Hierarchical Space-Time Attention for Micro-Expression Recognition

0

Sign in to get full access
Overview
- This paper introduces a novel hierarchical space-time attention mechanism for micro-expression recognition, a challenging task in computer vision.
- Micro-expressions are brief, involuntary facial movements that can reveal hidden emotions, and their accurate detection has important applications in fields like psychology and security.
- The proposed approach learns to effectively capture the spatial and temporal dynamics of micro-expressions, outperforming state-of-the-art methods on several benchmarks.
Plain English Explanation
Micro-expressions are very quick, almost imperceptible changes in a person's facial features that can reveal their true emotions, even if they are trying to hide them. Detecting micro-expressions accurately is important for applications like psychology and security. However, this is a difficult task because the changes happen so fast.
The researchers in this paper developed a new deep learning model that is better able to recognize micro-expressions by focusing on both the spatial (location) and temporal (time) aspects of the facial movements. Their "hierarchical space-time attention" mechanism allows the model to learn which parts of the face and which moments in time are most important for detecting micro-expressions.
This approach outperformed previous state-of-the-art methods on several standard datasets for micro-expression recognition. The model was able to more reliably pick up on the subtle facial cues that reveal a person's underlying emotions, even when they are trying to conceal them.
Technical Explanation
The core of the proposed approach is a hierarchical space-time attention mechanism that learns to focus on the most informative spatial regions and temporal segments for micro-expression recognition.
The model first encodes the input video frames using a 3D convolutional neural network. It then applies spatial attention to each frame to identify the key facial regions, and temporal attention to select the most discriminative time steps. These attention weights are learned in a hierarchical manner, with separate modules for the spatial and temporal dimensions.
The spatiotemporal features extracted by the attention modules are then fused and passed through a classification head to predict the micro-expression category. The entire model is trained end-to-end using a cross-entropy loss.
Experiments on several micro-expression datasets, including CASME II and SAMM, demonstrate the effectiveness of the proposed approach. It outperforms previous state-of-the-art methods that relied on hand-crafted features or simpler attention mechanisms. The hierarchical space-time attention allows the model to focus on the most relevant facial regions and temporal segments, leading to more accurate micro-expression recognition.
Critical Analysis
The paper provides a strong technical contribution to the field of micro-expression recognition. The hierarchical attention mechanism is a novel and well-designed approach that appears to capture the spatiotemporal complexities of micro-expressions effectively.
However, the authors do not discuss certain limitations of their work. For example, the model was only evaluated on posed micro-expression datasets, which may not fully reflect the challenges of recognizing micro-expressions in real-world scenarios. Further research is needed to test the approach's performance on more naturalistic data.
Additionally, the paper does not provide much insight into the interpretability of the learned attention weights. Understanding which facial regions and time points the model focuses on could yield valuable psychological insights, but this analysis is not included.
Overall, the proposed hierarchical space-time attention mechanism is a significant advancement in micro-expression recognition, but there are still avenues for further research and development to address the remaining challenges in this important computer vision task.
Conclusion
This paper introduces a novel hierarchical space-time attention approach for micro-expression recognition, a challenging problem in computer vision with important applications. The model is able to outperform previous state-of-the-art methods by effectively capturing the spatial and temporal dynamics of micro-expressions.
The hierarchical attention mechanism allows the model to focus on the most informative facial regions and time points for accurate micro-expression detection. This advancement could lead to improved applications in psychology, security, and other fields that rely on understanding subtle emotional cues.
While the paper presents a strong technical contribution, further research is needed to address the remaining limitations, such as evaluating the model's performance on more naturalistic data and providing better interpretability of the learned attention weights. Overall, this work represents an important step forward in the quest to build more robust and insightful micro-expression recognition systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hierarchical Space-Time Attention for Micro-Expression Recognition
Haihong Hao, Shuo Wang, Huixia Ben, Yanbin Hao, Yansong Wang, Weiwei Wang
Micro-expression recognition (MER) aims to recognize the short and subtle facial movements from the Micro-expression (ME) video clips, which reveal real emotions. Recent MER methods mostly only utilize special frames from ME video clips or extract optical flow from these special frames. However, they neglect the relationship between movements and space-time, while facial cues are hidden within these relationships. To solve this issue, we propose the Hierarchical Space-Time Attention (HSTA). Specifically, we first process ME video frames and special frames or data parallelly by our cascaded Unimodal Space-Time Attention (USTA) to establish connections between subtle facial movements and specific facial areas. Then, we design Crossmodal Space-Time Attention (CSTA) to achieve a higher-quality fusion for crossmodal data. Finally, we hierarchically integrate USTA and CSTA to grasp the deeper facial cues. Our model emphasizes temporal modeling without neglecting the processing of special data, and it fuses the contents in different modalities while maintaining their respective uniqueness. Extensive experiments on the four benchmarks show the effectiveness of our proposed HSTA. Specifically, compared with the latest method on the CASME3 dataset, it achieves about 3% score improvement in seven-category classification.
Read more5/7/2024
0
Micro-Expression Recognition by Motion Feature Extraction based on Pre-training
Ruolin Li, Lu Wang, Tingting Yang, Lisheng Xu, Bingyang Ma, Yongchun Li, Hongchao Wei
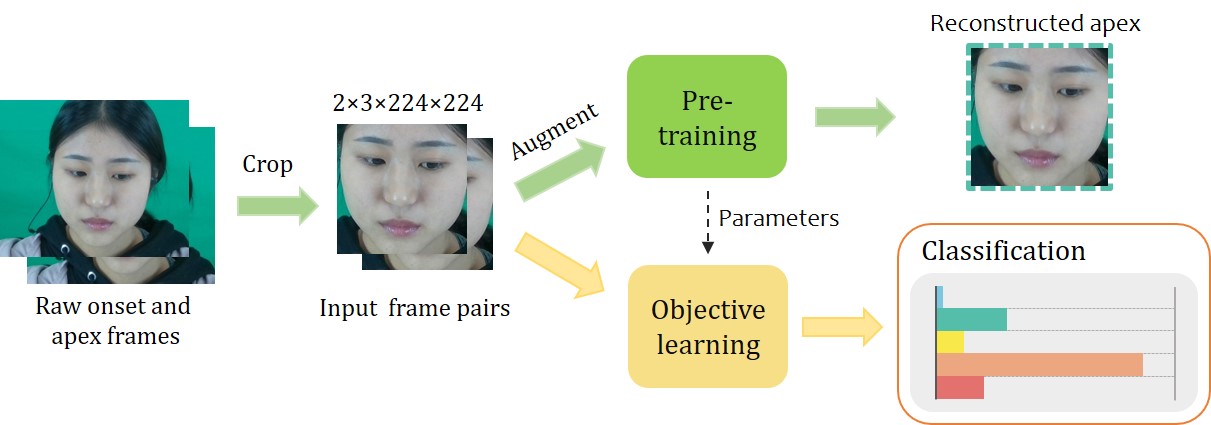
Micro-expressions (MEs) are spontaneous, unconscious facial expressions that have promising applications in various fields such as psychotherapy and national security. Thus, micro-expression recognition (MER) has attracted more and more attention from researchers. Although various MER methods have emerged especially with the development of deep learning techniques, the task still faces several challenges, e.g. subtle motion and limited training data. To address these problems, we propose a novel motion extraction strategy (MoExt) for the MER task and use additional macro-expression data in the pre-training process. We primarily pretrain the feature separator and motion extractor using the contrastive loss, thus enabling them to extract representative motion features. In MoExt, shape features and texture features are first extracted separately from onset and apex frames, and then motion features related to MEs are extracted based on the shape features of both frames. To enable the model to more effectively separate features, we utilize the extracted motion features and the texture features from the onset frame to reconstruct the apex frame. Through pre-training, the module is enabled to extract inter-frame motion features of facial expressions while excluding irrelevant information. The feature separator and motion extractor are ultimately integrated into the MER network, which is then fine-tuned using the target ME data. The effectiveness of proposed method is validated on three commonly used datasets, i.e., CASME II, SMIC, SAMM, and CAS(ME)3 dataset. The results show that our method performs favorably against state-of-the-art methods.
Read more7/11/2024

