives, achieving higher recognition accuracy on multiple micro-expression datasets.
Critical Analysis
The paper presents a promising approach to micro-expression recognition, leveraging pre-trained models to extract discriminative motion features. The authors provide a thorough technical explanation and evaluation of their method, demonstrating its advantages over other state-of-the-art techniques.
One potential limitation of the study is the reliance on pre-trained models trained on general action recognition datasets, which may not fully capture the nuanced characteristics of micro-expressions. While the fine-tuning process helps adapt the model to the specific task, there may be room for further optimization by incorporating micro-expression-specific pre-training or architectural modifications.
Additionally, the paper does not discuss the computational complexity or real-time performance of the proposed method, which could be important considerations for practical applications, such as in human-computer interaction or real-time monitoring systems.
Further research could explore ways to improve the robustness and generalizability of the micro-expression recognition model, potentially by incorporating additional modalities or hierarchical attention mechanisms to better capture the subtle and transient nature of micro-expressions.
Conclusion
This paper presents a novel approach to micro-expression recognition that leverages pre-trained motion feature extractors to achieve state-of-the-art performance. The proposed method demonstrates the power of transfer learning and fine-tuning to tackle the challenge of recognizing these brief and subtle facial cues.
The findings of this research have the potential to contribute to advancements in fields such as psychology, security, and human-computer interaction, where the ability to detect and interpret micro-expressions can provide valuable insights into human behavior and emotion. Further exploration of the limitations and potential enhancements of this approach could lead to even more robust and reliable micro-expression recognition systems in the future.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Micro-Expression Recognition by Motion Feature Extraction based on Pre-training
Ruolin Li, Lu Wang, Tingting Yang, Lisheng Xu, Bingyang Ma, Yongchun Li, Hongchao Wei
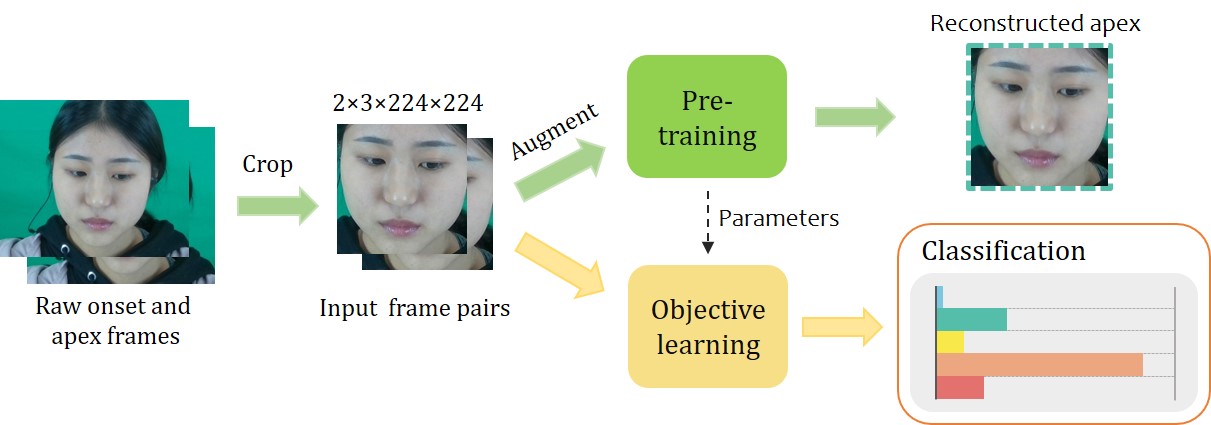
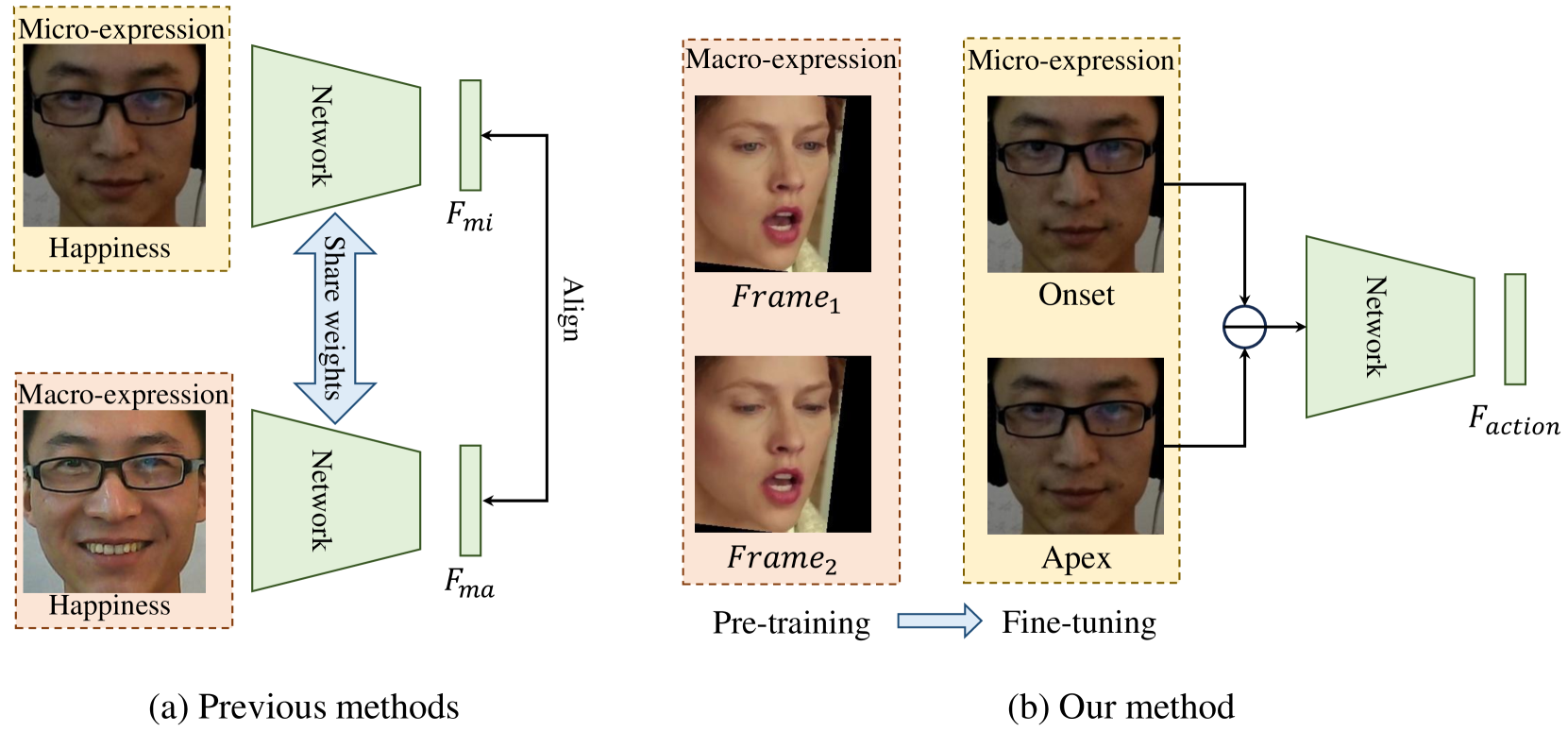
Micro-expressions (MEs) are spontaneous, unconscious facial expressions that have promising applications in various fields such as psychotherapy and national security. Thus, micro-expression recognition (MER) has attracted more and more attention from researchers. Although various MER methods have emerged especially with the development of deep learning techniques, the task still faces several challenges, e.g. subtle motion and limited training data. To address these problems, we propose a novel motion extraction strategy (MoExt) for the MER task and use additional macro-expression data in the pre-training process. We primarily pretrain the feature separator and motion extractor using the contrastive loss, thus enabling them to extract representative motion features. In MoExt, shape features and texture features are first extracted separately from onset and apex frames, and then motion features related to MEs are extracted based on the shape features of both frames. To enable the model to more effectively separate features, we utilize the extracted motion features and the texture features from the onset frame to reconstruct the apex frame. Through pre-training, the module is enabled to extract inter-frame motion features of facial expressions while excluding irrelevant information. The feature separator and motion extractor are ultimately integrated into the MER network, which is then fine-tuned using the target ME data. The effectiveness of proposed method is validated on three commonly used datasets, i.e., CASME II, SMIC, SAMM, and CAS(ME)3 dataset. The results show that our method performs favorably against state-of-the-art methods.