0
New!Synergistic Spotting and Recognition of Micro-Expression via Temporal State Transition
Bochao Zou, Zizheng Guo, Wenfeng Qin, Xin Li, Kangsheng Wang, Huimin Ma
Micro-expressions are involuntary facial movements that cannot be consciously controlled, conveying subtle cues with substantial real-world applications. The analysis of micro-expressions generally involves two main tasks: spotting micro-expression intervals in long videos and recognizing the emotions associated with these intervals. Previous deep learning methods have primarily relied on classification networks utilizing sliding windows. However, fixed window sizes and window-level hard classification introduce numerous constraints. Additionally, these methods have not fully exploited the potential of complementary pathways for spotting and recognition. In this paper, we present a novel temporal state transition architecture grounded in the state space model, which replaces conventional window-level classification with video-level regression. Furthermore, by leveraging the inherent connections between spotting and recognition tasks, we propose a synergistic strategy that enhances overall analysis performance. Extensive experiments demonstrate that our method achieves state-of-the-art performance. The codes and pre-trained models are available at https://github.com/zizheng-guo/ME-TST.
Read more9/17/2024

0
Three-Stream Temporal-Shift Attention Network Based on Self-Knowledge Distillation for Micro-Expression Recognition
Guanghao Zhu, Lin Liu, Yuhao Hu, Haixin Sun, Fang Liu, Xiaohui Du, Ruqian Hao, Juanxiu Liu, Yong Liu, Hao Deng, Jing Zhang
Micro-expressions are subtle facial movements that occur spontaneously when people try to conceal real emotions. Micro-expression recognition is crucial in many fields, including criminal analysis and psychotherapy. However, micro-expression recognition is challenging since micro-expressions have low intensity and public datasets are small in size. To this end, a three-stream temporal-shift attention network based on self-knowledge distillation called SKD-TSTSAN is proposed in this paper. Firstly, to address the low intensity of muscle movements, we utilize learning-based motion magnification modules to enhance the intensity of muscle movements. Secondly, we employ efficient channel attention modules in the local-spatial stream to make the network focus on facial regions that are highly relevant to micro-expressions. In addition, temporal shift modules are used in the dynamic-temporal stream, which enables temporal modeling with no additional parameters by mixing motion information from two different temporal domains. Furthermore, we introduce self-knowledge distillation into the micro-expression recognition task by introducing auxiliary classifiers and using the deepest section of the network for supervision, encouraging all blocks to fully explore the features of the training set. Finally, extensive experiments are conducted on four public datasets: CASME II, SAMM, MMEW, and CAS(ME)3. The experimental results demonstrate that our SKD-TSTSAN outperforms other existing methods and achieves new state-of-the-art performance. Our code will be available at https://github.com/GuanghaoZhu663/SKD-TSTSAN.
Read more7/30/2024