Read more7/11/2024
0
From Macro to Micro: Boosting micro-expression recognition via pre-training on macro-expression videos
Hanting Li, Hongjing Niu, Feng Zhao
Micro-expression recognition (MER) has drawn increasing attention in recent years due to its potential applications in intelligent medical and lie detection. However, the shortage of annotated data has been the major obstacle to further improve deep-learning based MER methods. Intuitively, utilizing sufficient macro-expression data to promote MER performance seems to be a feasible solution. However, the facial patterns of macro-expressions and micro-expressions are significantly different, which makes naive transfer learning methods difficult to deploy directly. To tacle this issue, we propose a generalized transfer learning paradigm, called textbf{MA}cro-expression textbf{TO} textbf{MI}cro-expression (MA2MI). Under our paradigm, networks can learns the ability to represent subtle facial movement by reconstructing future frames. In addition, we also propose a two-branch micro-action network (MIACNet) to decouple facial position features and facial action features, which can help the network more accurately locate facial action locations. Extensive experiments on three popular MER benchmarks demonstrate the superiority of our method.
Read more6/5/2024

0
Meta-Auxiliary Learning for Micro-Expression Recognition
Jingyao Wang, Yunhan Tian, Yuxuan Yang, Xiaoxin Chen, Changwen Zheng, Wenwen Qiang
Micro-expressions (MEs) are involuntary movements revealing people's hidden feelings, which has attracted numerous interests for its objectivity in emotion detection. However, despite its wide applications in various scenarios, micro-expression recognition (MER) remains a challenging problem in real life due to three reasons, including (i) data-level: lack of data and imbalanced classes, (ii) feature-level: subtle, rapid changing, and complex features of MEs, and (iii) decision-making-level: impact of individual differences. To address these issues, we propose a dual-branch meta-auxiliary learning method, called LightmanNet, for fast and robust micro-expression recognition. Specifically, LightmanNet learns general MER knowledge from limited data through a dual-branch bi-level optimization process: (i) In the first level, it obtains task-specific MER knowledge by learning in two branches, where the first branch is for learning MER features via primary MER tasks, while the other branch is for guiding the model obtain discriminative features via auxiliary tasks, i.e., image alignment between micro-expressions and macro-expressions since their resemblance in both spatial and temporal behavioral patterns. The two branches of learning jointly constrain the model of learning meaningful task-specific MER knowledge while avoiding learning noise or superficial connections between MEs and emotions that may damage its generalization ability. (ii) In the second level, LightmanNet further refines the learned task-specific knowledge, improving model generalization and efficiency. Extensive experiments on various benchmark datasets demonstrate the superior robustness and efficiency of LightmanNet.
Read more4/19/2024

0
Micro-expression recognition based on depth map to point cloud
Ren Zhang, Jianqin Yin, Chao Qi, Zehao Wang, Zhicheng Zhang, Yonghao Dang
Micro-expressions are nonverbal facial expressions that reveal the covert emotions of individuals, making the micro-expression recognition task receive widespread attention. However, the micro-expression recognition task is challenging due to the subtle facial motion and brevity in duration. Many 2D image-based methods have been developed in recent years to recognize MEs effectively, but, these approaches are restricted by facial texture information and are susceptible to environmental factors, such as lighting. Conversely, depth information can effectively represent motion information related to facial structure changes and is not affected by lighting. Motion information derived from facial structures can describe motion features that pixel textures cannot delineate. We proposed a network for micro-expression recognition based on facial depth information, and our experiments have demonstrated the crucial role of depth maps in the micro-expression recognition task. Initially, we transform the depth map into a point cloud and obtain the motion information for each point by aligning the initiating frame with the apex frame and performing a differential operation. Subsequently, we adjusted all point cloud motion feature input dimensions and used them as inputs for multiple point cloud networks to assess the efficacy of this representation. PointNet++ was chosen as the ultimate outcome for micro-expression recognition due to its superior performance. Our experiments show that our proposed method significantly outperforms the existing deep learning methods, including the baseline, on the $CAS(ME)^3$ dataset, which includes depth information.
Read more6/13/2024